

Forget binning and get SMART: Getting more out of the time-course of response data
- PMID: 31214973
- PMCID: PMC6856044
- DOI: 10.3758/s13414-019-01788-3
Forget binning and get SMART: Getting more out of the time-course of response data
Abstract
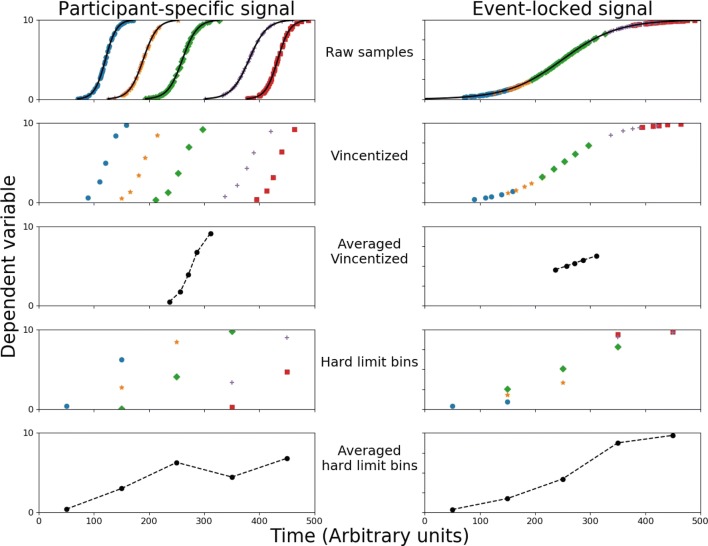
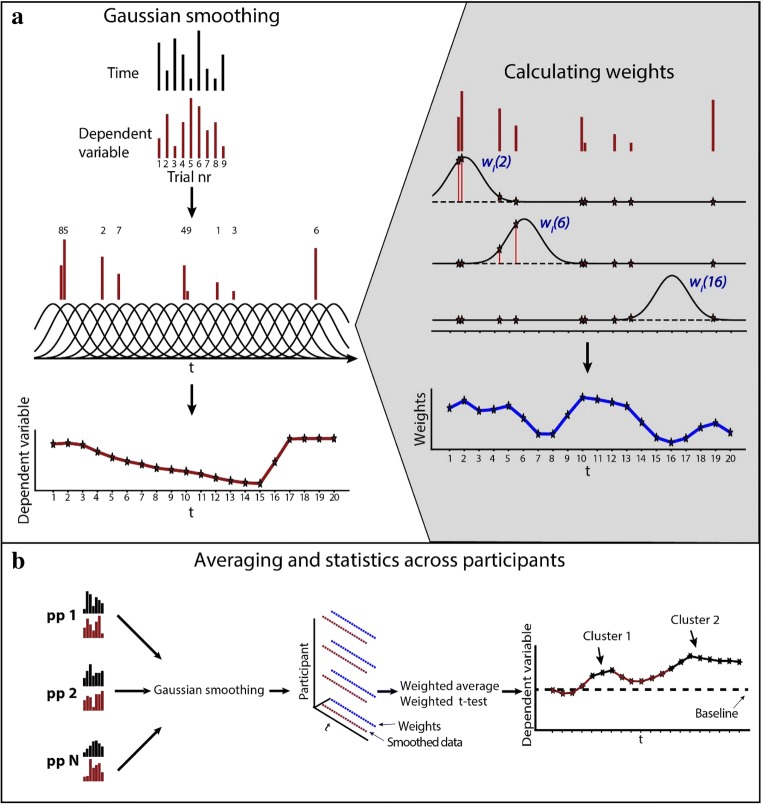
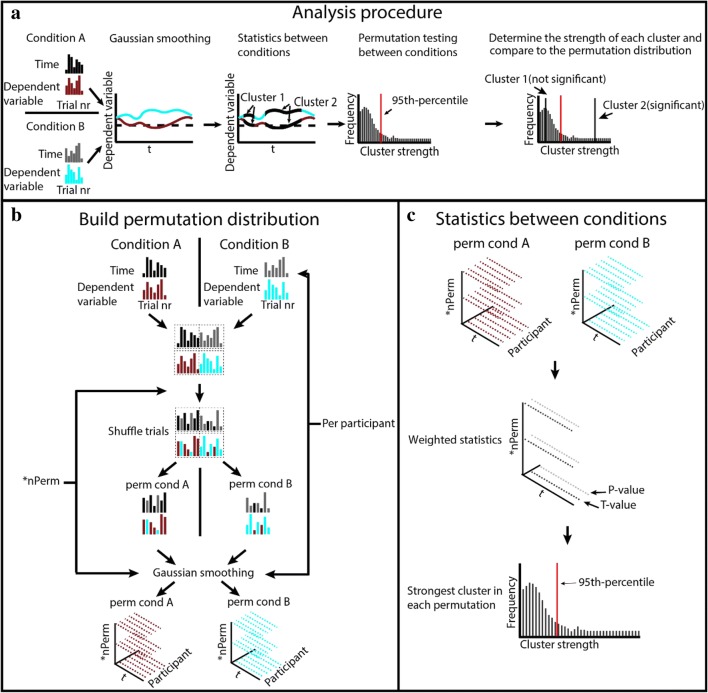
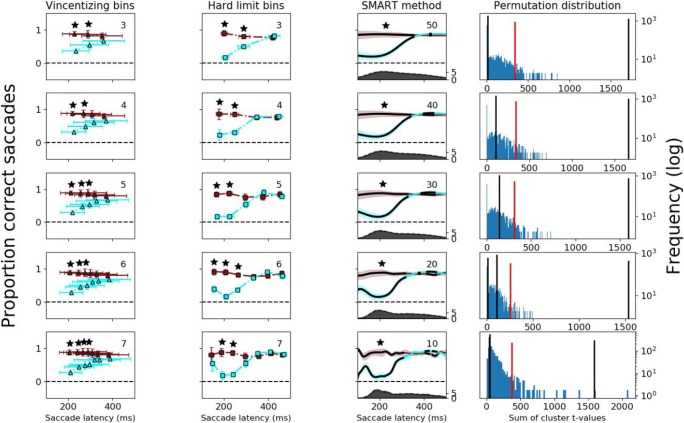
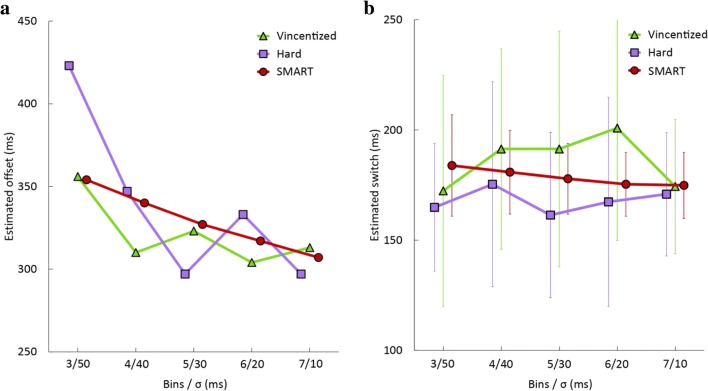
Many experiments aim to investigate the time-course of cognitive processes while measuring a single response per trial. A common first step in the analysis of such data is to divide them into a limited number of bins. As we demonstrate here, the way one chooses these bins can considerably influence the resulting time-course. As a solution to this problem, we here present the smoothing method for analysis of response time-course (SMART)-a complete package for reconstructing the time-course from one-sample-per-trial data and performing statistical analysis. After smoothing the data, the SMART weights the data based on the effective number of data points per participant. A cluster-based permutation test then determines at which moments the responses differ from a baseline or between two conditions. We show here that, in contrast to contemporary binning methods, the chosen temporal resolution has a negligible effect on the SMART reconstructed time-course. To facilitate its use, the SMART method, accompanied by a tutorial, is available as an open-source package.
Keywords: Binning; Perception and action; Reaction time methods; Statistics.
Figures

References
-
- Bullmore ET, Suckling J, Overmeyer S, Rabe-hesketh S, Taylor E, Brammer MJ. Global, voxel, and cluster tests, by theory and permutation, for a difference between two groups of structural mr images of the brain. IEEE Transactions on Medical Imaging. 1999;18(1):32–42. doi: 10.1109/42.750253. - DOI - PubMed
-
- Gatz DF, Smith L. The standard error of a weighted mean concentration—I. Bootstrapping vs other methods. Atmospheric Environment. 1995;29(11):1185–1193. doi: 10.1016/1352-2310(94)00210-C. - DOI
MeSH terms
Grants and funding
LinkOut - more resources
Full Text Sources
Research Materials
