

A dropout-regularized classifier development approach optimized for precision medicine test discovery from omics data
- PMID: 31196002
- PMCID: PMC6567499
- DOI: 10.1186/s12859-019-2922-2
A dropout-regularized classifier development approach optimized for precision medicine test discovery from omics data
Abstract
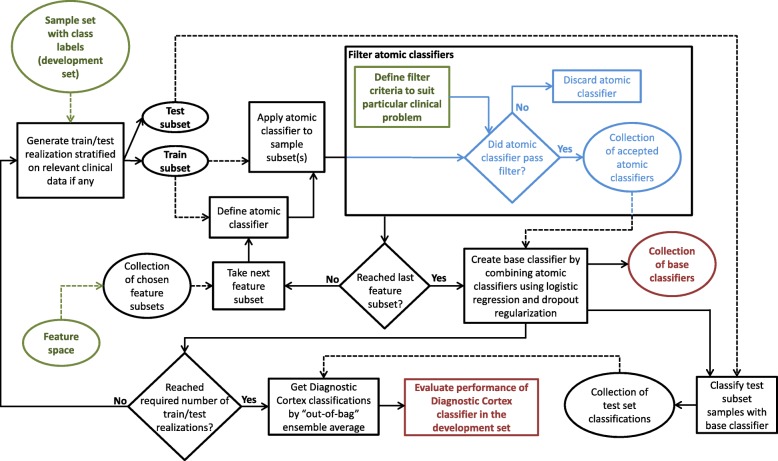
Background: Modern genomic and proteomic profiling methods produce large amounts of data from tissue and blood-based samples that are of potential utility for improving patient care. However, the design of precision medicine tests for unmet clinical needs from this information in the small cohorts available for test discovery remains a challenging task. Obtaining reliable performance assessments at the earliest stages of test development can also be problematic. We describe a novel approach to classifier development designed to create clinically useful tests together with reliable estimates of their performance. The method incorporates elements of traditional and modern machine learning to facilitate the use of cohorts where the number of samples is less than the number of measured patient attributes. It is based on a hierarchy of classification and information abstraction and combines boosting, bagging, and strong dropout regularization.
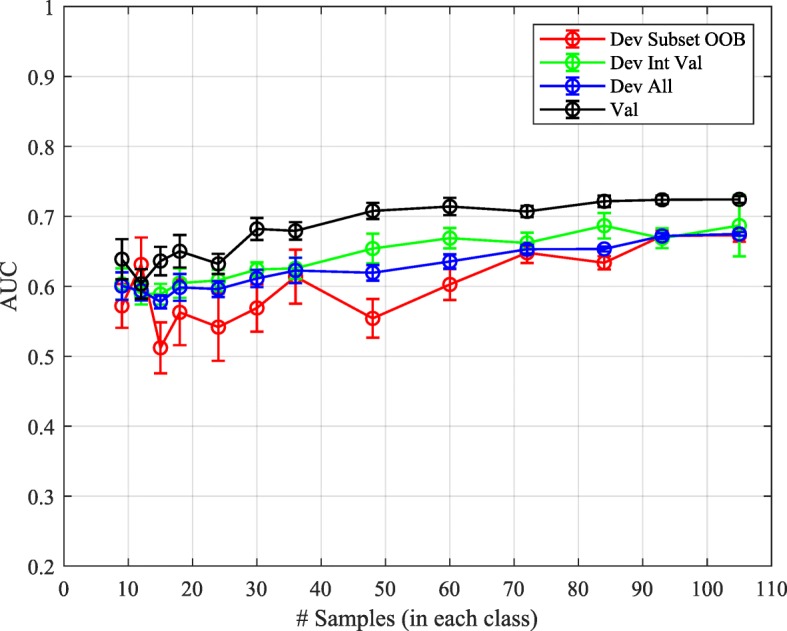
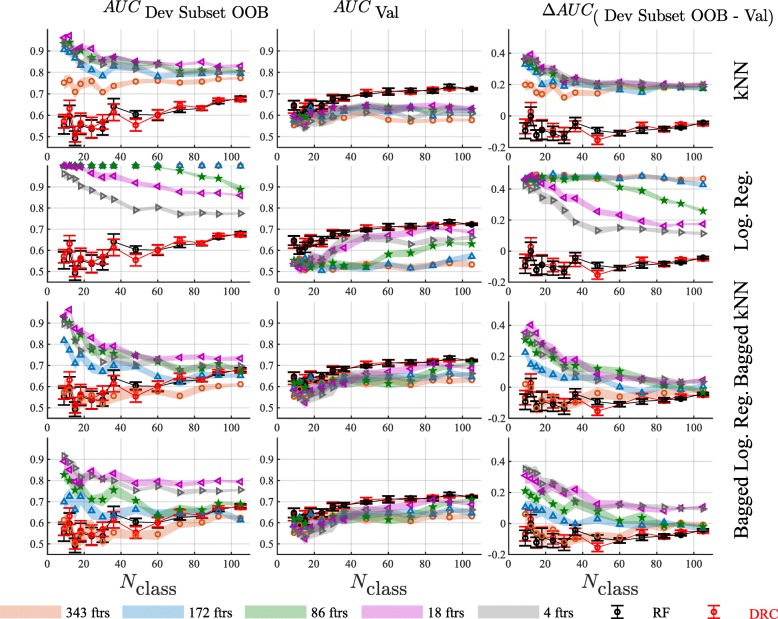
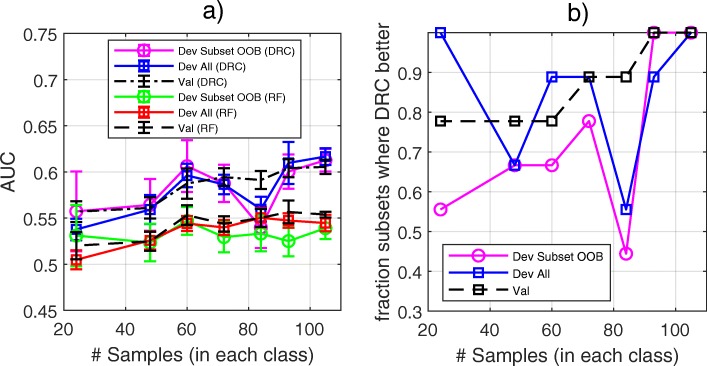
Results: We apply this dropout-regularized combination approach to two clinical problems in oncology using mRNA expression and associated clinical data and compare performance with other methods of classifier generation, including Random Forest. Performance of the new method is similar to or better than the Random Forest in the two classification tasks used for comparison. The dropout-regularized combination method also generates an effective classifier in a classification task with a known confounding variable. Most importantly, it provides a reliable estimate of test performance from a relatively small development set of samples.
Conclusions: The flexible dropout-regularized combination approach is able to produce tests tailored to particular clinical questions and mitigate known confounding effects. It allows the design of molecular diagnostic tests addressing particular clinical questions together with reliable assessment of whether test performance is likely to be fit-for-purpose in independent validation at the earliest stages of development.
Keywords: Boosting; Ensemble average; Machine Learning; Molecular diagnostics; Regularization.
Conflict of interest statement
JR and HR are inventors on a patent describing the DRC classifier development approach assigned to Biodesix, Inc. All authors are current or former employees of and have or had stock options in Biodesix, Inc.
Figures
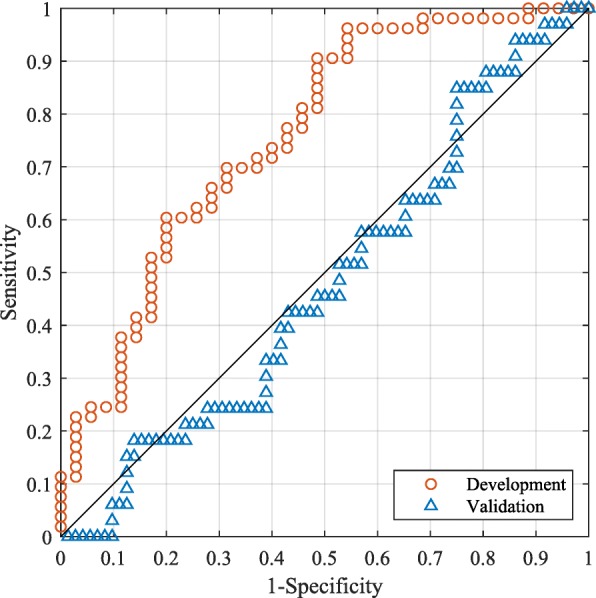
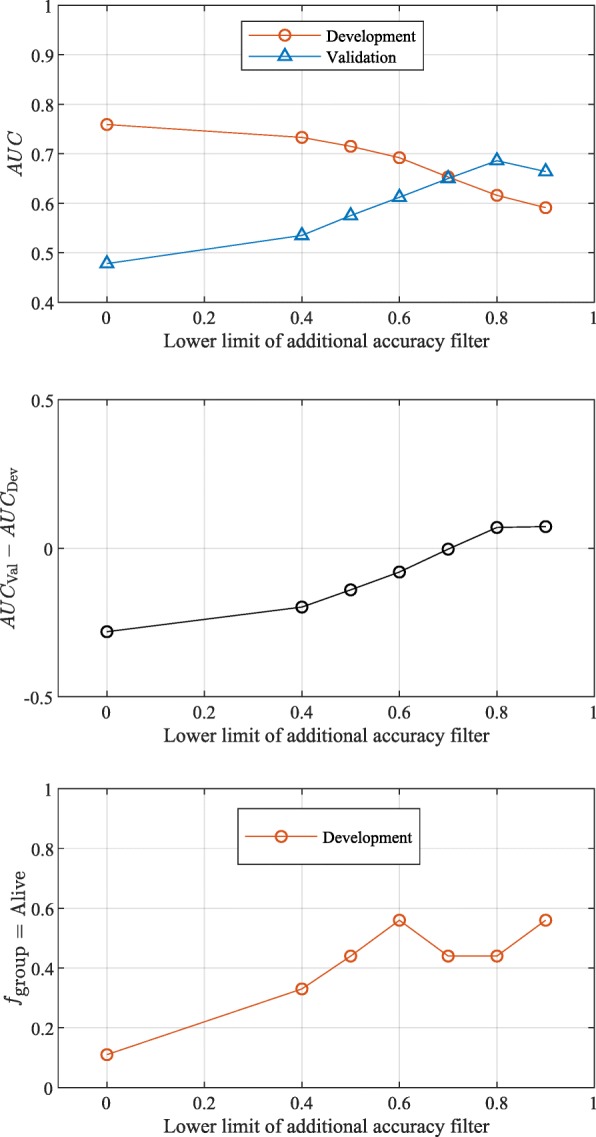
References
-
- Kelly AD, Hill KE, Correll M, Hu L, Wang YE, Rubio R, Duan S, Quackenbush J, Spentzos D. Next-generation sequencing and microarray-based interrogation of microRNAs from formalin-fixed, paraffin-embedded tissue: preliminary assessment of cross-platform concordance. Genomics. 2013;102(1):8–14. doi: 10.1016/j.ygeno.2013.03.008. - DOI - PMC - PubMed
MeSH terms
LinkOut - more resources
Full Text Sources
Other Literature Sources
