

The Encoding of Speech Sounds in the Superior Temporal Gyrus
- PMID: 31220442
- PMCID: PMC6602075
- DOI: 10.1016/j.neuron.2019.04.023
The Encoding of Speech Sounds in the Superior Temporal Gyrus
Abstract
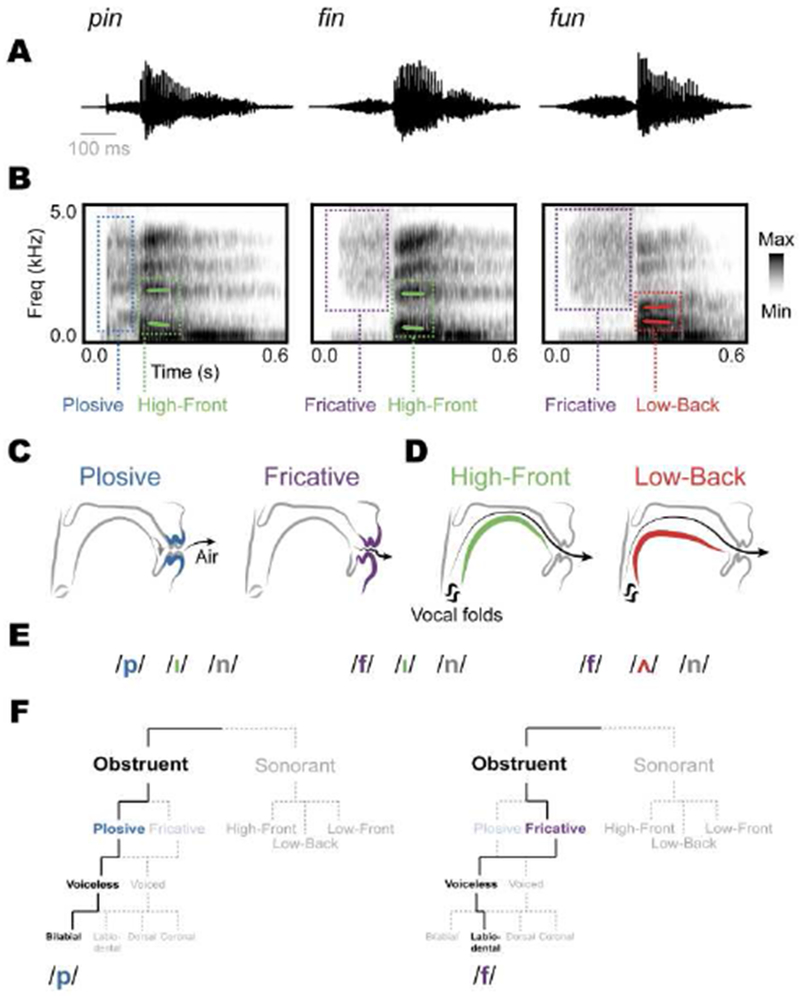
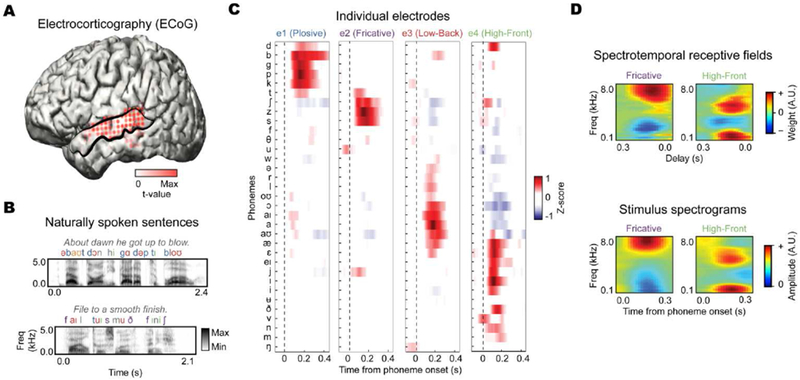
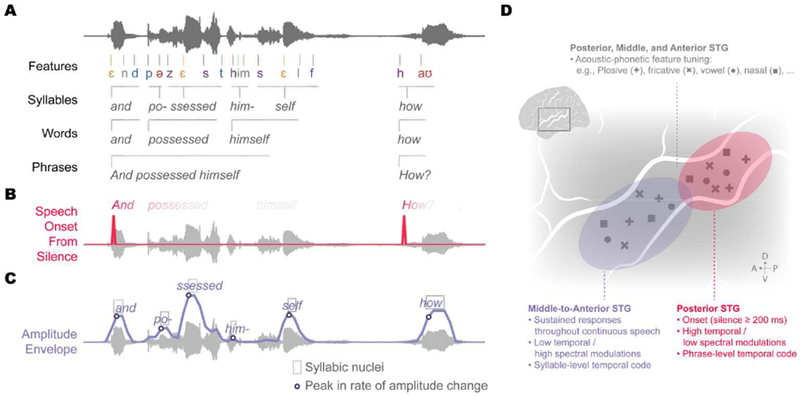
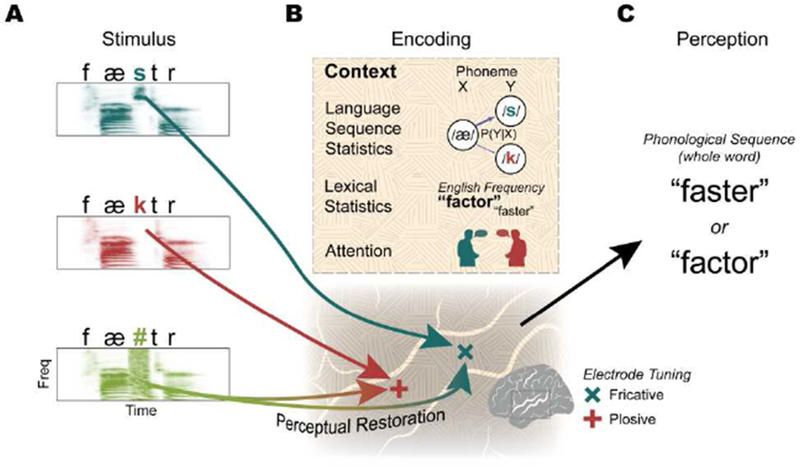
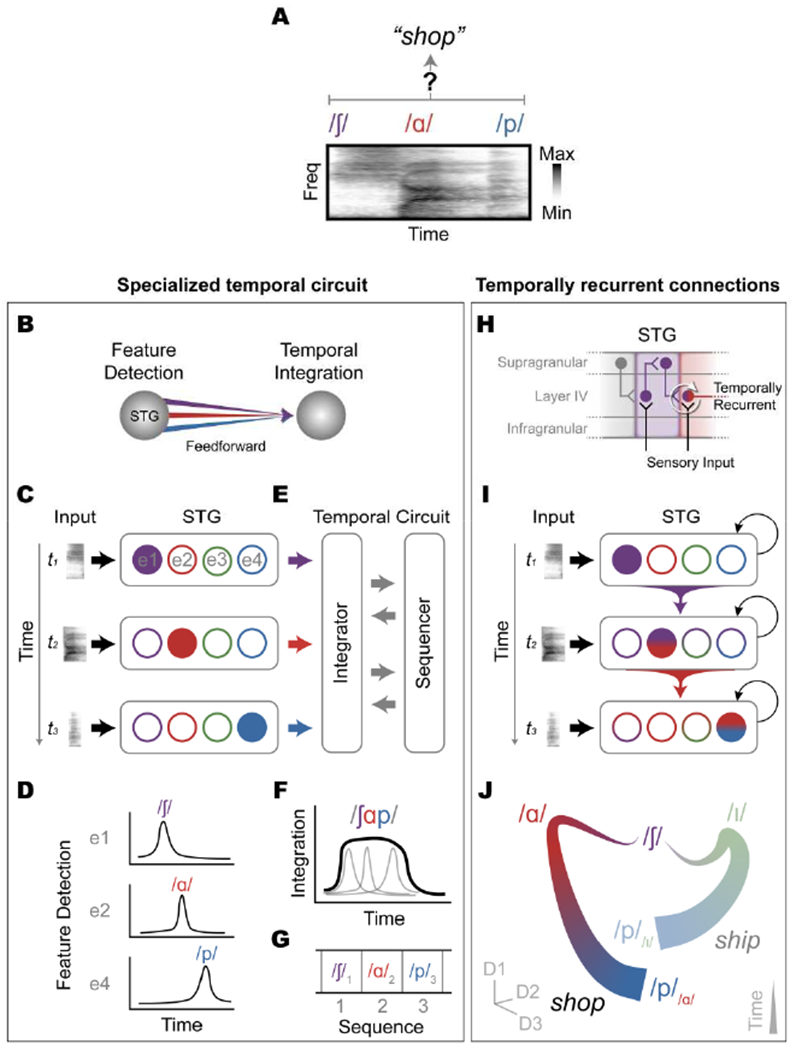
The human superior temporal gyrus (STG) is critical for extracting meaningful linguistic features from speech input. Local neural populations are tuned to acoustic-phonetic features of all consonants and vowels and to dynamic cues for intonational pitch. These populations are embedded throughout broader functional zones that are sensitive to amplitude-based temporal cues. Beyond speech features, STG representations are strongly modulated by learned knowledge and perceptual goals. Currently, a major challenge is to understand how these features are integrated across space and time in the brain during natural speech comprehension. We present a theory that temporally recurrent connections within STG generate context-dependent phonological representations, spanning longer temporal sequences relevant for coherent percepts of syllables, words, and phrases.
Keywords: acoustic-phonetic features; auditory cortex; context-dependent representation; electrocorticography; phonological sequence; speech processing; superior temporal gyrus; temporal integration; temporal landmarks; temporally recurrent connections.
Copyright © 2019 Elsevier Inc. All rights reserved.
Figures
References
-
- Baddeley A (1992). Working memory. Science, 255(5044), 556–559. - PubMed
