

Extrafoveal attentional capture by object semantics
- PMID: 31120948
- PMCID: PMC6532879
- DOI: 10.1371/journal.pone.0217051
Extrafoveal attentional capture by object semantics
Erratum in
-
Correction: Extrafoveal attentional capture by object semantics.PLoS One. 2019 Jun 12;14(6):e0218502. doi: 10.1371/journal.pone.0218502. eCollection 2019. PLoS One. 2019. PMID: 31188888 Free PMC article.
Abstract
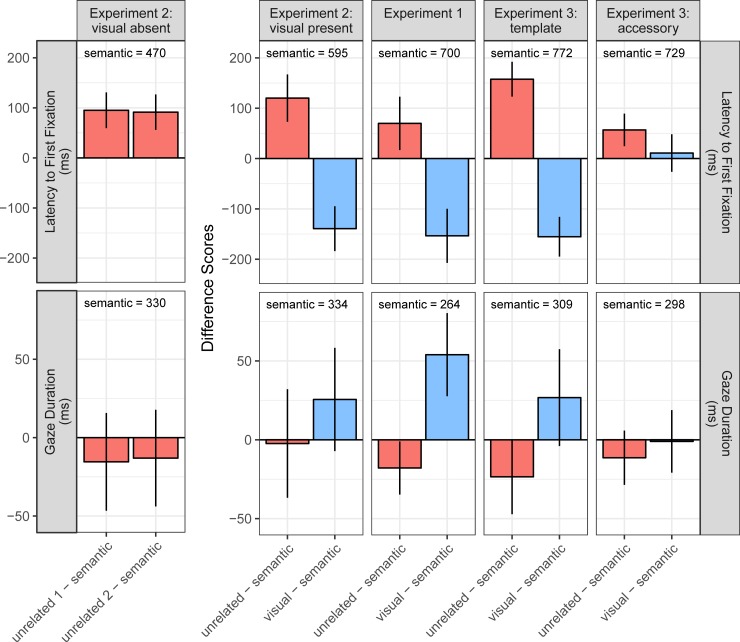
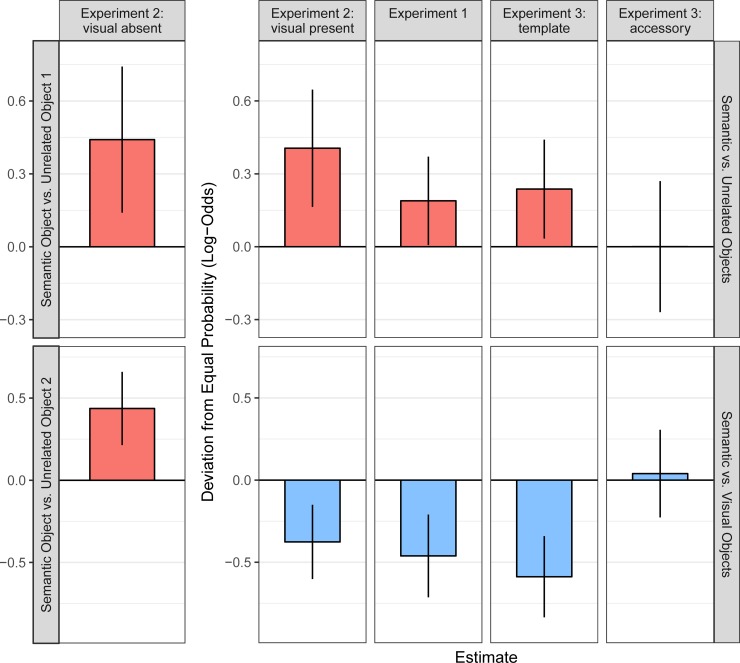
There is ongoing debate on whether object meaning can be processed outside foveal vision, making semantics available for attentional guidance. Much of the debate has centred on whether objects that do not fit within an overall scene draw attention, in complex displays that are often difficult to control. Here, we revisited the question by reanalysing data from three experiments that used displays consisting of standalone objects from a carefully controlled stimulus set. Observers searched for a target object, as per auditory instruction. On the critical trials, the displays contained no target but objects that were semantically related to the target, visually related, or unrelated. Analyses using (generalized) linear mixed-effects models showed that, although visually related objects attracted most attention, semantically related objects were also fixated earlier in time than unrelated objects. Moreover, semantic matches affected the very first saccade in the display. The amplitudes of saccades that first entered semantically related objects were larger than 5° on average, confirming that object semantics is available outside foveal vision. Finally, there was no semantic capture of attention for the same objects when observers did not actively look for the target, confirming that it was not stimulus-driven. We discuss the implications for existing models of visual cognition.
Conflict of interest statement
The authors have declared that no competing interests exist.
Figures

References
-
- Henderson JM, Hollingworth A. Eye movements during scene viewing: An overview In: Underwood G, editor. Eye guidance in reading and scene perception. Oxford: Elsevier; 1998. p. 269–93.
-
- Nuthmann A. On the visual span during object search in real-world scenes. Visual Cognition. 2013;21(7):803–37. 10.1080/13506285.2013.832449 - DOI
Publication types
MeSH terms
LinkOut - more resources
Full Text Sources
