

Meaning-based guidance of attention in scenes as revealed by meaning maps
- PMID: 31024101
- PMCID: PMC7455012
- DOI: 10.1038/s41562-017-0208-0
Meaning-based guidance of attention in scenes as revealed by meaning maps
Abstract
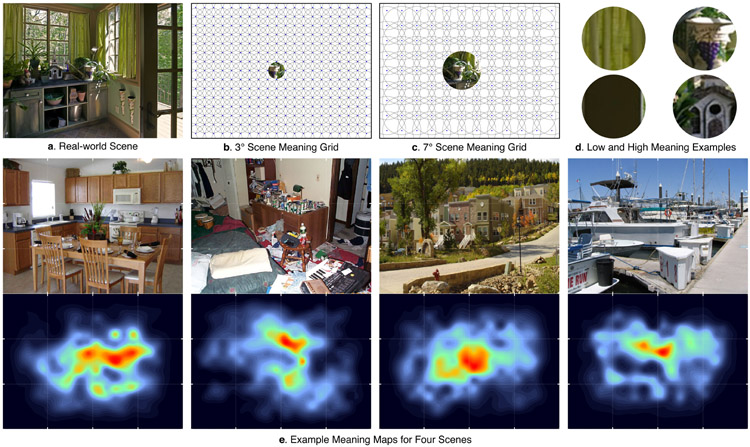
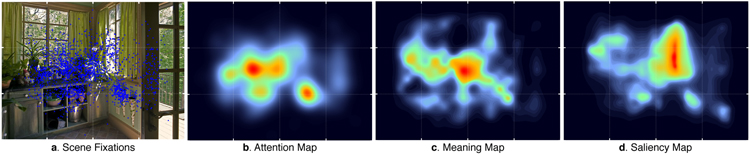
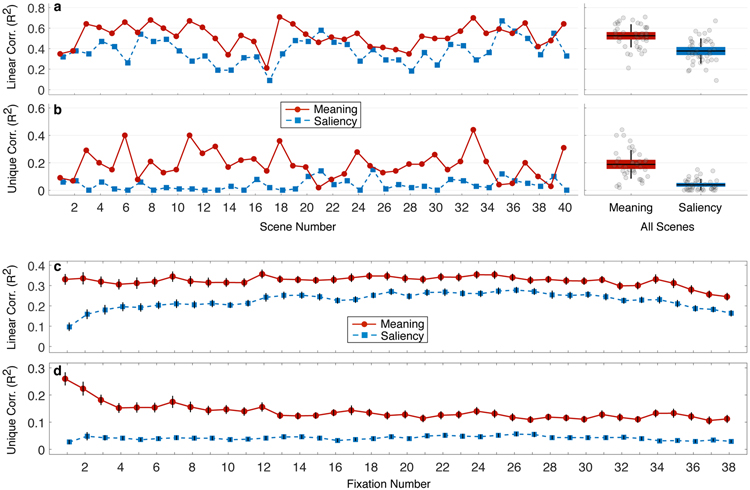
Real-world scenes comprise a blooming, buzzing confusion of information. To manage this complexity, visual attention is guided to important scene regions in real time 1-7 . What factors guide attention within scenes? A leading theoretical position suggests that visual salience based on semantically uninterpreted image features plays the critical causal role in attentional guidance, with knowledge and meaning playing a secondary or modulatory role 8-11 . Here we propose instead that meaning plays the dominant role in guiding human attention through scenes. To test this proposal, we developed 'meaning maps' that represent the semantic richness of scene regions in a format that can be directly compared to image salience. We then contrasted the degree to which the spatial distributions of meaning and salience predict viewers' overt attention within scenes. The results showed that both meaning and salience predicted the distribution of attention, but that when the relationship between meaning and salience was controlled, only meaning accounted for unique variance in attention. This pattern of results was apparent from the very earliest time-point in scene viewing. We conclude that meaning is the driving force guiding attention through real-world scenes.
Conflict of interest statement
Competing Interests
The authors declare no competing interests.
Figures

References
-
- Land MF & Hayhoe MM In what ways do eye movements contribute to everyday activities? Vision Res. 41, 3559–3565 (2001). - PubMed
-
- Hayhoe MM & Ballard D Eye movements in natural behavior. Trends Cogn. Sci 9, 188–194 (2005). - PubMed
-
- Henderson JM Human gaze control during real-world scene perception. Trends Cogn. Sci 7, 498–504 (2003). - PubMed
-
- Henderson JM Gaze Control as Prediction. Trends Cogn. Sci 21, 15–23 (2017). - PubMed
-
- Buswell GT How People Look at Pictures. (University of Chicago Press Chicago, 1935). at <papers2://publication/uuid/EA9683B1–9AB3–46F7-B4C3–1EBE6E3D645D>
