

Models that learn how humans learn: The case of decision-making and its disorders
- PMID: 31185008
- PMCID: PMC6588260
- DOI: 10.1371/journal.pcbi.1006903
Models that learn how humans learn: The case of decision-making and its disorders
Abstract
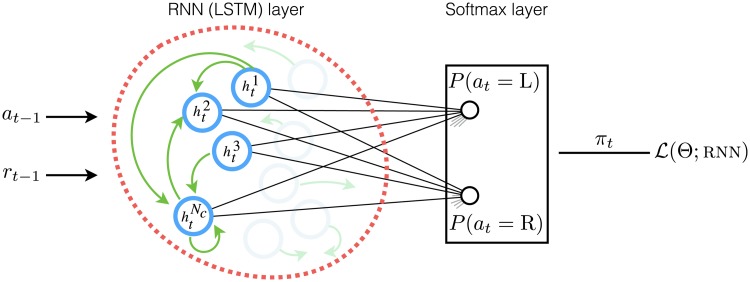
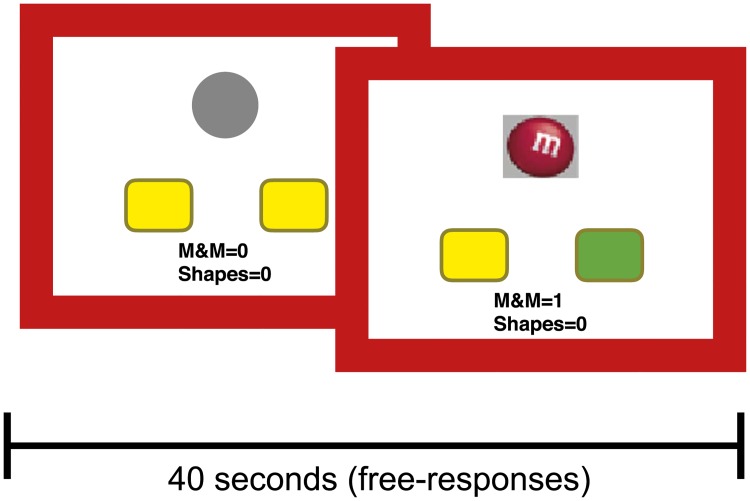
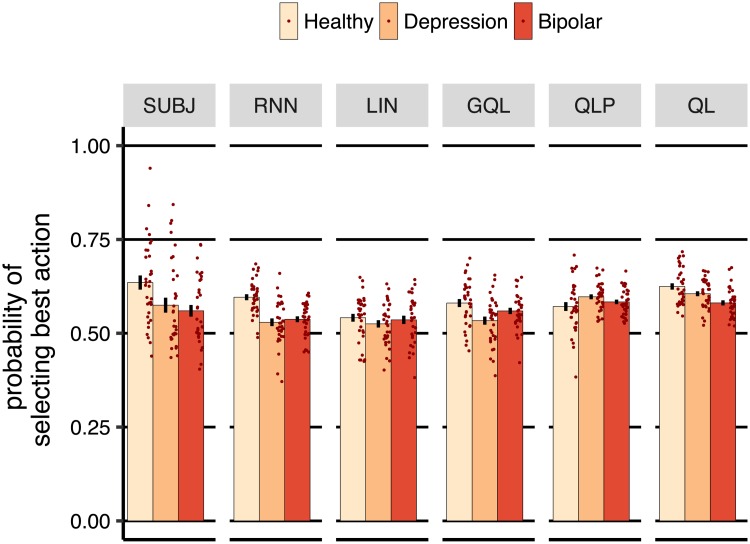
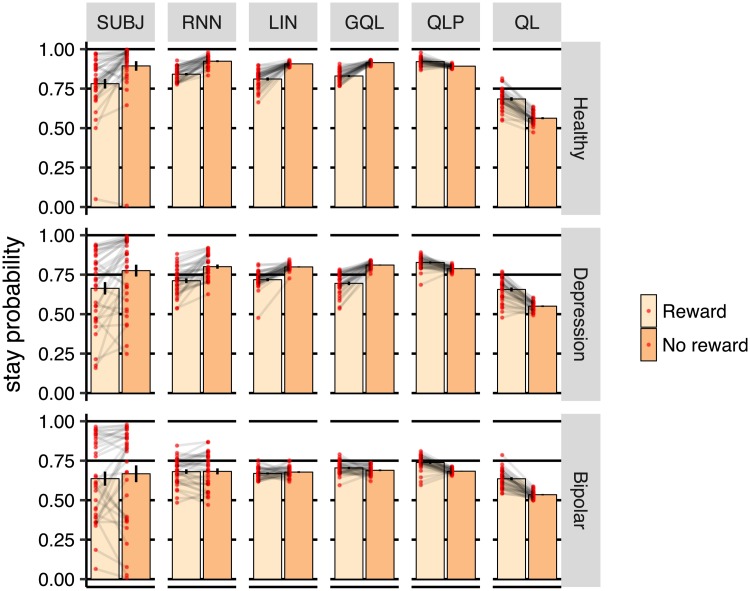
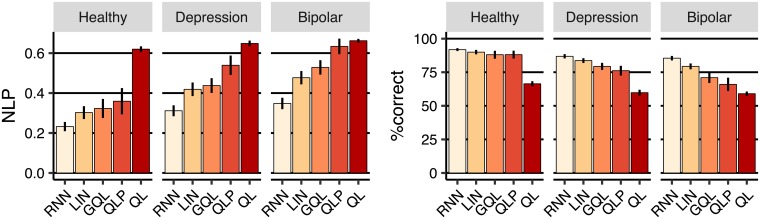
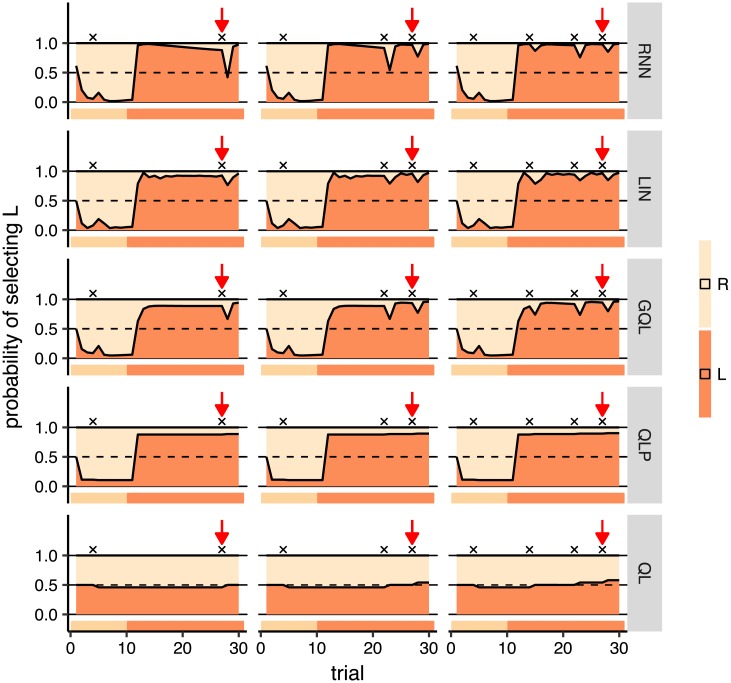
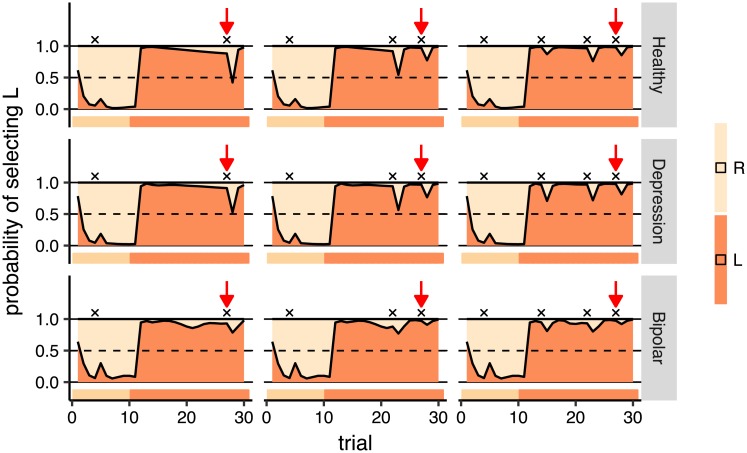
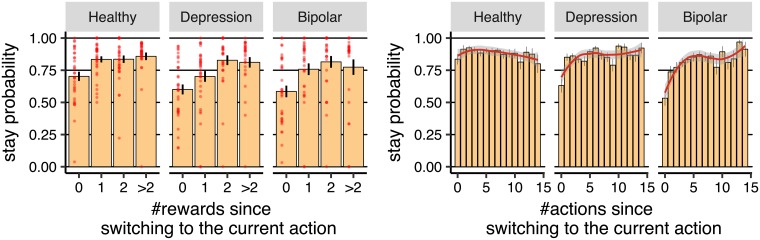
Popular computational models of decision-making make specific assumptions about learning processes that may cause them to underfit observed behaviours. Here we suggest an alternative method using recurrent neural networks (RNNs) to generate a flexible family of models that have sufficient capacity to represent the complex learning and decision- making strategies used by humans. In this approach, an RNN is trained to predict the next action that a subject will take in a decision-making task and, in this way, learns to imitate the processes underlying subjects' choices and their learning abilities. We demonstrate the benefits of this approach using a new dataset drawn from patients with either unipolar (n = 34) or bipolar (n = 33) depression and matched healthy controls (n = 34) making decisions on a two-armed bandit task. The results indicate that this new approach is better than baseline reinforcement-learning methods in terms of overall performance and its capacity to predict subjects' choices. We show that the model can be interpreted using off-policy simulations and thereby provides a novel clustering of subjects' learning processes-something that often eludes traditional approaches to modelling and behavioural analysis.
Conflict of interest statement
Part of this work was conducted while PD was visiting Uber Technologies. The latter played no role in its design, execution or communication.
Figures
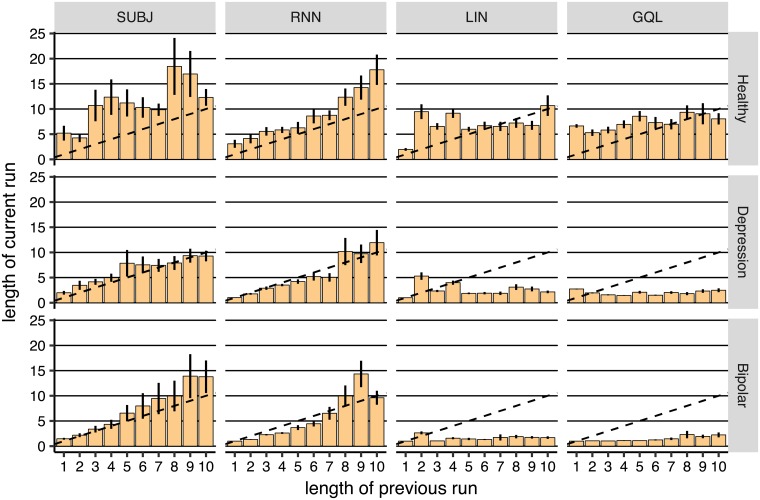
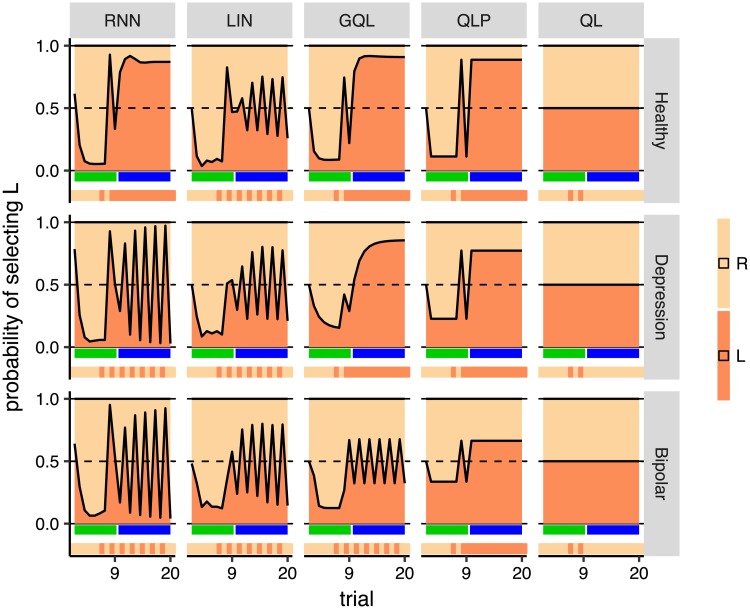
Similar articles
-
Reward and avoidance learning in the context of aversive environments and possible implications for depressive symptoms.Psychopharmacology (Berl). 2019 Aug;236(8):2437-2449. doi: 10.1007/s00213-019-05299-9. Epub 2019 Jun 28. Psychopharmacology (Berl). 2019. PMID: 31254091 Free PMC article. Clinical Trial.
-
Cost-benefit trade-offs in decision-making and learning.PLoS Comput Biol. 2019 Sep 6;15(9):e1007326. doi: 10.1371/journal.pcbi.1007326. eCollection 2019 Sep. PLoS Comput Biol. 2019. PMID: 31490934 Free PMC article.
-
Reinforcement learning signals in the human striatum distinguish learners from nonlearners during reward-based decision making.J Neurosci. 2007 Nov 21;27(47):12860-7. doi: 10.1523/JNEUROSCI.2496-07.2007. J Neurosci. 2007. PMID: 18032658 Free PMC article.
-
Neural basis of reinforcement learning and decision making.Annu Rev Neurosci. 2012;35:287-308. doi: 10.1146/annurev-neuro-062111-150512. Epub 2012 Mar 29. Annu Rev Neurosci. 2012. PMID: 22462543 Free PMC article. Review.
-
The application of computational models to social neuroscience: promises and pitfalls.Soc Neurosci. 2018 Dec;13(6):637-647. doi: 10.1080/17470919.2018.1518834. Epub 2018 Sep 12. Soc Neurosci. 2018. PMID: 30173633 Free PMC article. Review.
Cited by
-
Using deep learning to predict human decisions and using cognitive models to explain deep learning models.Sci Rep. 2022 Mar 18;12(1):4736. doi: 10.1038/s41598-022-08863-0. Sci Rep. 2022. PMID: 35304572 Free PMC article.
-
Revisiting the importance of model fitting for model-based fMRI: It does matter in computational psychiatry.PLoS Comput Biol. 2021 Feb 9;17(2):e1008738. doi: 10.1371/journal.pcbi.1008738. eCollection 2021 Feb. PLoS Comput Biol. 2021. PMID: 33561125 Free PMC article.
-
Designing optimal behavioral experiments using machine learning.Elife. 2024 Jan 23;13:e86224. doi: 10.7554/eLife.86224. Elife. 2024. PMID: 38261382 Free PMC article.
-
Distributional dual-process model predicts strategic shifts in decision-making under uncertainty.Commun Psychol. 2025 Apr 14;3(1):61. doi: 10.1038/s44271-025-00249-y. Commun Psychol. 2025. PMID: 40229534 Free PMC article.
-
Using deep neural networks as a guide for modeling human planning.Sci Rep. 2023 Nov 20;13(1):20269. doi: 10.1038/s41598-023-46850-1. Sci Rep. 2023. PMID: 37985896 Free PMC article.
References
-
- Busemeyer JR, Diederich A. Cognitive modeling. Sage; 2010.
-
- Daw ND. Trial-by-trial data analysis using computational models In: Delgado MR, Phelps EA, Robbins TW, editors. Decision Making, Affect, and Learning. Oxford University Press; 2011.
-
- Busemeyer JR, Stout JC. A contribution of cognitive decision models to clinical assessment:decomposing performance on the Bechara gambling task. Psychological assessment. 2002;14(3):253–62 - PubMed
Publication types
MeSH terms
LinkOut - more resources
Full Text Sources
