

Prefix-free parsing for building big BWTs
- PMID: 31149025
- PMCID: PMC6534911
- DOI: 10.1186/s13015-019-0148-5
Prefix-free parsing for building big BWTs
Abstract
High-throughput sequencing technologies have led to explosive growth of genomic databases; one of which will soon reach hundreds of terabytes. For many applications we want to build and store indexes of these databases but constructing such indexes is a challenge. Fortunately, many of these genomic databases are highly-repetitive-a characteristic that can be exploited to ease the computation of the Burrows-Wheeler Transform (BWT), which underlies many popular indexes. In this paper, we introduce a preprocessing algorithm, referred to as prefix-free parsing, that takes a text T as input, and in one-pass generates a dictionary D and a parse P of T with the property that the BWT of T can be constructed from D and P using workspace proportional to their total size and O(|T|)-time. Our experiments show that D and P are significantly smaller than T in practice, and thus, can fit in a reasonable internal memory even when T is very large. In particular, we show that with prefix-free parsing we can build an 131-MB run-length compressed FM-index (restricted to support only counting and not locating) for 1000 copies of human chromosome 19 in 2 h using 21 GB of memory, suggesting that we can build a 6.73 GB index for 1000 complete human-genome haplotypes in approximately 102 h using about 1 TB of memory.
Keywords: Burrows-Wheeler Transform; Compression-aware algorithms; Genomic databases; Prefix-free parsing.
Conflict of interest statement
Competing interestsThe authors declare that they have no competing interests.
Figures
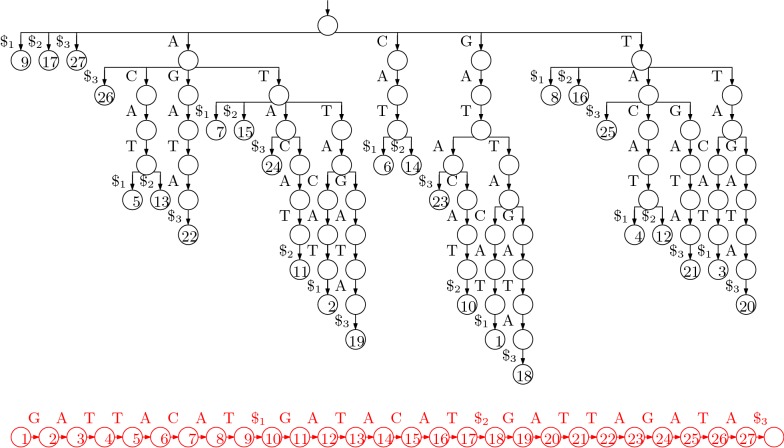
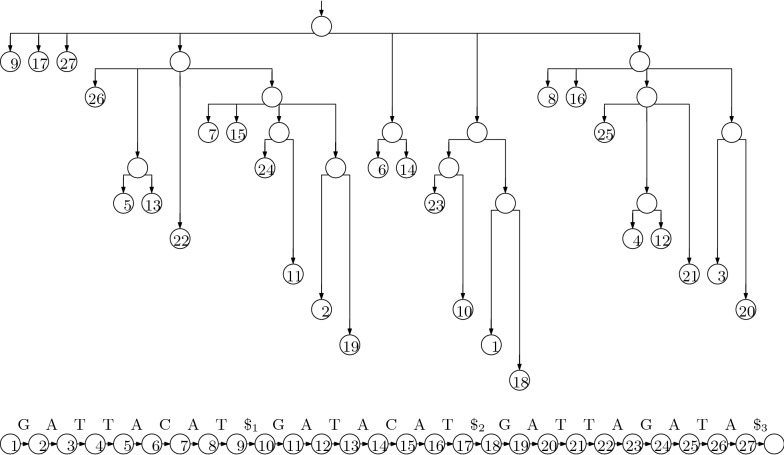
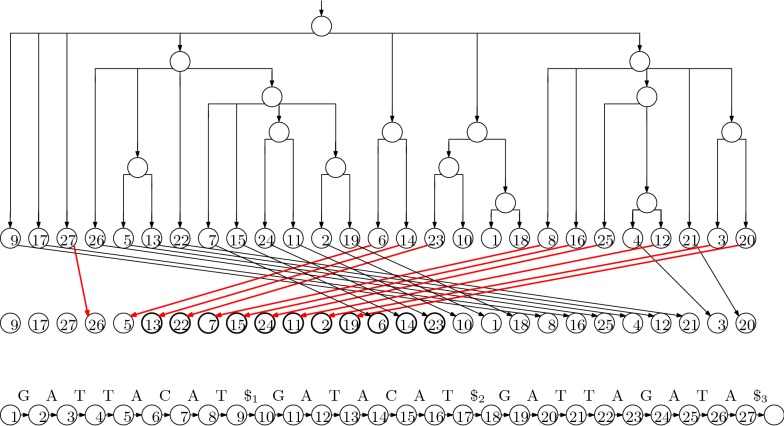
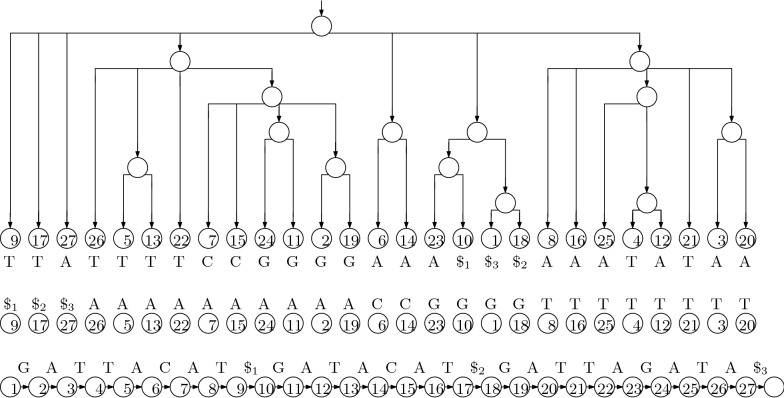
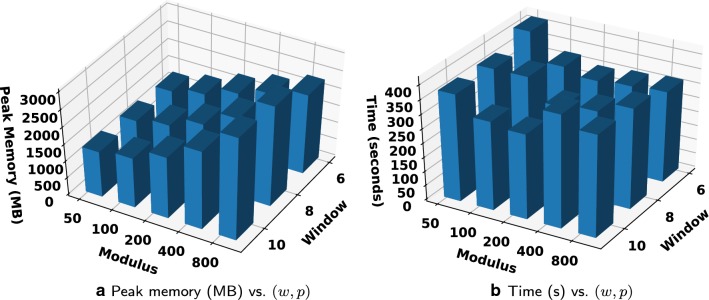
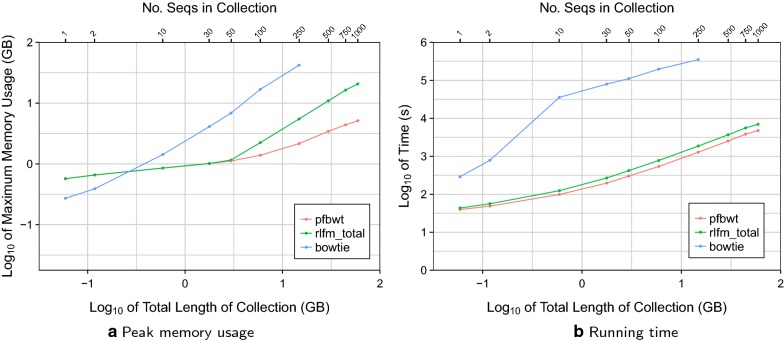
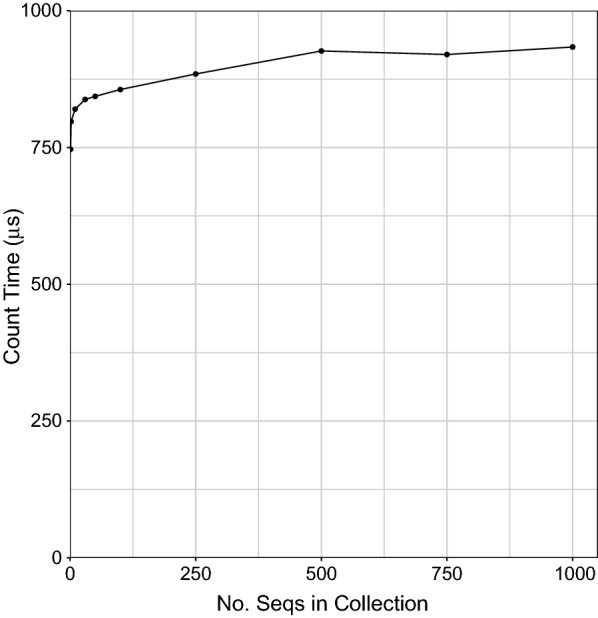

References
-
- Carleton HA, Gerner-Smidt P. Whole-genome sequencing is taking over foodborne disease surveillance. Microbe. 2016;11:311–317.
-
- Burrows M, Wheeler DJ. A block-sorting lossless compression algorithm, Technical report. : Digital Equipment Corporation; 1994.
Grants and funding
LinkOut - more resources
Full Text Sources
Miscellaneous
