

The Ventral Visual Pathway Represents Animal Appearance over Animacy, Unlike Human Behavior and Deep Neural Networks
- PMID: 31196934
- PMCID: PMC6697402
- DOI: 10.1523/JNEUROSCI.1714-18.2019
The Ventral Visual Pathway Represents Animal Appearance over Animacy, Unlike Human Behavior and Deep Neural Networks
Abstract
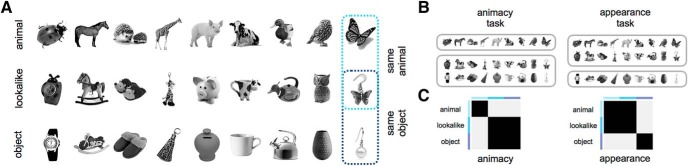
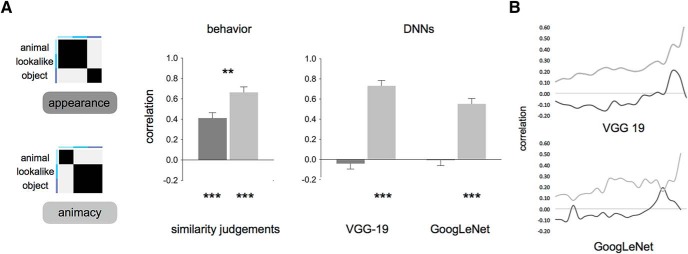
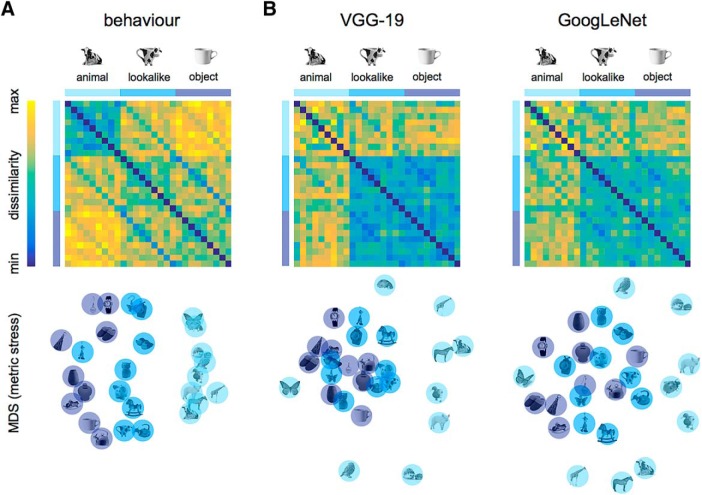
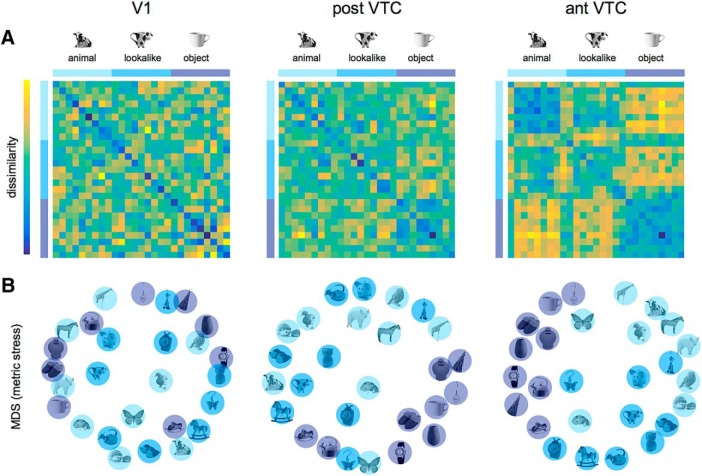
Recent studies showed agreement between how the human brain and neural networks represent objects, suggesting that we might start to understand the underlying computations. However, we know that the human brain is prone to biases at many perceptual and cognitive levels, often shaped by learning history and evolutionary constraints. Here, we explore one such perceptual phenomenon, perceiving animacy, and use the performance of neural networks as a benchmark. We performed an fMRI study that dissociated object appearance (what an object looks like) from object category (animate or inanimate) by constructing a stimulus set that includes animate objects (e.g., a cow), typical inanimate objects (e.g., a mug), and, crucially, inanimate objects that look like the animate objects (e.g., a cow mug). Behavioral judgments and deep neural networks categorized images mainly by animacy, setting all objects (lookalike and inanimate) apart from the animate ones. In contrast, activity patterns in ventral occipitotemporal cortex (VTC) were better explained by object appearance: animals and lookalikes were similarly represented and separated from the inanimate objects. Furthermore, the appearance of an object interfered with proper object identification, such as failing to signal that a cow mug is a mug. The preference in VTC to represent a lookalike as animate was even present when participants performed a task requiring them to report the lookalikes as inanimate. In conclusion, VTC representations, in contrast to neural networks, fail to represent objects when visual appearance is dissociated from animacy, probably due to a preferred processing of visual features typical of animate objects.SIGNIFICANCE STATEMENT How does the brain represent objects that we perceive around us? Recent advances in artificial intelligence have suggested that object categorization and its neural correlates have now been approximated by neural networks. Here, we show that neural networks can predict animacy according to human behavior but do not explain visual cortex representations. In ventral occipitotemporal cortex, neural activity patterns were strongly biased toward object appearance, to the extent that objects with visual features resembling animals were represented closely to real animals and separated from other objects from the same category. This organization that privileges animals and their features over objects might be the result of learning history and evolutionary constraints.
Keywords: MVPA; animacy; deep neural networks; fMRI; object representations; occipitotemporal cortex.
Copyright © 2019 the authors.
Figures

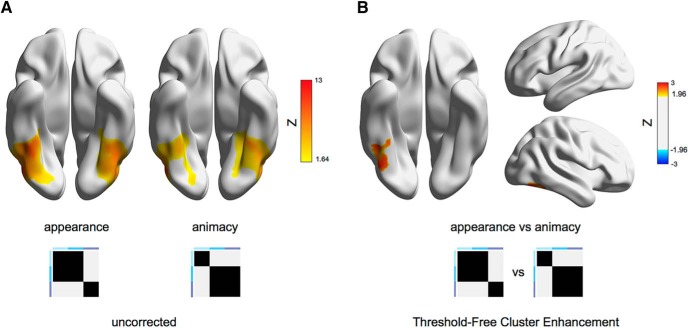
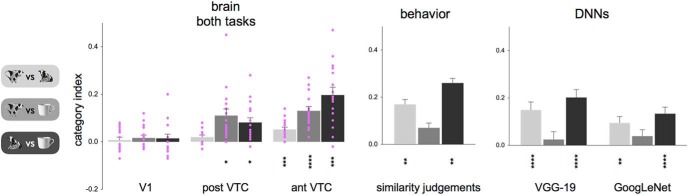
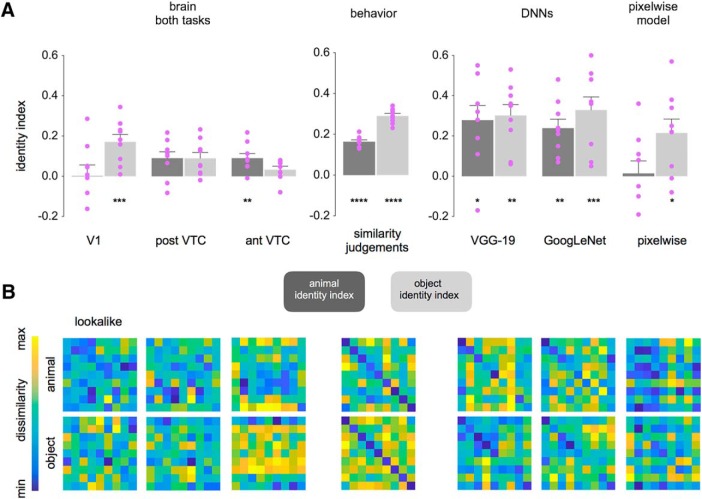
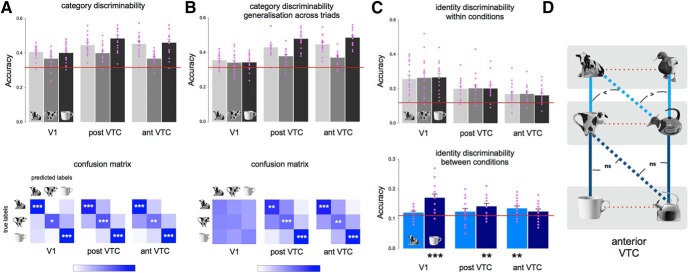
Similar articles
-
Disentangling Representations of Object Shape and Object Category in Human Visual Cortex: The Animate-Inanimate Distinction.J Cogn Neurosci. 2016 May;28(5):680-92. doi: 10.1162/jocn_a_00924. Epub 2016 Jan 14. J Cogn Neurosci. 2016. PMID: 26765944
-
The role of animal faces in the animate-inanimate distinction in the ventral temporal cortex.Neuropsychologia. 2022 May 3;169:108192. doi: 10.1016/j.neuropsychologia.2022.108192. Epub 2022 Mar 1. Neuropsychologia. 2022. PMID: 35245528
-
MEG sensor patterns reflect perceptual but not categorical similarity of animate and inanimate objects.Neuroimage. 2019 Jun;193:167-177. doi: 10.1016/j.neuroimage.2019.03.028. Epub 2019 Mar 15. Neuroimage. 2019. PMID: 30885785
-
Visual Object Recognition: Do We (Finally) Know More Now Than We Did?Annu Rev Vis Sci. 2016 Oct 14;2:377-396. doi: 10.1146/annurev-vision-111815-114621. Epub 2016 Aug 3. Annu Rev Vis Sci. 2016. PMID: 28532357 Review.
-
On the partnership between neural representations of object categories and visual features in the ventral visual pathway.Neuropsychologia. 2017 Oct;105:153-164. doi: 10.1016/j.neuropsychologia.2017.06.010. Epub 2017 Jun 12. Neuropsychologia. 2017. PMID: 28619529 Free PMC article. Review.
Cited by
-
Empirically Identifying and Computationally Modeling the Brain-Behavior Relationship for Human Scene Categorization.J Cogn Neurosci. 2023 Nov 1;35(11):1879-1897. doi: 10.1162/jocn_a_02043. J Cogn Neurosci. 2023. PMID: 37590093 Free PMC article.
-
Similarity judgments and cortical visual responses reflect different properties of object and scene categories in naturalistic images.Neuroimage. 2019 Aug 15;197:368-382. doi: 10.1016/j.neuroimage.2019.04.079. Epub 2019 May 1. Neuroimage. 2019. PMID: 31054350 Free PMC article.
-
Disentangling five dimensions of animacy in human brain and behaviour.Commun Biol. 2022 Nov 14;5(1):1247. doi: 10.1038/s42003-022-04194-y. Commun Biol. 2022. PMID: 36376446 Free PMC article.
-
Categorical representation from sound and sight in the ventral occipito-temporal cortex of sighted and blind.Elife. 2020 Feb 28;9:e50732. doi: 10.7554/eLife.50732. Elife. 2020. PMID: 32108572 Free PMC article.
-
Using deep neural networks to evaluate object vision tasks in rats.PLoS Comput Biol. 2021 Mar 2;17(3):e1008714. doi: 10.1371/journal.pcbi.1008714. eCollection 2021 Mar. PLoS Comput Biol. 2021. PMID: 33651793 Free PMC article.
References
-
- Baldassi C, Alemi-Neissi A, Pagan M, Dicarlo JJ, Zecchina R, Zoccolan D (2013) Shape similarity, better than semantic membership, accounts for the structure of visual object representations in a population of monkey inferotemporal neurons. PLoS Comput Biol 9:e1003167. 10.1371/journal.pcbi.1003167 - DOI - PMC - PubMed
Publication types
MeSH terms
LinkOut - more resources
Full Text Sources
Other Literature Sources