

Speech synthesis from neural decoding of spoken sentences
- PMID: 31019317
- PMCID: PMC9714519
- DOI: 10.1038/s41586-019-1119-1
Speech synthesis from neural decoding of spoken sentences
Abstract
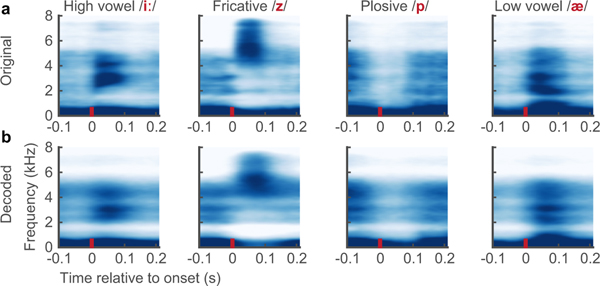
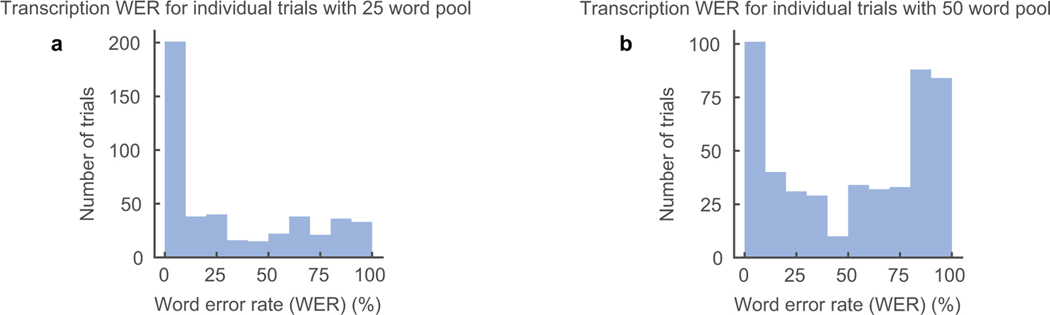
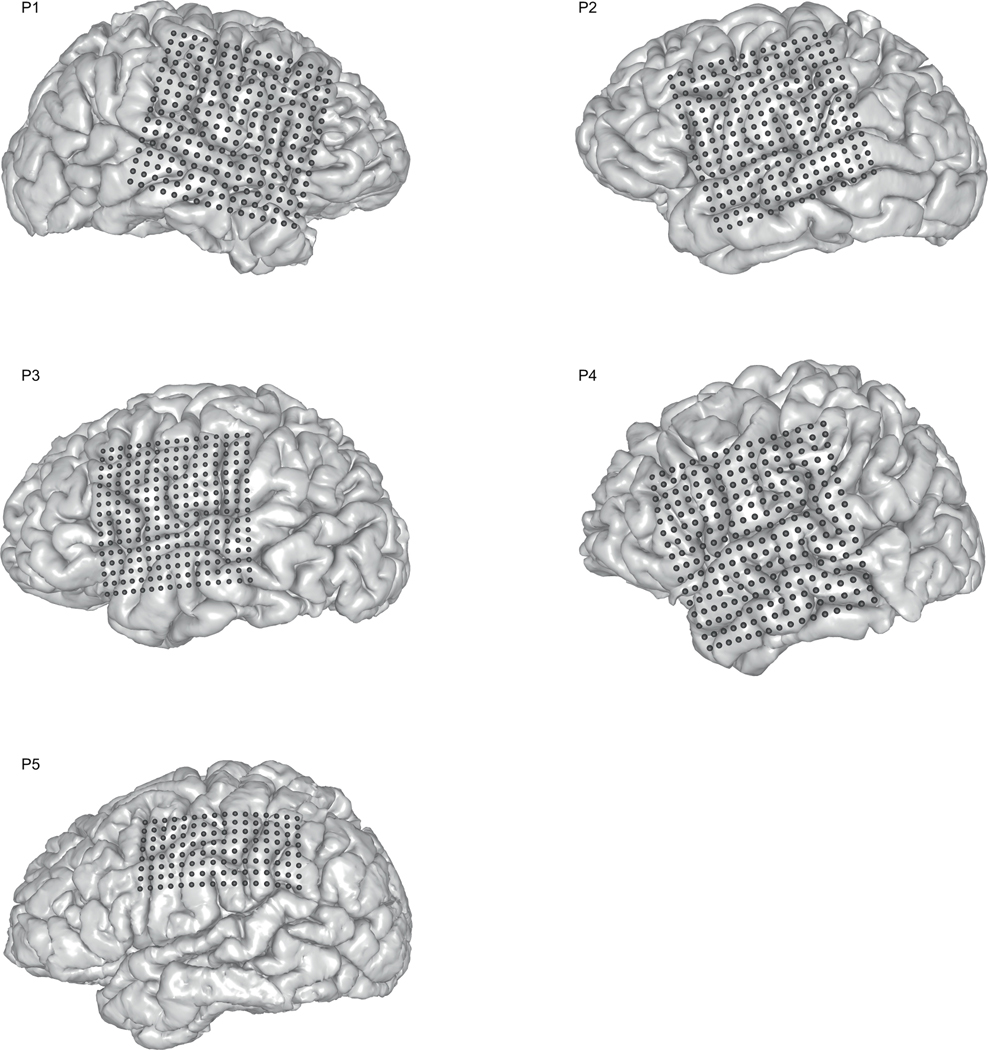
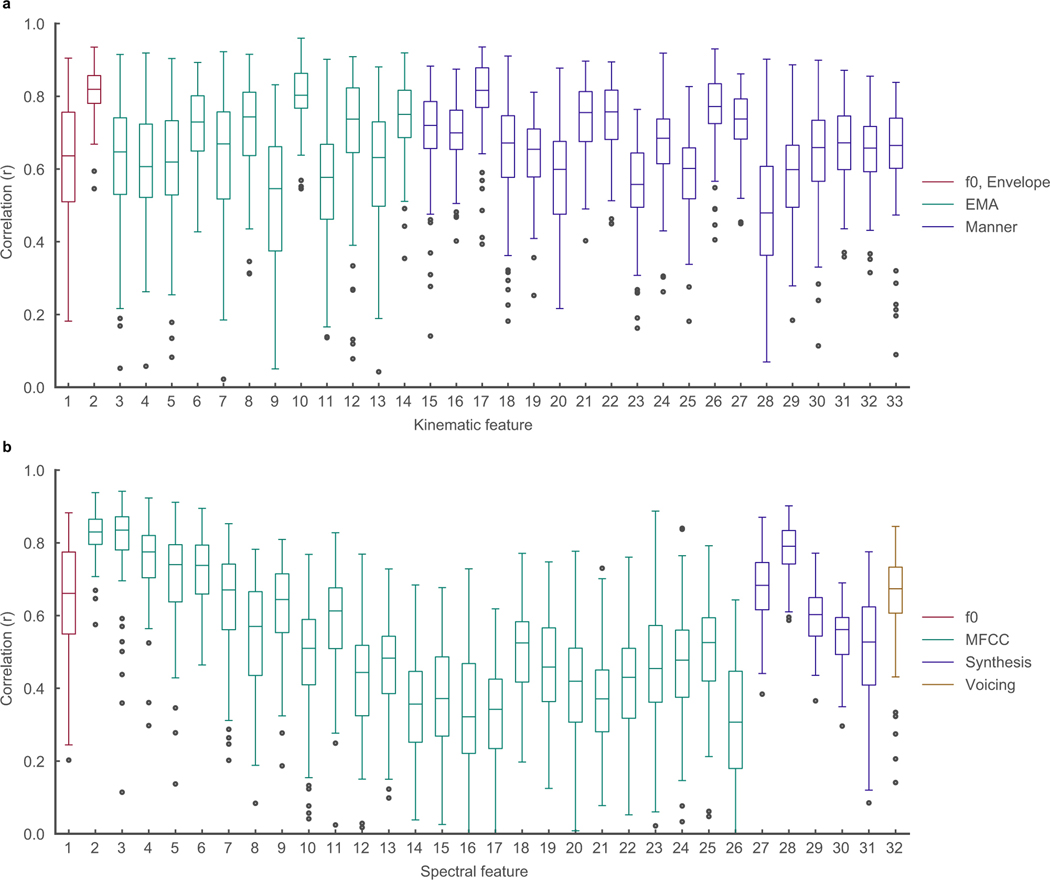
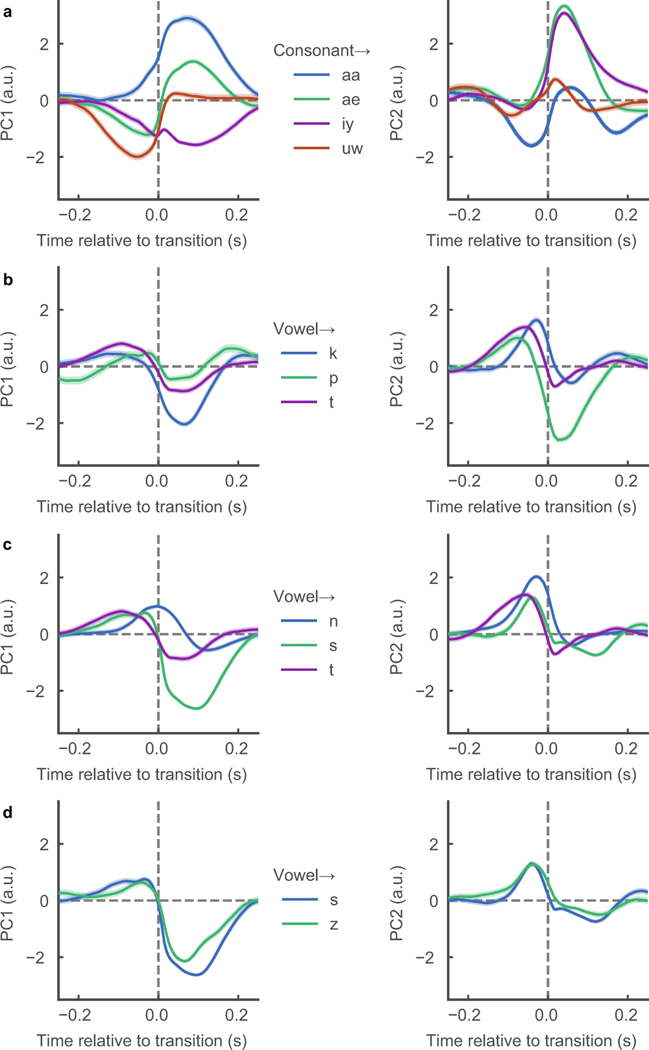
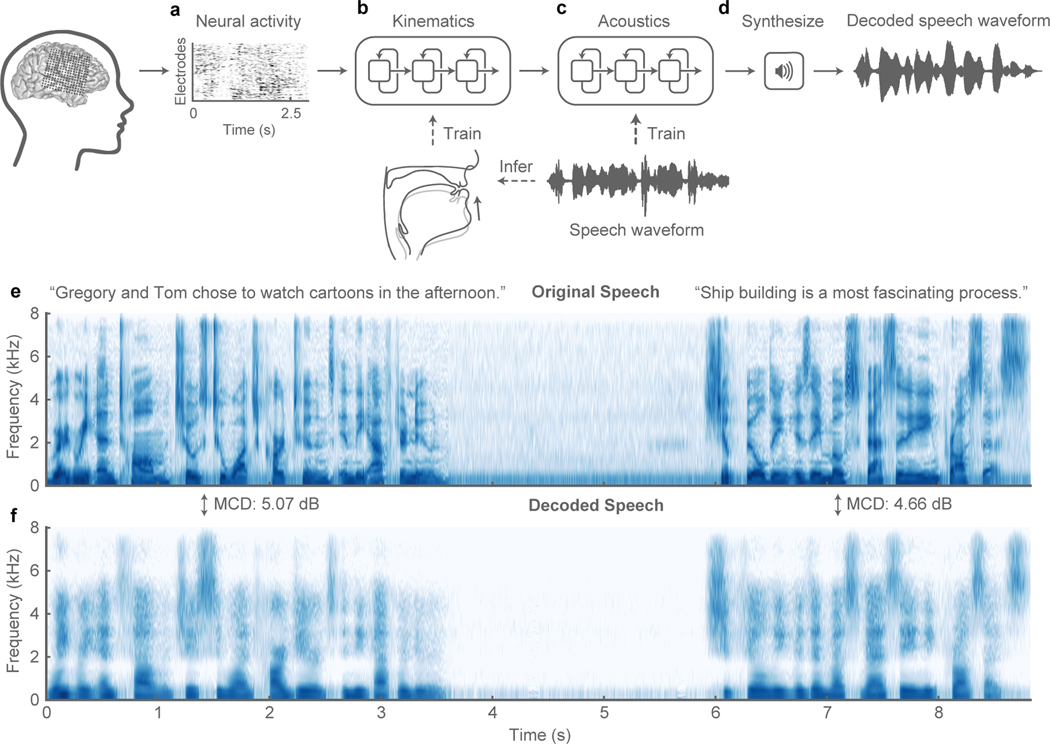
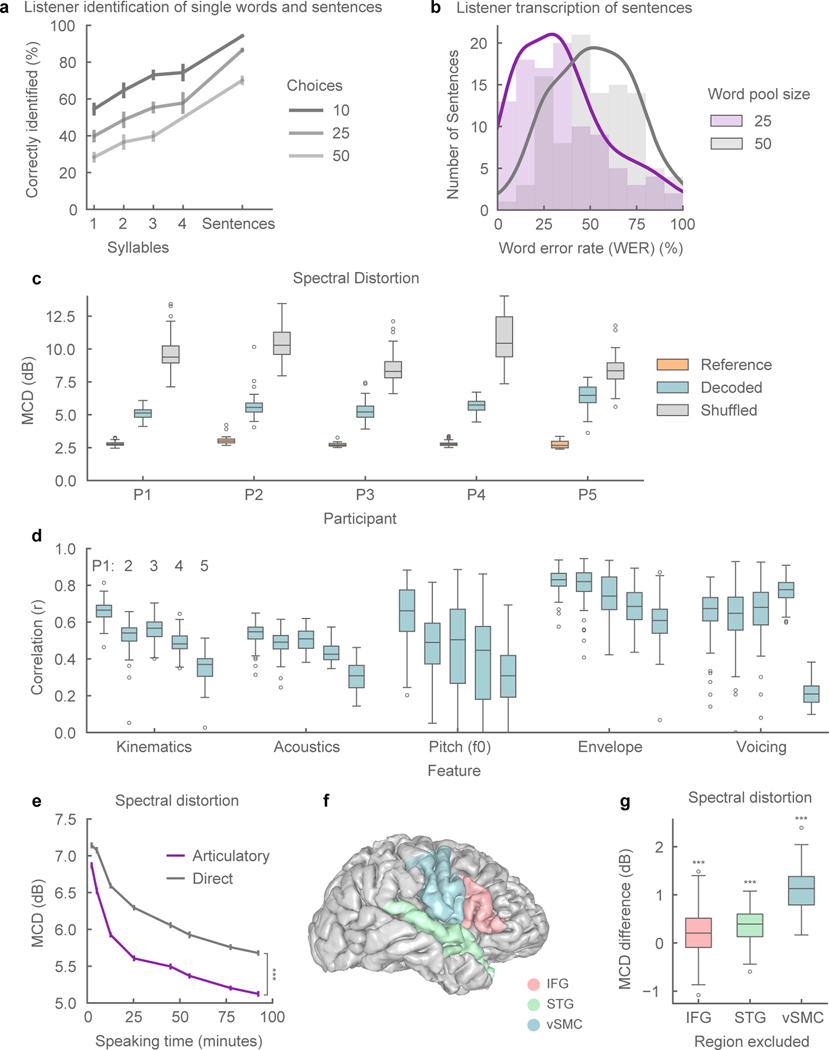
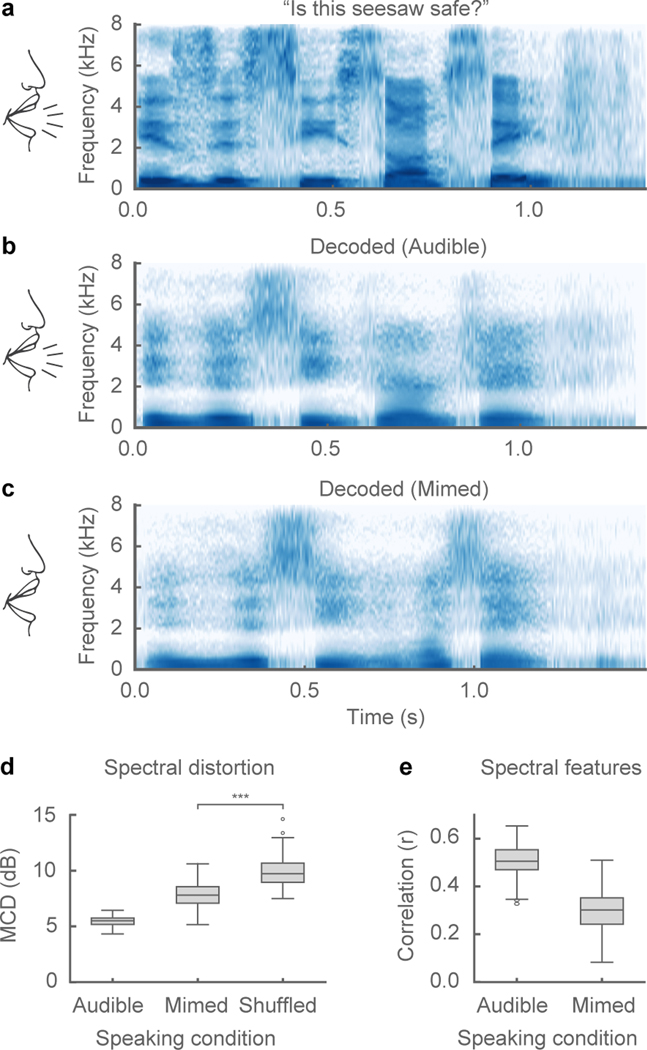
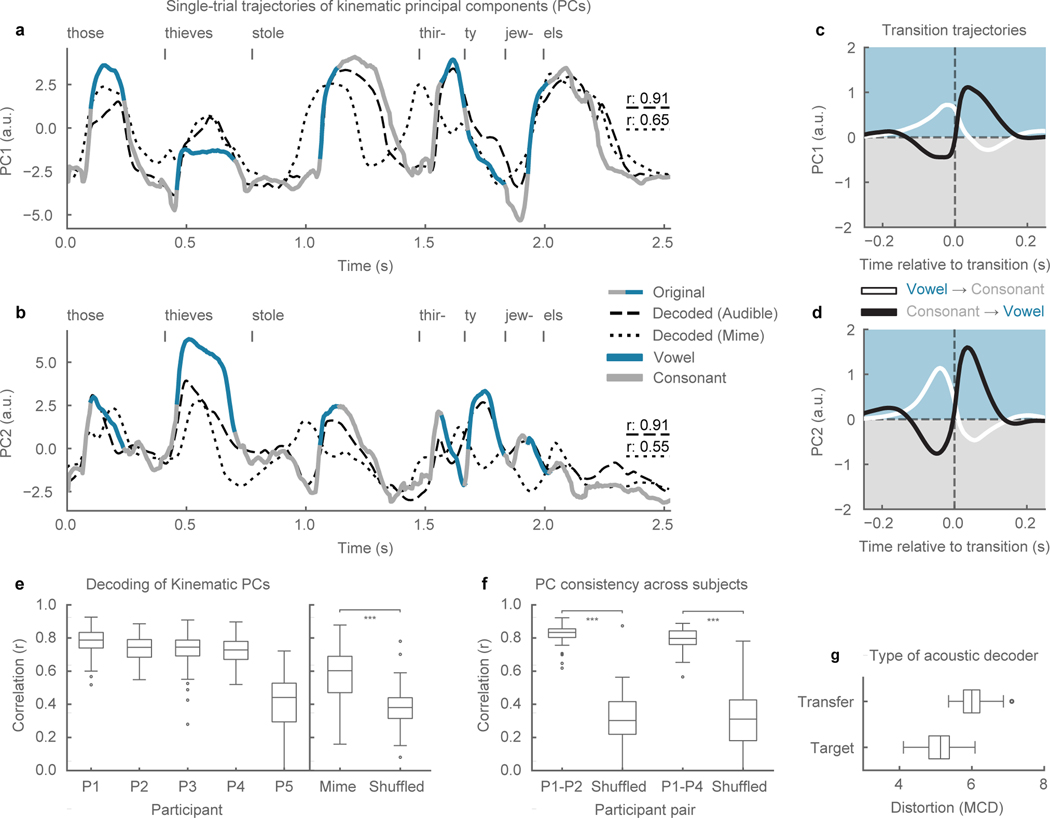
Technology that translates neural activity into speech would be transformative for people who are unable to communicate as a result of neurological impairments. Decoding speech from neural activity is challenging because speaking requires very precise and rapid multi-dimensional control of vocal tract articulators. Here we designed a neural decoder that explicitly leverages kinematic and sound representations encoded in human cortical activity to synthesize audible speech. Recurrent neural networks first decoded directly recorded cortical activity into representations of articulatory movement, and then transformed these representations into speech acoustics. In closed vocabulary tests, listeners could readily identify and transcribe speech synthesized from cortical activity. Intermediate articulatory dynamics enhanced performance even with limited data. Decoded articulatory representations were highly conserved across speakers, enabling a component of the decoder to be transferrable across participants. Furthermore, the decoder could synthesize speech when a participant silently mimed sentences. These findings advance the clinical viability of using speech neuroprosthetic technology to restore spoken communication.
Conflict of interest statement
The authors declare no competing interests.
Figures
Comment in
-
Brain implants that let you speak your mind.Nature. 2019 Apr;568(7753):466-467. doi: 10.1038/d41586-019-01181-y. Nature. 2019. PMID: 31019323 No abstract available.
-
Translating thoughts into speech.Nat Med. 2019 Jun;25(6):877. doi: 10.1038/s41591-019-0488-1. Nat Med. 2019. PMID: 31171874 No abstract available.
References
MeSH terms
Grants and funding
LinkOut - more resources
Full Text Sources
Other Literature Sources
