

Drug repositioning of herbal compounds via a machine-learning approach
- PMID: 31138103
- PMCID: PMC6538545
- DOI: 10.1186/s12859-019-2811-8
Drug repositioning of herbal compounds via a machine-learning approach
Abstract
Background: Drug repositioning, also known as drug repurposing, defines new indications for existing drugs and can be used as an alternative to drug development. In recent years, the accumulation of large volumes of information related to drugs and diseases has led to the development of various computational approaches for drug repositioning. Although herbal medicines have had a great impact on current drug discovery, there are still a large number of herbal compounds that have no definite indications.
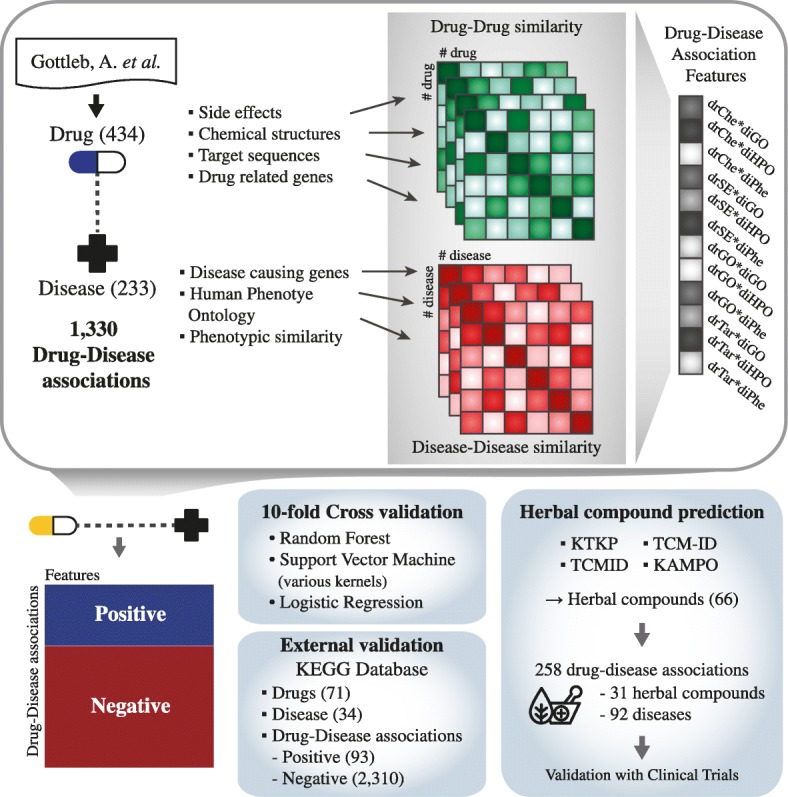
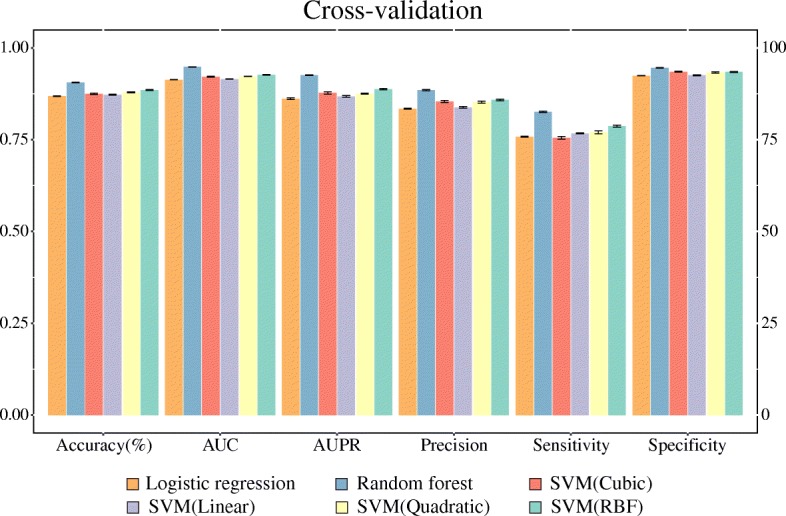
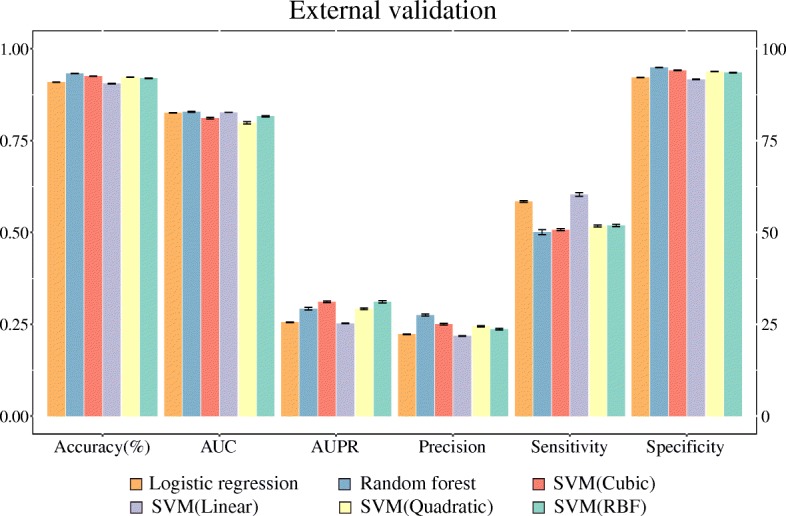
Results: In the present study, we constructed a computational model to predict the unknown pharmacological effects of herbal compounds using machine learning techniques. Based on the assumption that similar diseases can be treated with similar drugs, we used four categories of drug-drug similarity (e.g., chemical structure, side-effects, gene ontology, and targets) and three categories of disease-disease similarity (e.g., phenotypes, human phenotype ontology, and gene ontology). Then, associations between drug and disease were predicted using the employed similarity features. The prediction models were constructed using classification algorithms, including logistic regression, random forest and support vector machine algorithms. Upon cross-validation, the random forest approach showed the best performance (AUC = 0.948) and also performed well in an external validation assessment using an unseen independent dataset (AUC = 0.828). Finally, the constructed model was applied to predict potential indications for existing drugs and herbal compounds. As a result, new indications for 20 existing drugs and 31 herbal compounds were predicted and validated using clinical trial data.
Conclusions: The predicted results were validated manually confirming the performance and underlying mechanisms - for example, irinotecan as a treatment for neuroblastoma. From the prediction, herbal compounds were considered to be drug candidates for related diseases which is important to be further developed. The proposed prediction model can contribute to drug discovery by suggesting drug candidates from herbal compounds which have potentials but few were studied.
Keywords: Data mining; Drug repositioning prediction; Machine learning.
Conflict of interest statement
The authors declare that they have no competing interests.
Figures


Similar articles
-
Drug Repositioning by Integrating Known Disease-Gene and Drug-Target Associations in a Semi-supervised Learning Model.Acta Biotheor. 2018 Dec;66(4):315-331. doi: 10.1007/s10441-018-9325-z. Epub 2018 Apr 26. Acta Biotheor. 2018. PMID: 29700660
-
Drug Repositioning for Schizophrenia and Depression/Anxiety Disorders: A Machine Learning Approach Leveraging Expression Data.IEEE J Biomed Health Inform. 2019 May;23(3):1304-1315. doi: 10.1109/JBHI.2018.2856535. Epub 2018 Jul 16. IEEE J Biomed Health Inform. 2019. PMID: 30010603
-
Using Drug Expression Profiles and Machine Learning Approach for Drug Repurposing.Methods Mol Biol. 2019;1903:219-237. doi: 10.1007/978-1-4939-8955-3_13. Methods Mol Biol. 2019. PMID: 30547445 Review.
-
SNF-NN: computational method to predict drug-disease interactions using similarity network fusion and neural networks.BMC Bioinformatics. 2021 Jan 22;22(1):28. doi: 10.1186/s12859-020-03950-3. BMC Bioinformatics. 2021. PMID: 33482713 Free PMC article.
-
A survey of current trends in computational drug repositioning.Brief Bioinform. 2016 Jan;17(1):2-12. doi: 10.1093/bib/bbv020. Epub 2015 Mar 31. Brief Bioinform. 2016. PMID: 25832646 Free PMC article. Review.
Cited by
-
RLFDDA: a meta-path based graph representation learning model for drug-disease association prediction.BMC Bioinformatics. 2022 Dec 1;23(1):516. doi: 10.1186/s12859-022-05069-z. BMC Bioinformatics. 2022. PMID: 36456957 Free PMC article.
-
Applications of Genome-Wide Screening and Systems Biology Approaches in Drug Repositioning.Cancers (Basel). 2020 Sep 21;12(9):2694. doi: 10.3390/cancers12092694. Cancers (Basel). 2020. PMID: 32967266 Free PMC article. Review.
-
MiRAGE: mining relationships for advanced generative evaluation in drug repositioning.Brief Bioinform. 2024 May 23;25(4):bbae337. doi: 10.1093/bib/bbae337. Brief Bioinform. 2024. PMID: 39038932 Free PMC article.
-
Small Molecular Drug Screening Based on Clinical Therapeutic Effect.Molecules. 2022 Jul 27;27(15):4807. doi: 10.3390/molecules27154807. Molecules. 2022. PMID: 35956770 Free PMC article.
-
Artificial intelligence and big data facilitated targeted drug discovery.Stroke Vasc Neurol. 2019 Nov 7;4(4):206-213. doi: 10.1136/svn-2019-000290. eCollection 2019 Dec. Stroke Vasc Neurol. 2019. PMID: 32030204 Free PMC article. Review.
References
MeSH terms
Substances
LinkOut - more resources
Full Text Sources
Research Materials
