

Terminator-free template-independent enzymatic DNA synthesis for digital information storage
- PMID: 31160595
- PMCID: PMC6546792
- DOI: 10.1038/s41467-019-10258-1
Terminator-free template-independent enzymatic DNA synthesis for digital information storage
Abstract
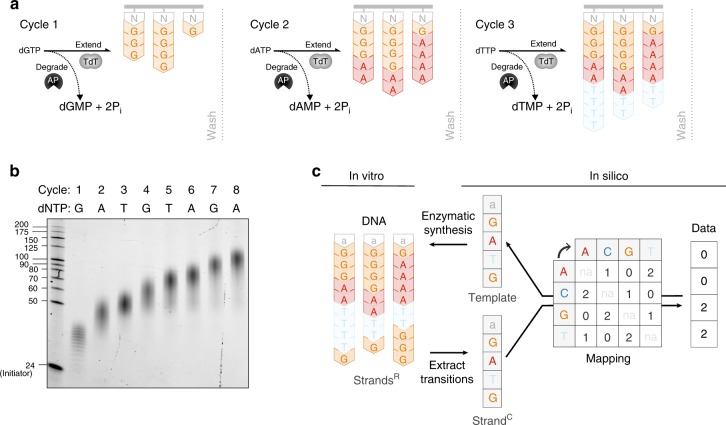
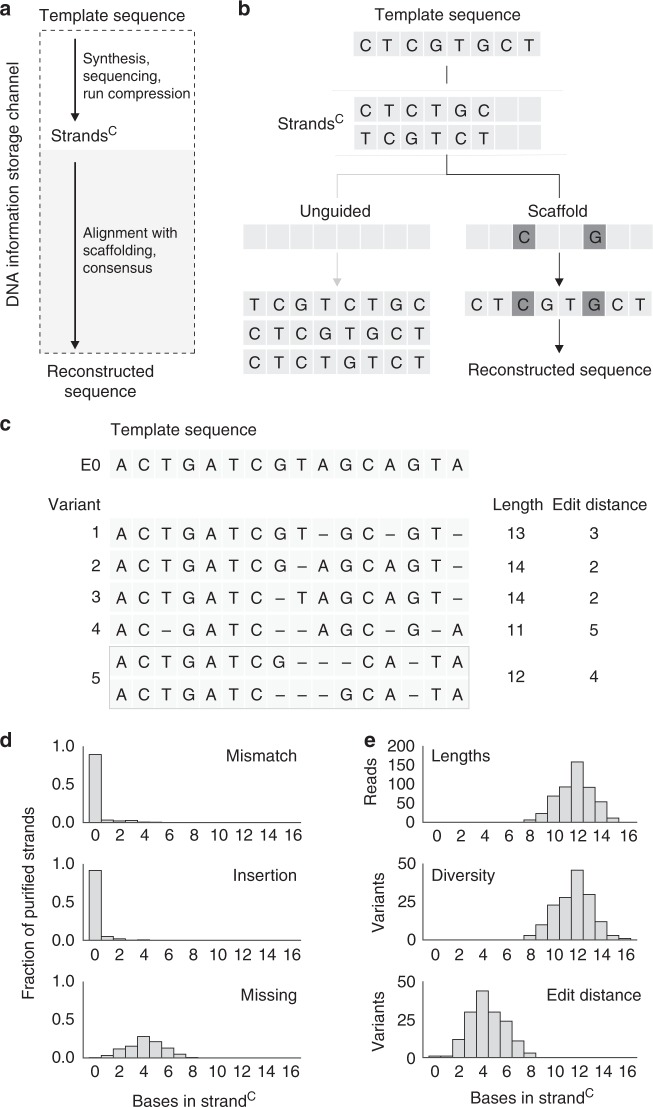
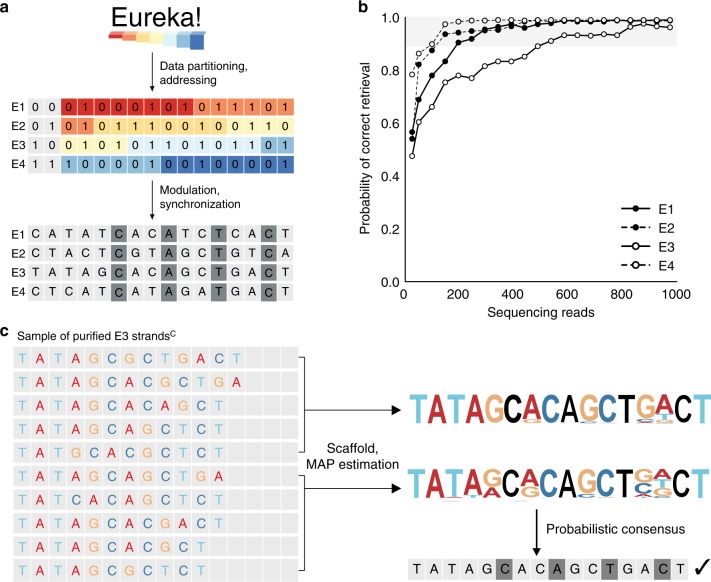
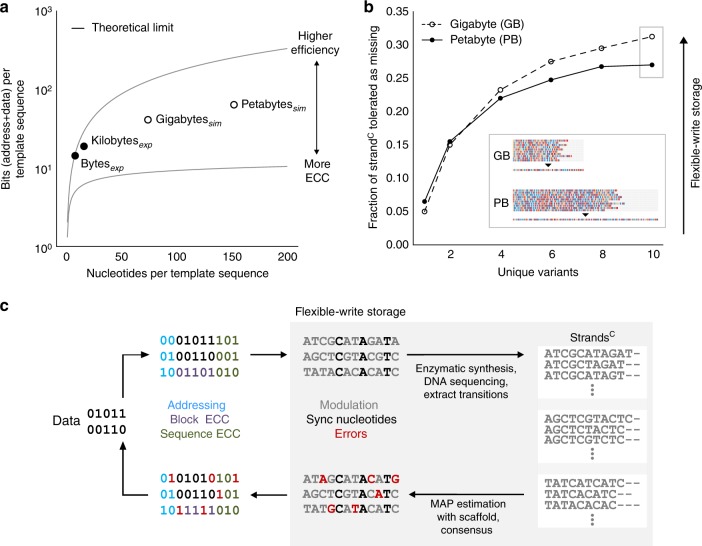
DNA is an emerging medium for digital data and its adoption can be accelerated by synthesis processes specialized for storage applications. Here, we describe a de novo enzymatic synthesis strategy designed for data storage which harnesses the template-independent polymerase terminal deoxynucleotidyl transferase (TdT) in kinetically controlled conditions. Information is stored in transitions between non-identical nucleotides of DNA strands. To produce strands representing user-defined content, nucleotide substrates are added iteratively, yielding short homopolymeric extensions whose lengths are controlled by apyrase-mediated substrate degradation. With this scheme, we synthesize DNA strands carrying 144 bits, including addressing, and demonstrate retrieval with streaming nanopore sequencing. We further devise a digital codec to reduce requirements for synthesis accuracy and sequencing coverage, and experimentally show robust data retrieval from imperfectly synthesized strands. This work provides distributive enzymatic synthesis and information-theoretic approaches to advance digital information storage in DNA.
Conflict of interest statement
H.H.L., R.K., and G.M.C. have filed patents covering the synthesis process (WO 2017/176541) and the encoding/decoding process (PCT/US18/56900). N.G and J.B. have filed a patent for the use of synchronization markers for the codec (WO 2018/148260).
Figures

References
-
- Blawat M, et al. Forward error correction for DNA data storage. Procedia Comput. Sci. 2016;80:1011–1022. doi: 10.1016/j.procs.2016.05.398. - DOI
Publication types
MeSH terms
Substances
Grants and funding
- DE-FG02-02ER63445/U.S. Department of Energy (DOE)/International
- DE-FG02-02ER63445/U.S. Department of Energy (DOE)/International
- R01-MH103910-02/U.S. Department of Health & Human Services | National Institutes of Health (NIH)/International
- R01-MH103910-02/U.S. Department of Health & Human Services | National Institutes of Health (NIH)/International
- R01-MH103910-02/U.S. Department of Health & Human Services | National Institutes of Health (NIH)/International
LinkOut - more resources
Full Text Sources
Other Literature Sources
