

A Review on Automatic Facial Expression Recognition Systems Assisted by Multimodal Sensor Data
- PMID: 31003522
- PMCID: PMC6514576
- DOI: 10.3390/s19081863
A Review on Automatic Facial Expression Recognition Systems Assisted by Multimodal Sensor Data
Abstract
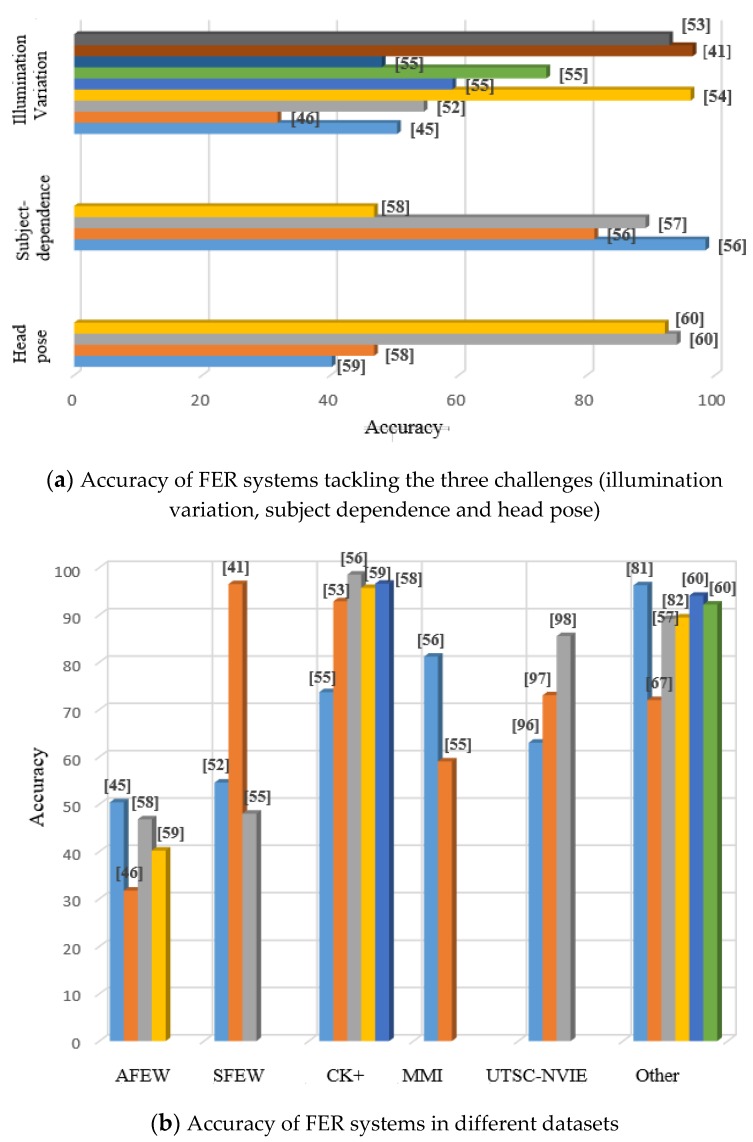
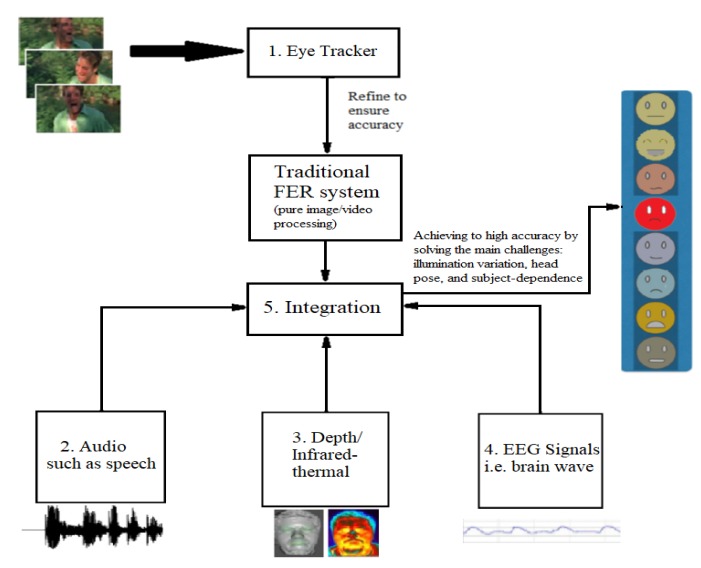
Facial Expression Recognition (FER) can be widely applied to various research areas, such as mental diseases diagnosis and human social/physiological interaction detection. With the emerging advanced technologies in hardware and sensors, FER systems have been developed to support real-world application scenes, instead of laboratory environments. Although the laboratory-controlled FER systems achieve very high accuracy, around 97%, the technical transferring from the laboratory to real-world applications faces a great barrier of very low accuracy, approximately 50%. In this survey, we comprehensively discuss three significant challenges in the unconstrained real-world environments, such as illumination variation, head pose, and subject-dependence, which may not be resolved by only analysing images/videos in the FER system. We focus on those sensors that may provide extra information and help the FER systems to detect emotion in both static images and video sequences. We introduce three categories of sensors that may help improve the accuracy and reliability of an expression recognition system by tackling the challenges mentioned above in pure image/video processing. The first group is detailed-face sensors, which detect a small dynamic change of a face component, such as eye-trackers, which may help differentiate the background noise and the feature of faces. The second is non-visual sensors, such as audio, depth, and EEG sensors, which provide extra information in addition to visual dimension and improve the recognition reliability for example in illumination variation and position shift situation. The last is target-focused sensors, such as infrared thermal sensors, which can facilitate the FER systems to filter useless visual contents and may help resist illumination variation. Also, we discuss the methods of fusing different inputs obtained from multimodal sensors in an emotion system. We comparatively review the most prominent multimodal emotional expression recognition approaches and point out their advantages and limitations. We briefly introduce the benchmark data sets related to FER systems for each category of sensors and extend our survey to the open challenges and issues. Meanwhile, we design a framework of an expression recognition system, which uses multimodal sensor data (provided by the three categories of sensors) to provide complete information about emotions to assist the pure face image/video analysis. We theoretically analyse the feasibility and achievability of our new expression recognition system, especially for the use in the wild environment, and point out the future directions to design an efficient, emotional expression recognition system.
Keywords: emotional expression recognition; facial expression recognition (FER); multimodal sensor data; real-world conditions; spontaneous expression.
Conflict of interest statement
The authors declare no conflict of interest.
Figures
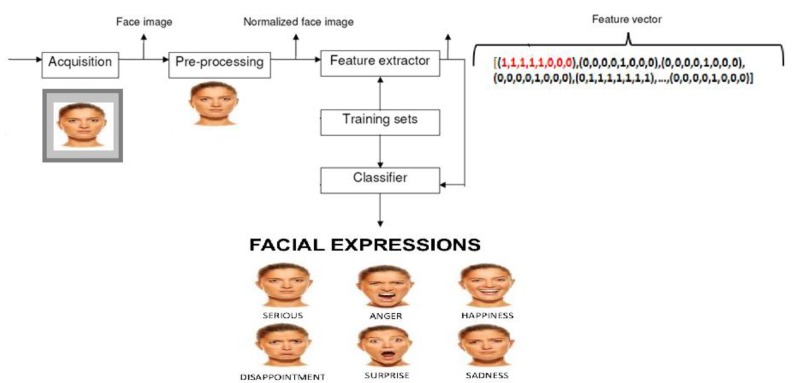

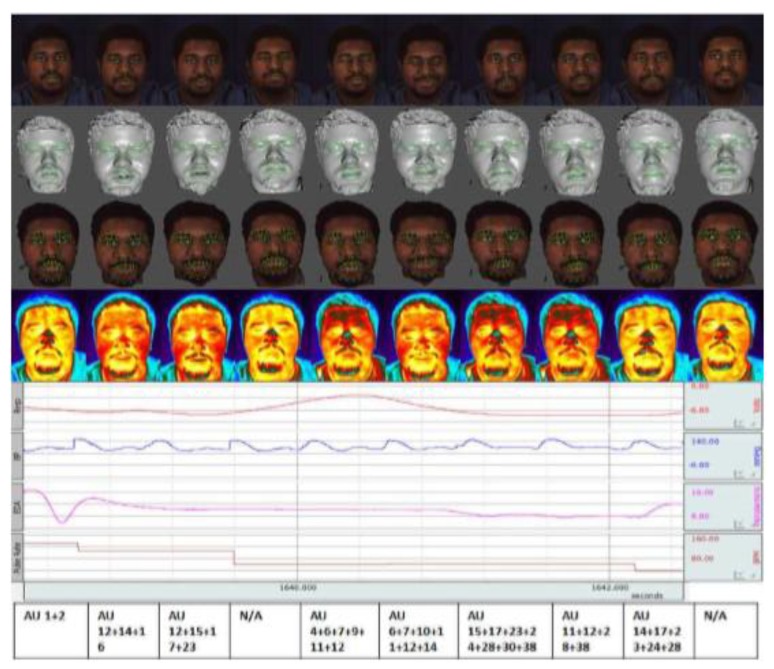
References
-
- Cowie R., Douglas-Cowie E., Tsapatsoulis N., Votsis G., Kollias S., Fellenz W., Taylor J.G. Emotional expression recognition in human–computer interaction. IEEE Signal Process. Mag. 2001;18:32–80. doi: 10.1109/79.911197. - DOI
-
- Zhang Z., Luo P., Loy C.-C., Tang X. Learning social relation traits from face images; Proceedings of the IEEE International Conference on Computer Vision; Santiago, Chile. 13–16 December 2015; pp. 3631–3639.
-
- Baxter P., Trafton J.G. Cognitive architectures for human–robot interaction; Proceedings of the 2014 ACM/IEEE International Conference on Human–Robot Interaction; Bielefeld, Germany. 3–6 March 2016; pp. 504–505.
-
- Tadeusz S. Application of vision information to planning trajectories of Adept Six-300 robot; Proceedings of the International Conference on Advanced Robotics and Mechatronics (ICARM); Miedzyzdroje, Poland. 29 August–1 September 2016; pp. 88–94.
-
- Mehrabian A. Communication without words. IOJT. 2008:193–200.
Publication types
MeSH terms
LinkOut - more resources
Full Text Sources
Other Literature Sources
