

BiosyntheticSPAdes: reconstructing biosynthetic gene clusters from assembly graphs
- PMID: 31160374
- PMCID: PMC6673720
- DOI: 10.1101/gr.243477.118
BiosyntheticSPAdes: reconstructing biosynthetic gene clusters from assembly graphs
Abstract
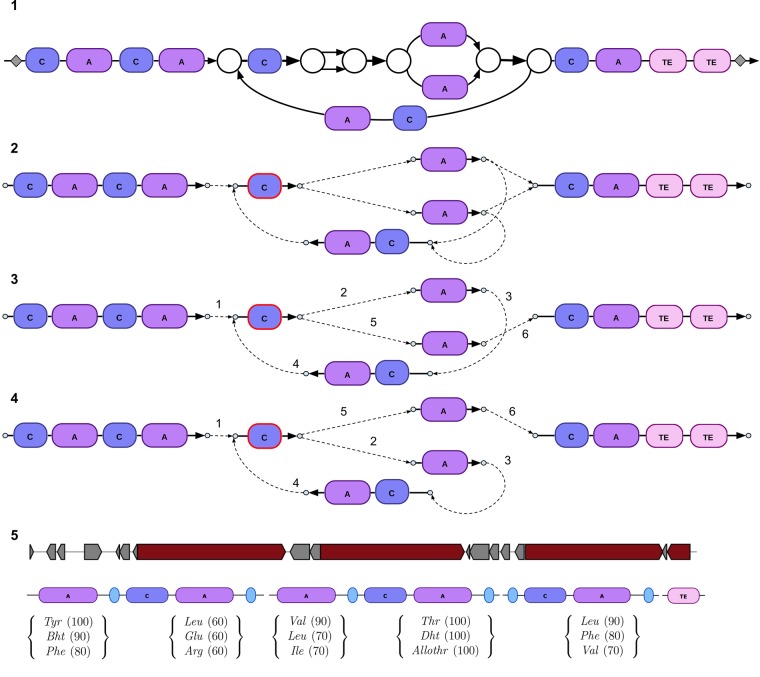
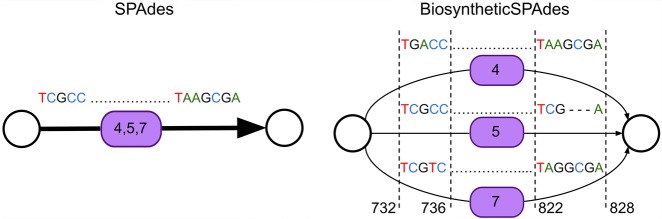
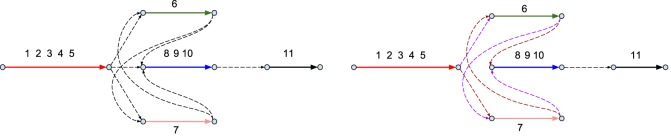
Predicting biosynthetic gene clusters (BGCs) is critically important for discovery of antibiotics and other natural products. While BGC prediction from complete genomes is a well-studied problem, predicting BGCs in fragmented genomic assemblies remains challenging. The existing BGC prediction tools often assume that each BGC is encoded within a single contig in the genome assembly, a condition that is violated for most sequenced microbial genomes where BGCs are often scattered through several contigs, making it difficult to reconstruct them. The situation is even more severe in shotgun metagenomics, where the contigs are often short, and the existing tools fail to predict a large fraction of long BGCs. While it is difficult to assemble BGCs in a single contig, the structure of the genome assembly graph often provides clues on how to combine multiple contigs into segments encoding long BGCs. We describe biosyntheticSPAdes, a tool for predicting BGCs in assembly graphs and demonstrate that it greatly improves the reconstruction of BGCs from genomic and metagenomics data sets.
© 2019 Meleshko et al.; Published by Cold Spring Harbor Laboratory Press.
Figures
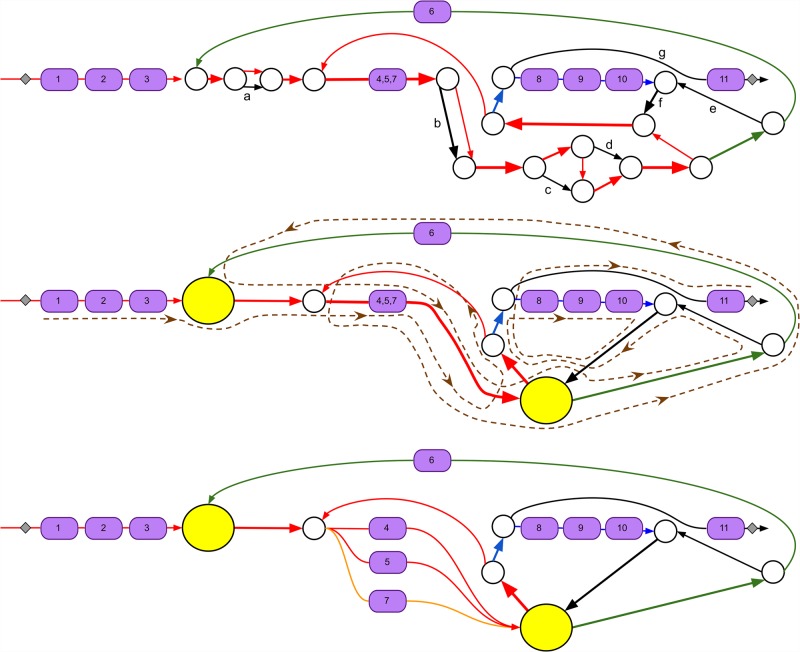
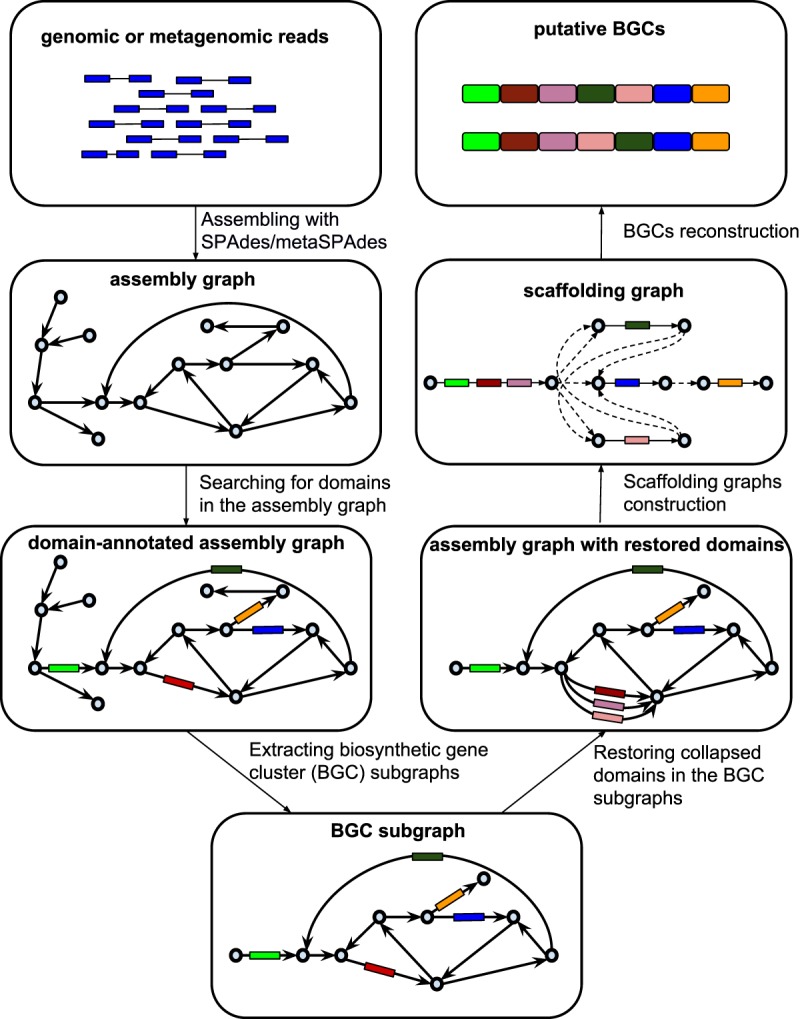
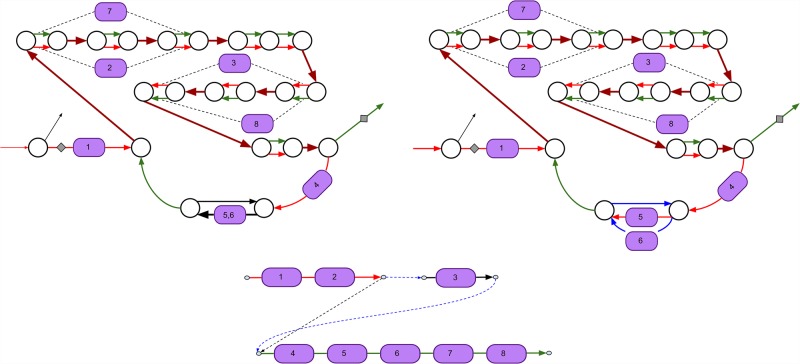
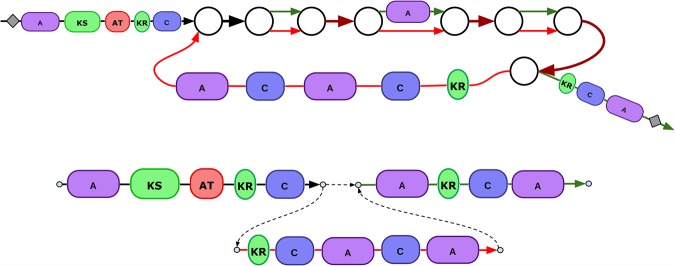
References
Publication types
MeSH terms
Associated data
Grants and funding
LinkOut - more resources
Full Text Sources