

Multitask learning and benchmarking with clinical time series data
- PMID: 31209213
- PMCID: PMC6572845
- DOI: 10.1038/s41597-019-0103-9
Multitask learning and benchmarking with clinical time series data
Abstract
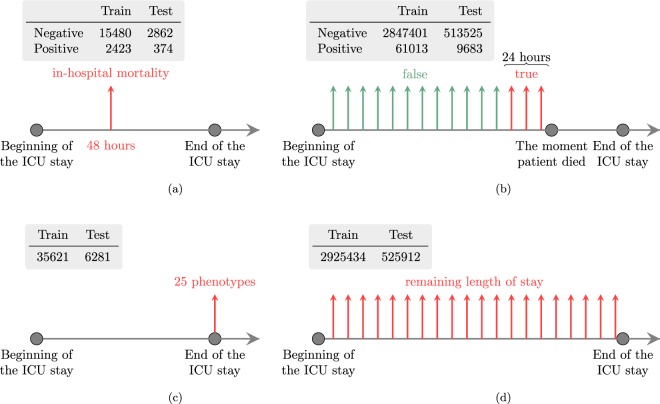
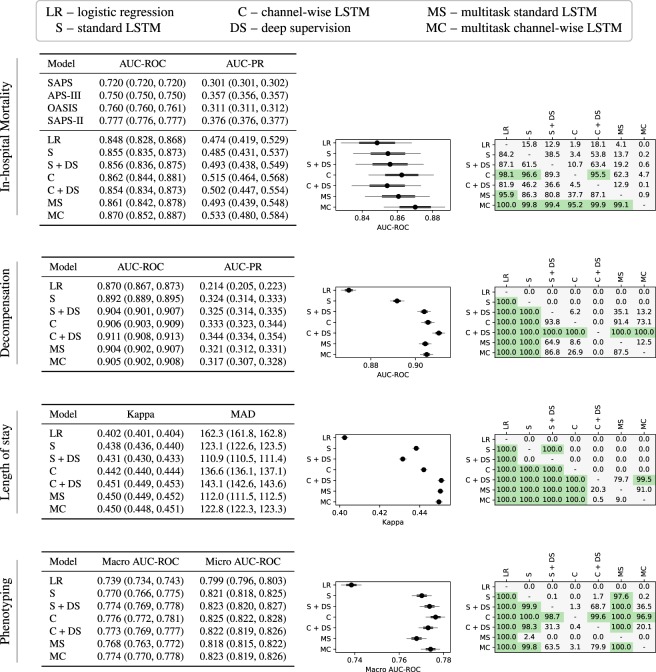
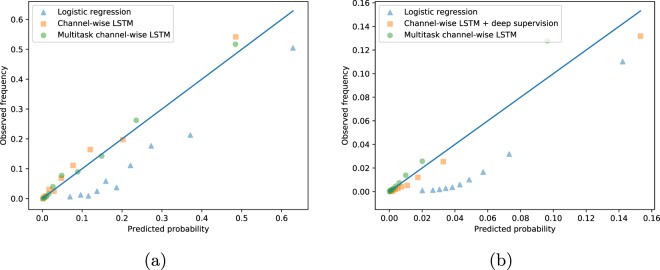
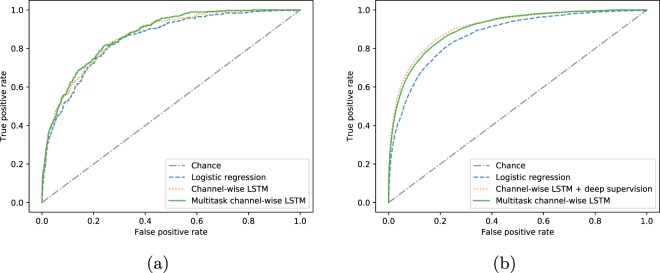
Health care is one of the most exciting frontiers in data mining and machine learning. Successful adoption of electronic health records (EHRs) created an explosion in digital clinical data available for analysis, but progress in machine learning for healthcare research has been difficult to measure because of the absence of publicly available benchmark data sets. To address this problem, we propose four clinical prediction benchmarks using data derived from the publicly available Medical Information Mart for Intensive Care (MIMIC-III) database. These tasks cover a range of clinical problems including modeling risk of mortality, forecasting length of stay, detecting physiologic decline, and phenotype classification. We propose strong linear and neural baselines for all four tasks and evaluate the effect of deep supervision, multitask training and data-specific architectural modifications on the performance of neural models.
Conflict of interest statement
The authors declare no competing interests.
Figures
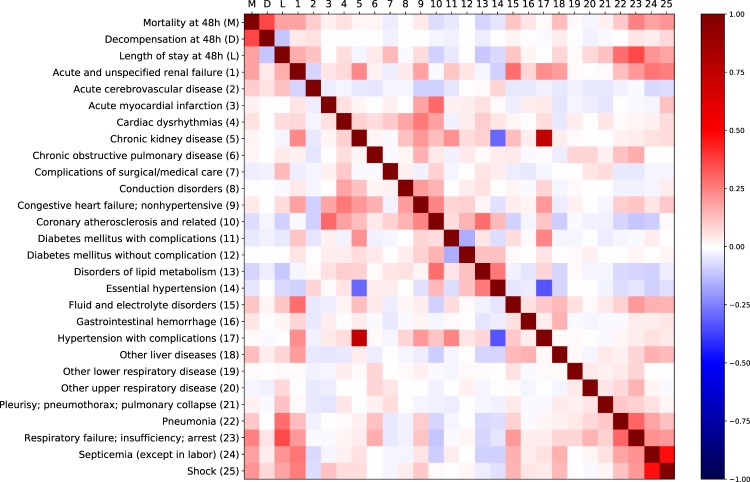
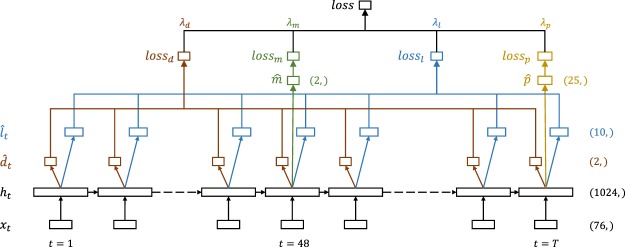
References
-
- Introduction to the HCUP National Inpatient Sample (NIS) 2012. (Agency for Healthcare Research and Quality, 2014).
-
- Henry, J., Pylypchuk, Y., Talisha Searcy, M. & Patel, V. Adoption of electronic health record systems among US non-federal acute care hospitals: 2008–2015. ONCData Brief35 (Office of the National Coordinator for Health Information Technology, Washington DC, USA, 2015).
-
- Williams, B. et al. National Early Warning Score (NEWS): Standardising the assessment of acute-illness severity in the NHS. (London: The Royal College of Physicians, 2012).
Publication types
MeSH terms
LinkOut - more resources
Full Text Sources
Other Literature Sources
Molecular Biology Databases
