

Mice can learn phonetic categories
- PMID: 31067917
- PMCID: PMC6910010
- DOI: 10.1121/1.5091776
Mice can learn phonetic categories
Abstract
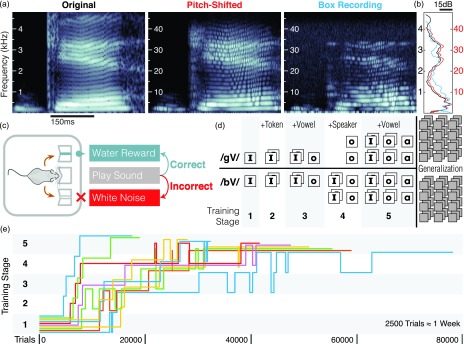
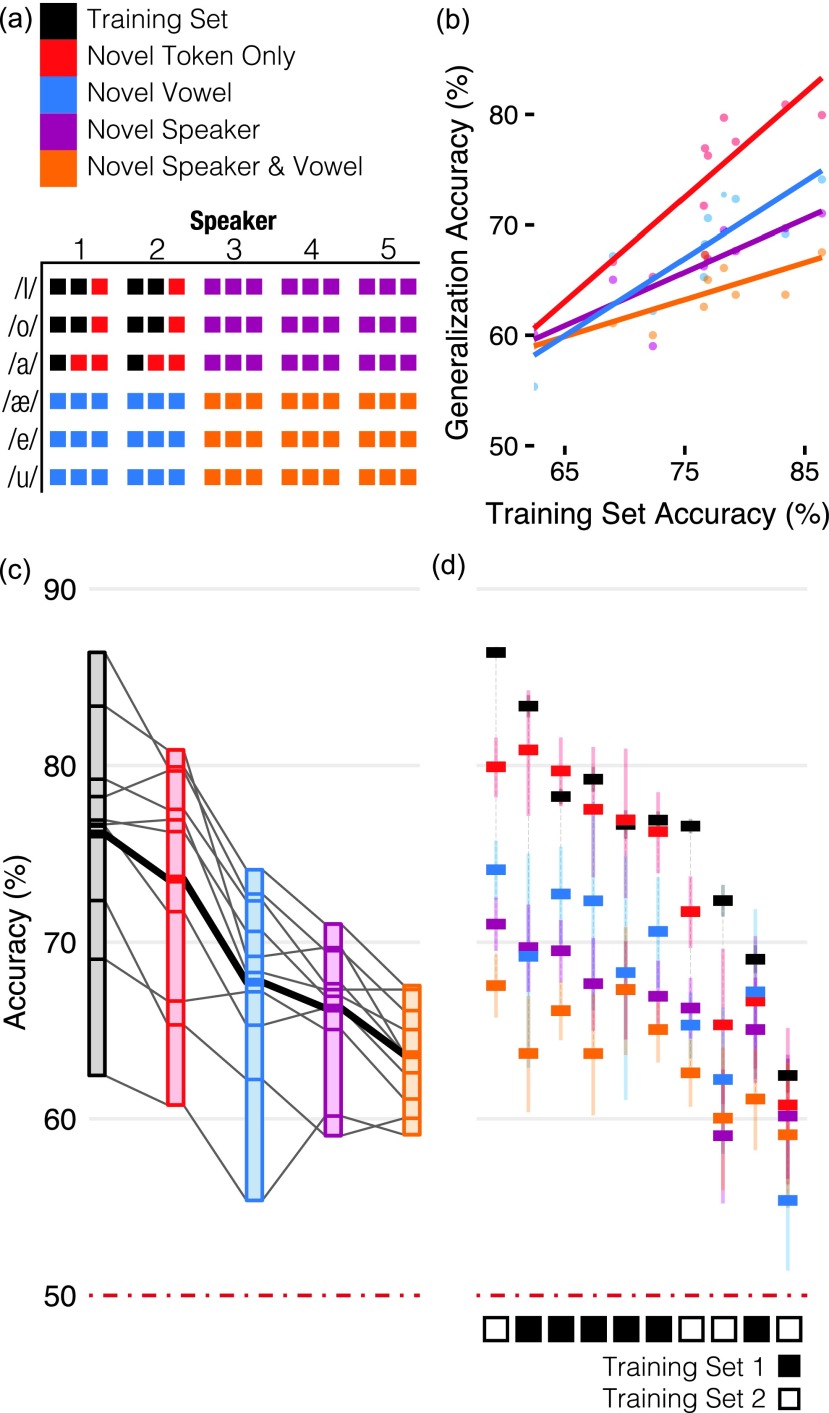
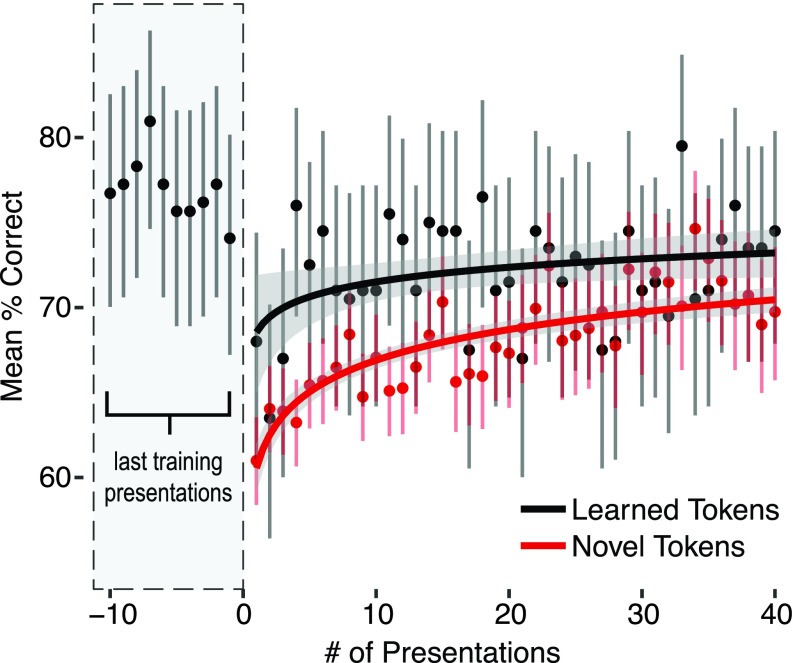
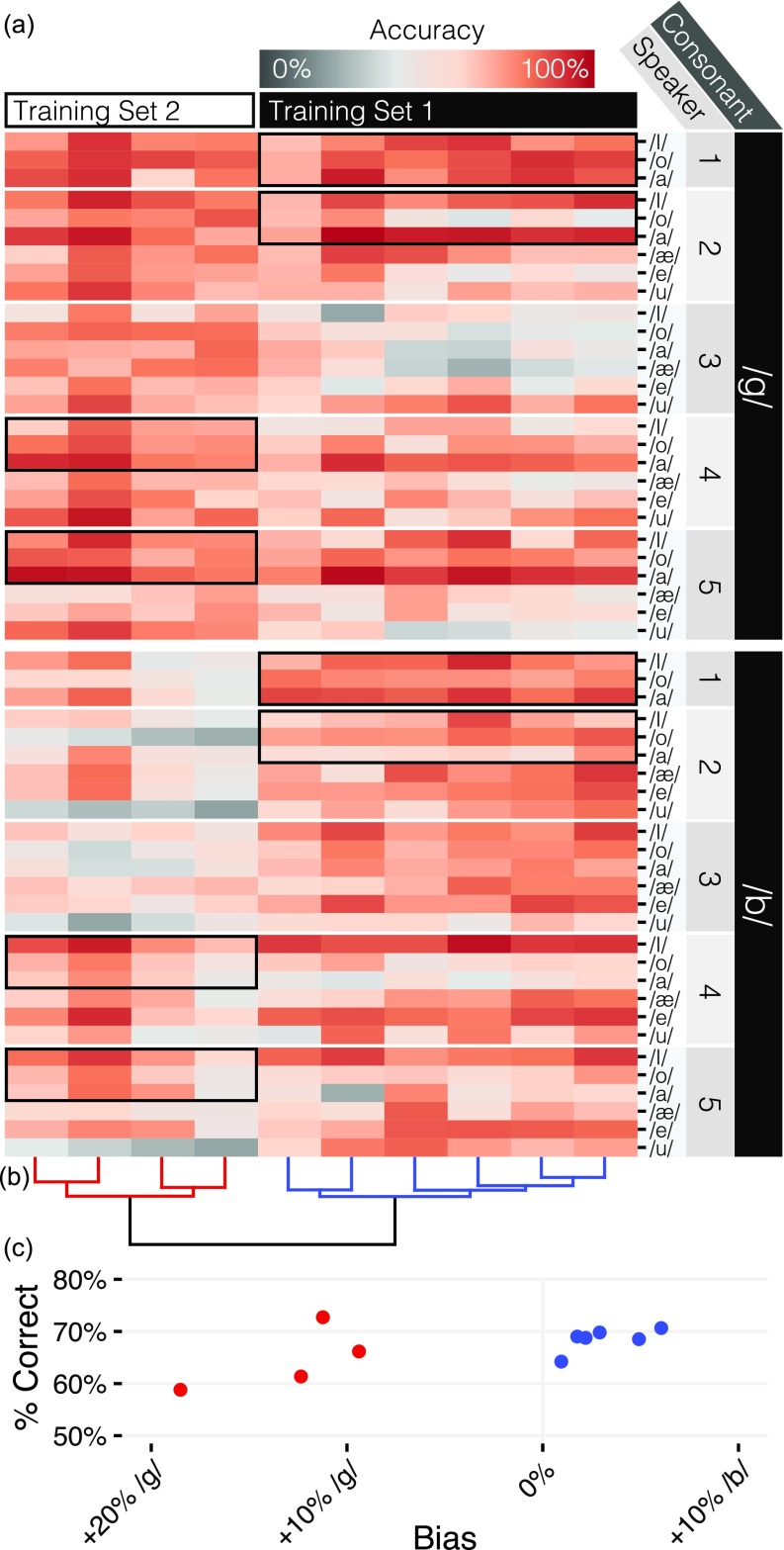
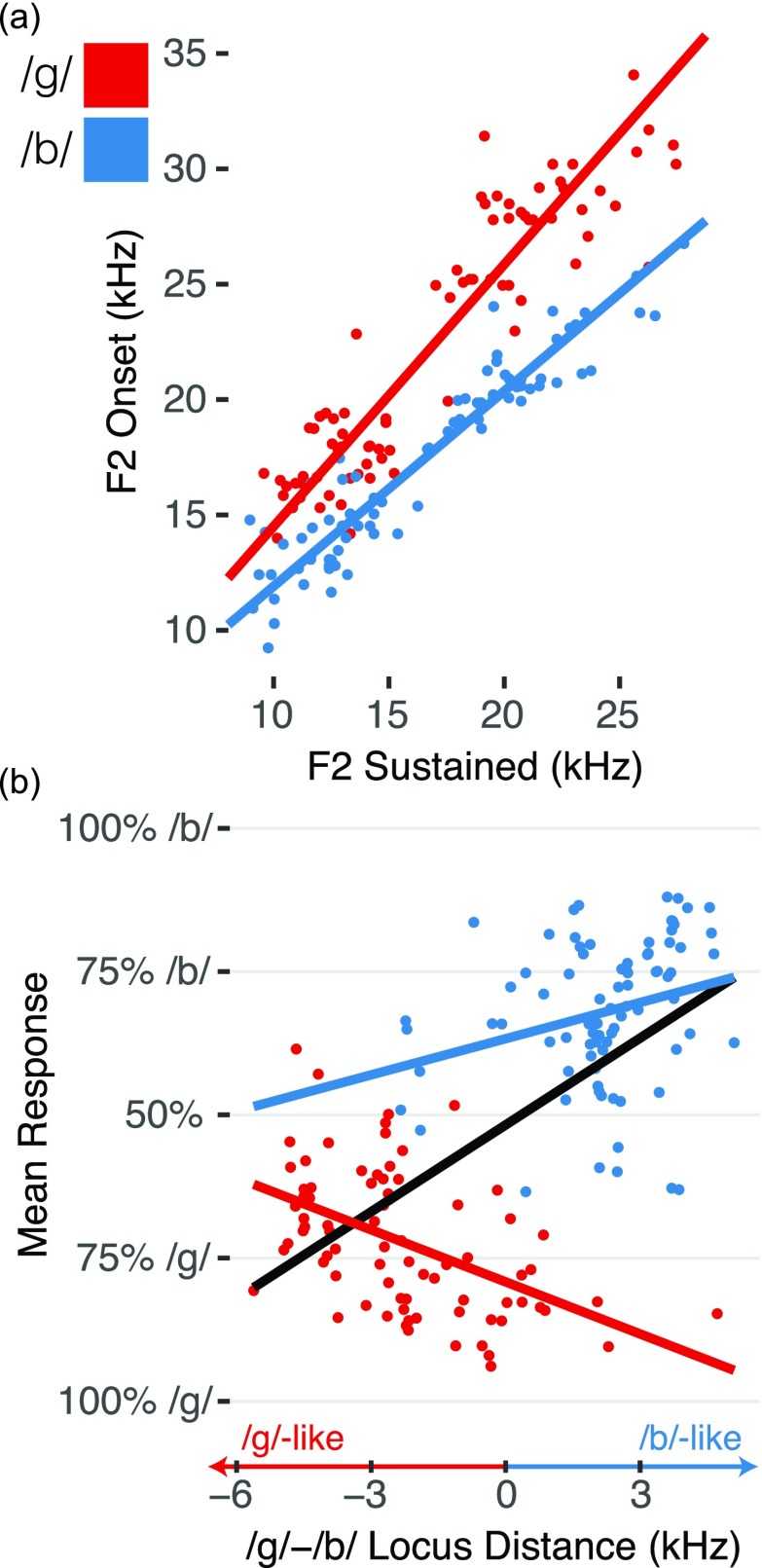
Speech is perceived as a series of relatively invariant phonemes despite extreme variability in the acoustic signal. To be perceived as nearly-identical phonemes, speech sounds that vary continuously over a range of acoustic parameters must be perceptually discretized by the auditory system. Such many-to-one mappings of undifferentiated sensory information to a finite number of discrete categories are ubiquitous in perception. Although many mechanistic models of phonetic perception have been proposed, they remain largely unconstrained by neurobiological data. Current human neurophysiological methods lack the necessary spatiotemporal resolution to provide it: speech is too fast, and the neural circuitry involved is too small. This study demonstrates that mice are capable of learning generalizable phonetic categories, and can thus serve as a model for phonetic perception. Mice learned to discriminate consonants and generalized consonant identity across novel vowel contexts and speakers, consistent with true category learning. A mouse model, given the powerful genetic and electrophysiological tools for probing neural circuits available for them, has the potential to powerfully augment a mechanistic understanding of phonetic perception.
Figures
References
-
- Sussman H. M., Fruchter D., Hilbert J., and Sirosh J., “ Linear correlates in the speech signal: the orderly output constraint,” Behav. Brain Sci. 21(2), 241–259; discussion 260-99 (1998). - PubMed
Publication types
Grants and funding
LinkOut - more resources
Full Text Sources