

The resonant brain: How attentive conscious seeing regulates action sequences that interact with attentive cognitive learning, recognition, and prediction
- PMID: 31218601
- PMCID: PMC6848053
- DOI: 10.3758/s13414-019-01789-2
The resonant brain: How attentive conscious seeing regulates action sequences that interact with attentive cognitive learning, recognition, and prediction
Abstract
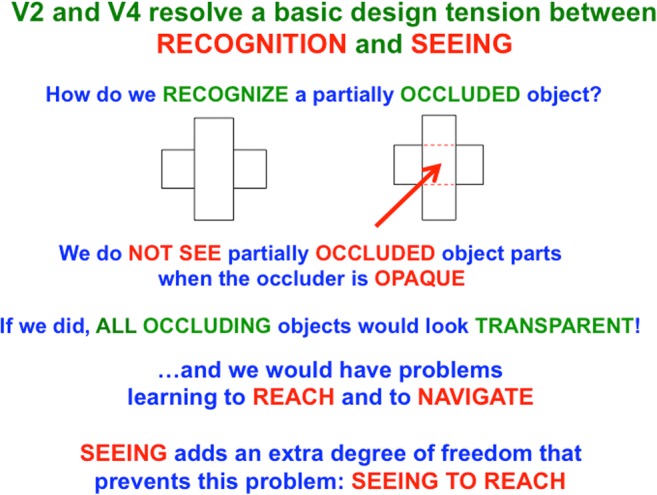
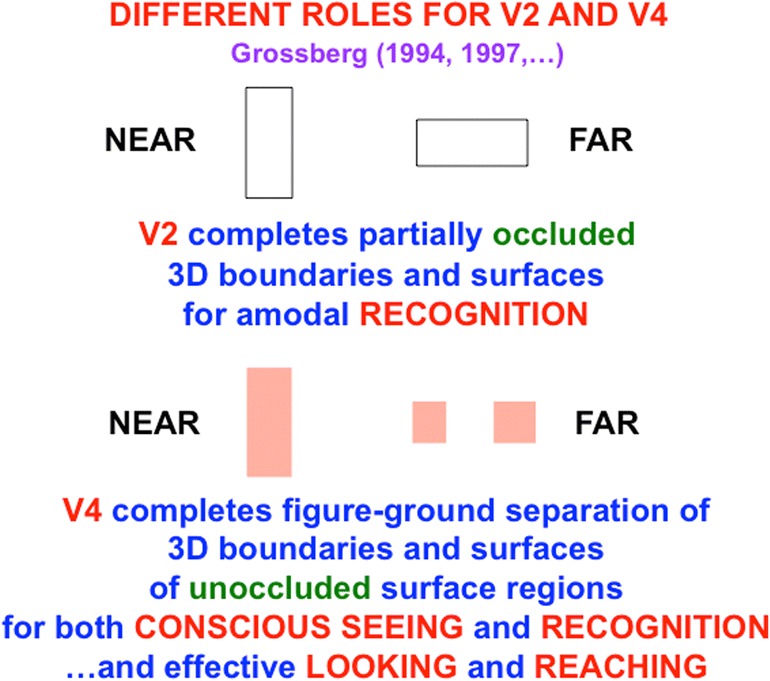
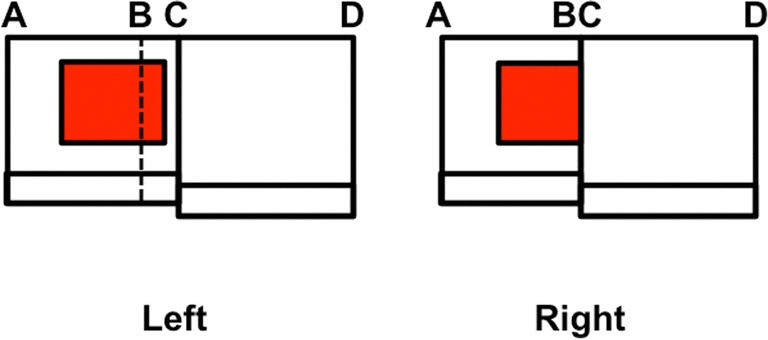
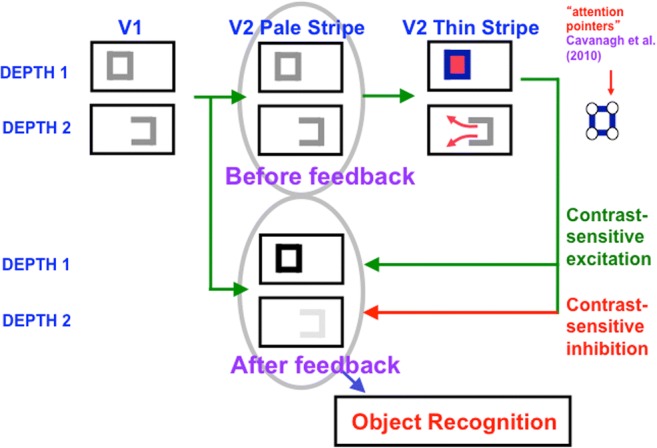
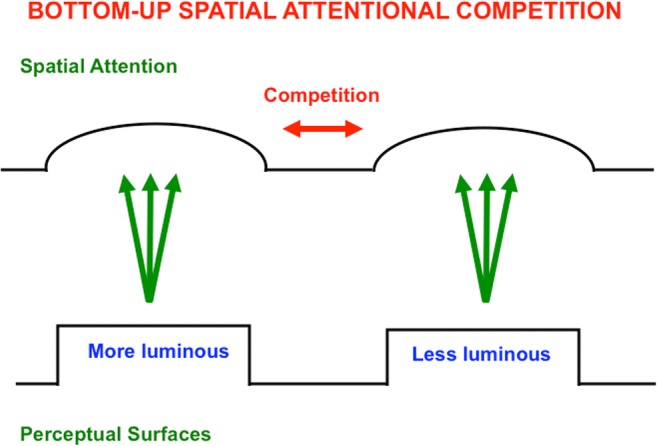
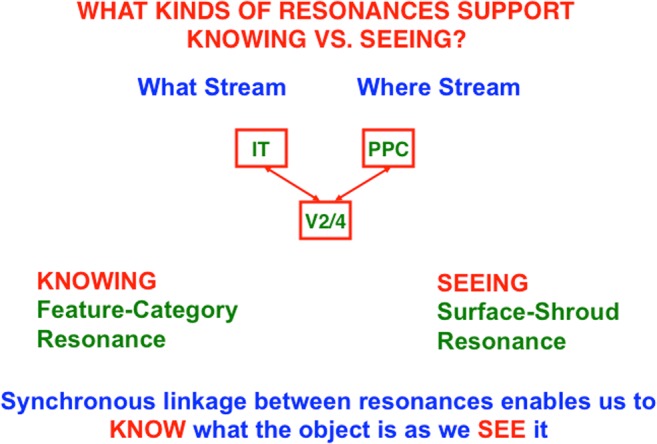
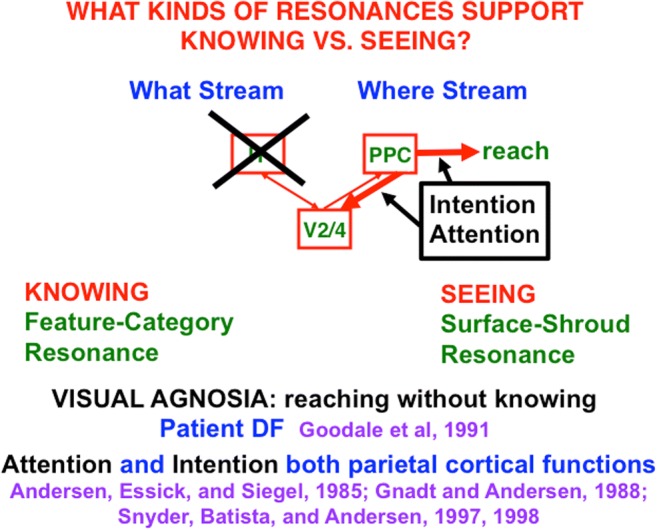
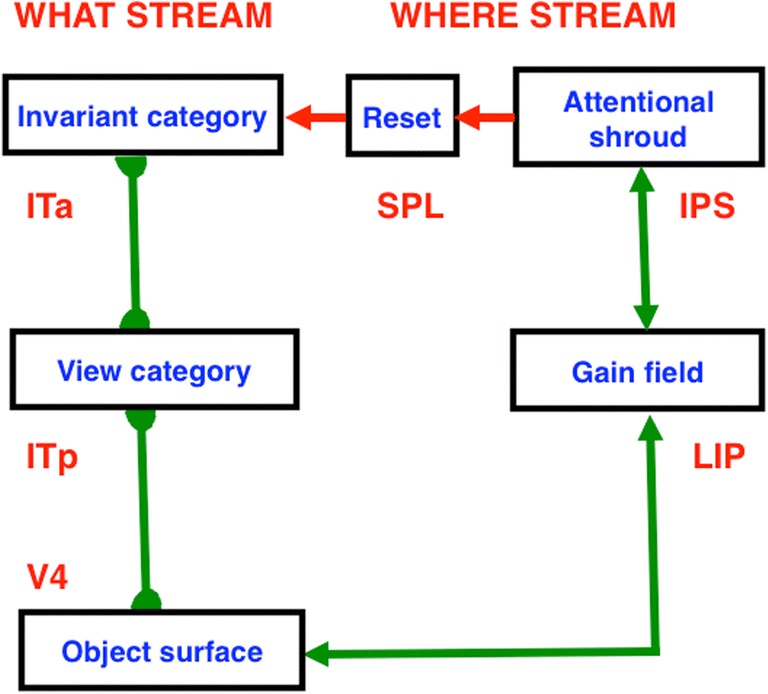
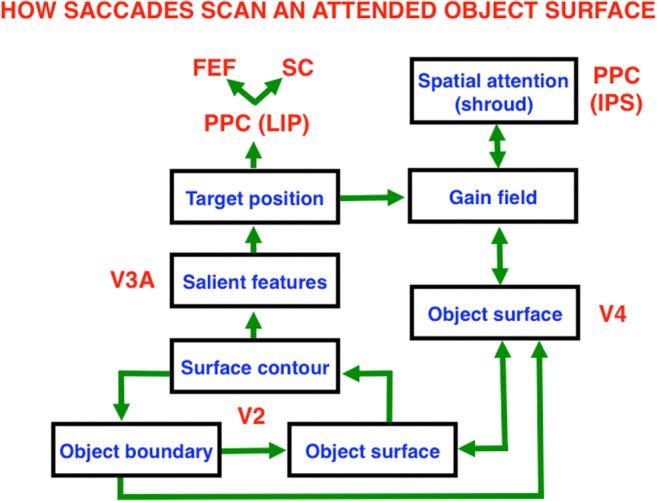
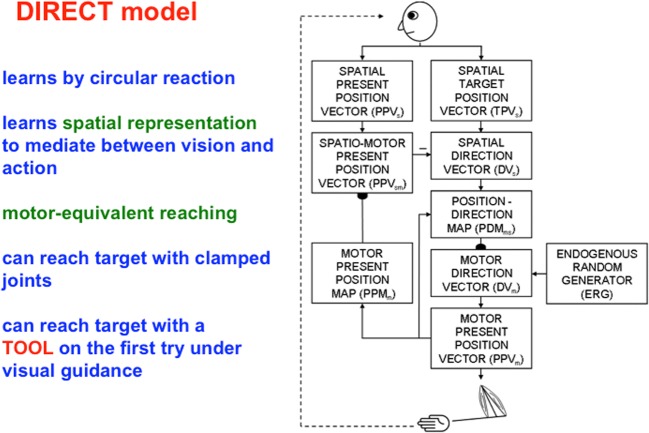
This article describes mechanistic links that exist in advanced brains between processes that regulate conscious attention, seeing, and knowing, and those that regulate looking and reaching. These mechanistic links arise from basic properties of brain design principles such as complementary computing, hierarchical resolution of uncertainty, and adaptive resonance. These principles require conscious states to mark perceptual and cognitive representations that are complete, context sensitive, and stable enough to control effective actions. Surface-shroud resonances support conscious seeing and action, whereas feature-category resonances support learning, recognition, and prediction of invariant object categories. Feedback interactions between cortical areas such as peristriate visual cortical areas V2, V3A, and V4, and the lateral intraparietal area (LIP) and inferior parietal sulcus (IPS) of the posterior parietal cortex (PPC) control sequences of saccadic eye movements that foveate salient features of attended objects and thereby drive invariant object category learning. Learned categories can, in turn, prime the objects and features that are attended and searched. These interactions coordinate processes of spatial and object attention, figure-ground separation, predictive remapping, invariant object category learning, and visual search. They create a foundation for learning to control motor-equivalent arm movement sequences, and for storing these sequences in cognitive working memories that can trigger the learning of cognitive plans with which to read out skilled movement sequences. Cognitive-emotional interactions that are regulated by reinforcement learning can then help to select the plans that control actions most likely to acquire valued goal objects in different situations. Many interdisciplinary psychological and neurobiological data about conscious and unconscious behaviors in normal individuals and clinical patients have been explained in terms of these concepts and mechanisms.
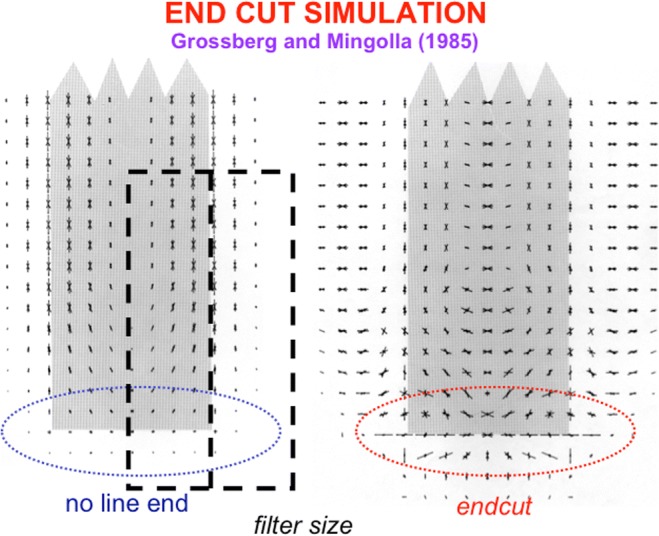
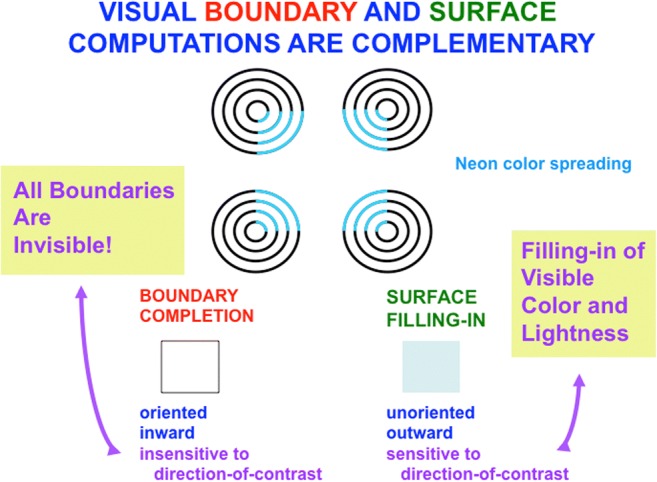
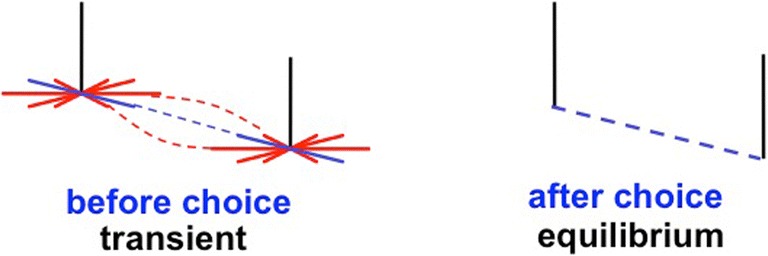
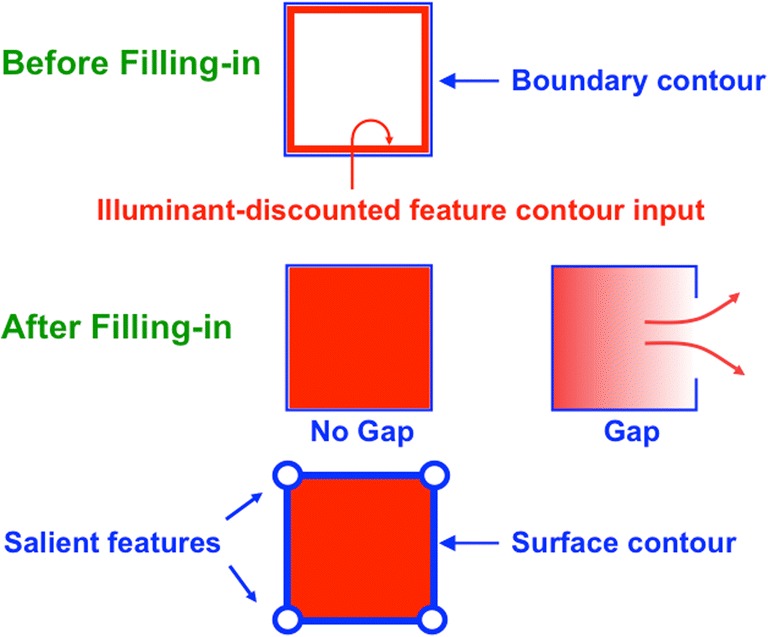
Keywords: Adaptive resonance; Arm movement; Boundary completion; Cognitive plan; Cognitive working memory; Complementary computing; Consciousness; Feature–category resonance; Figure–ground separation; Hierarchical resolution of uncertainty; IPS; Invariant object category learning; LIP; Movement sequences; Neon color spreading; Object attention; PFC; PPC; Saccadic eye movement; Spatial attention; Surface filling-in; Surface–shroud resonance; V2; V3A; V4.
Figures









References
-
- Andersen RA, Brotchie PR, Mazzoni P. Evidence for the lateral intraparietal area as the parietal eye field. Current Opinion in Neurobiology. 1992;2:840–846. - PubMed
-
- Andersen RA, Essick GK, Siegel RM. Encoding of spatial location by posterior parietal neurons. Science. 1985;230:456–458. - PubMed
-
- Andersen RA, Essick GK, Siegel RM. Neurons of area 7 activated by both visual stimuli and oculomotor behavior. Experimental Brain Research. 1987;67:316–322. - PubMed
-
- Andersen RA, Snyder LH, Batista AP, Buneo CA, Cohen YE. Posterior parietal areas specialized for eye movements (LIP) and reach (PRR) using a common coordinate frame. In: Bock GR, Goode JA, editors. Sensory guidance of movement (Novartis Foundation Symposium 218) Chichester, UK: Wiley; 1998. pp. 109–128. - PubMed
MeSH terms
LinkOut - more resources
Full Text Sources
Miscellaneous
