

The Heterogeneity Problem: Approaches to Identify Psychiatric Subtypes
- PMID: 31153774
- PMCID: PMC6821457
- DOI: 10.1016/j.tics.2019.03.009
The Heterogeneity Problem: Approaches to Identify Psychiatric Subtypes
Abstract
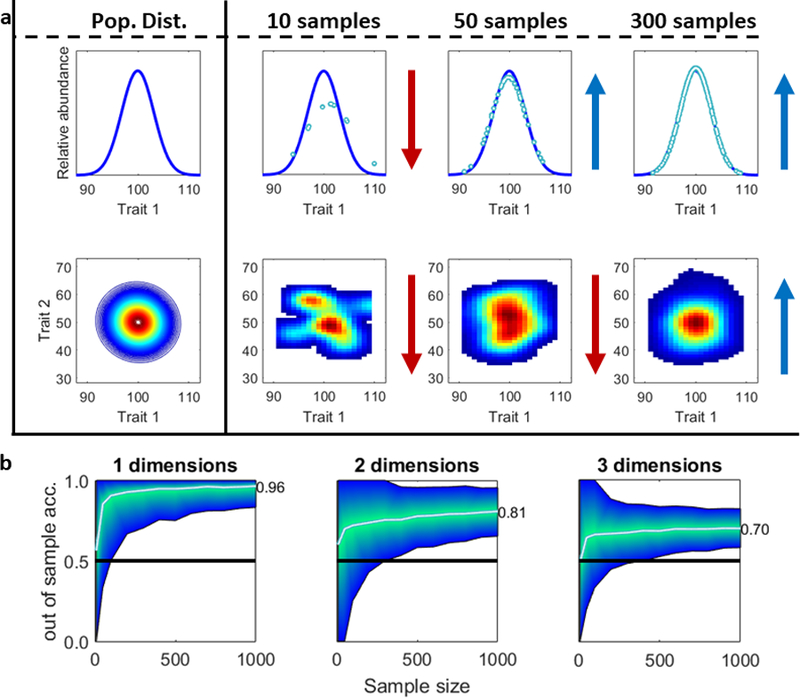
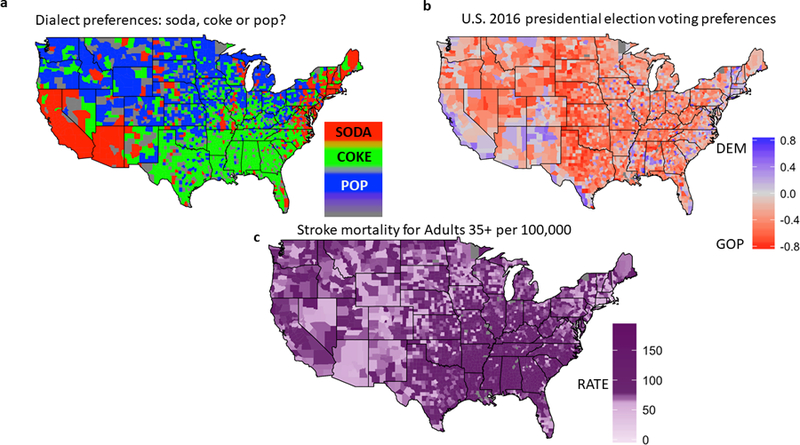
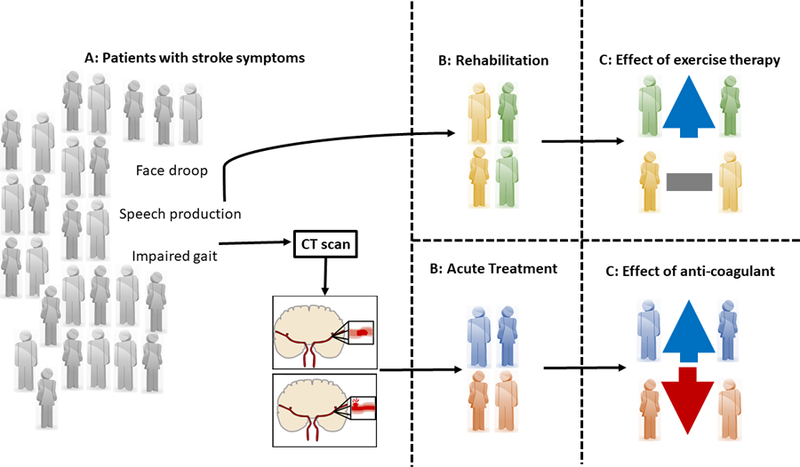
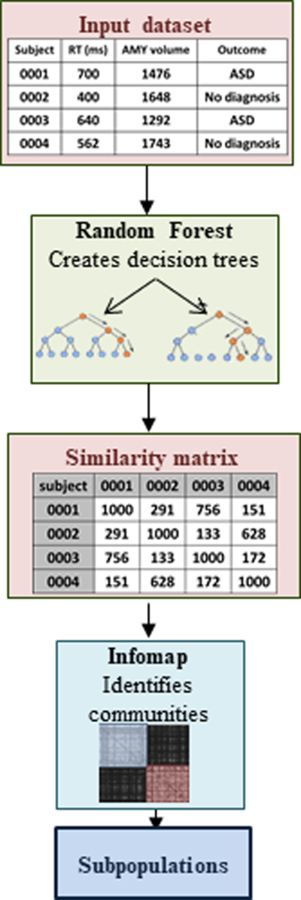
The imprecise nature of psychiatric nosology restricts progress towards characterizing and treating mental health disorders. One issue is the 'heterogeneity problem': different causal mechanisms may relate to the same disorder, and multiple outcomes of interest can occur within one individual. Our review tackles this heterogeneity problem, providing considerations, concepts, and approaches for investigators examining human cognition and mental health. We highlight the difficulty of pure dimensional approaches due to 'the curse of dimensionality'. Computationally, we consider supervised and unsupervised statistical approaches to identify putative subtypes within a population. However, we emphasize that subtype identification should be linked to a particular outcome or question. We conclude with novel hybrid approaches that can identify subtypes tied to outcomes, and may help advance precision diagnostic and treatment tools.
Keywords: functional random forest; heterogeneity; machine learning; mental health; surrogate variable analysis.
Copyright © 2019. Published by Elsevier Ltd.
Figures
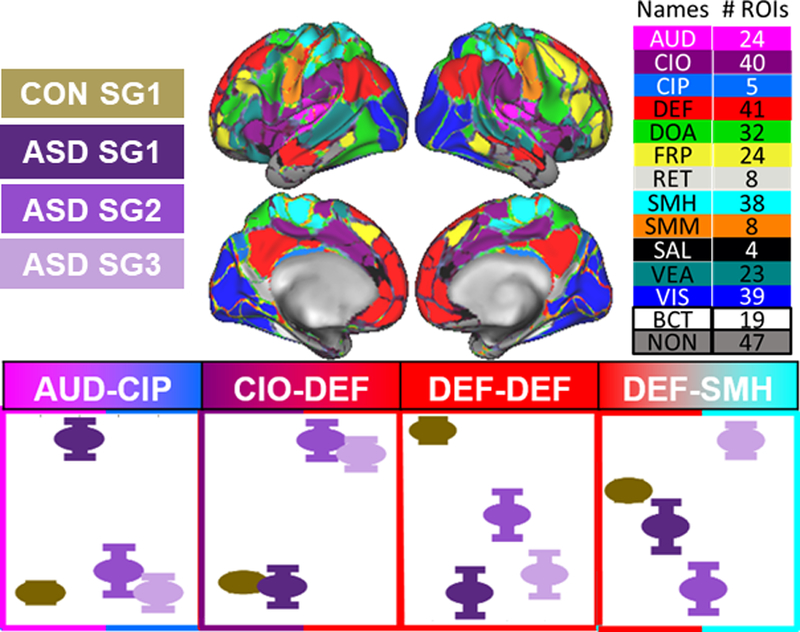
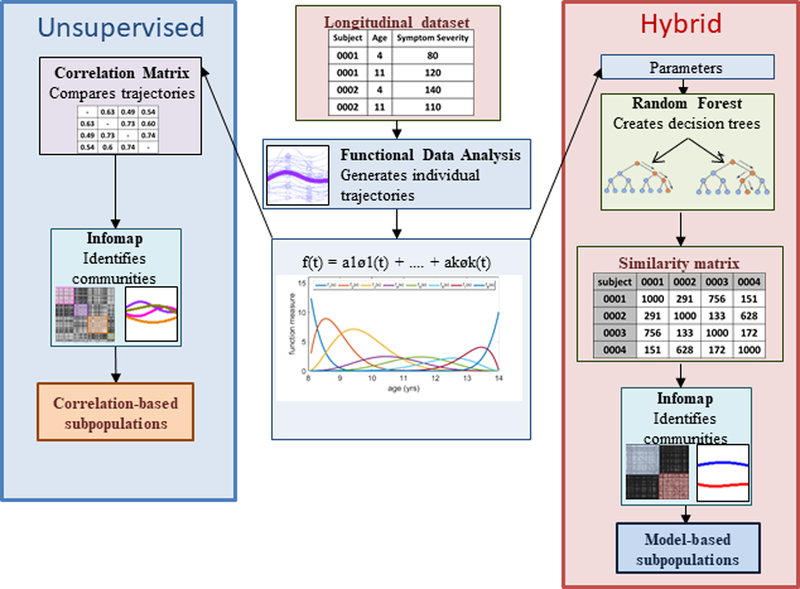
References
-
- Nigg JT (2006) Temperament and developmental psychopathology. J. Child Psychol. Psychiatry 47, 395–422 - PubMed
-
- Mason D and Hsin H (2018) ‘A more perfect arrangement of plants’: the botanical model in psychiatric nosology, 1676 to the present day. Hist. Psychiatry 29, 131–146 - PubMed
-
- Organization, W.H. and others (1996) Multiaxial classification of child and adolescent psychiatric disorders: the ICD-10 classification of mental and behavioural disorders in children and adolescents, Cambridge Univ Pr.
-
- Robins LN et al. (1981) National Institute of Mental Health Diagnostic Interview Schedule: Its history, characteristics, and validity. Arch Gen Psychiatry 38, 381–389 - PubMed
Publication types
MeSH terms
Grants and funding
LinkOut - more resources
Full Text Sources
Other Literature Sources
Medical
