

Essential guidelines for computational method benchmarking
- PMID: 31221194
- PMCID: PMC6584985
- DOI: 10.1186/s13059-019-1738-8
Essential guidelines for computational method benchmarking
Abstract
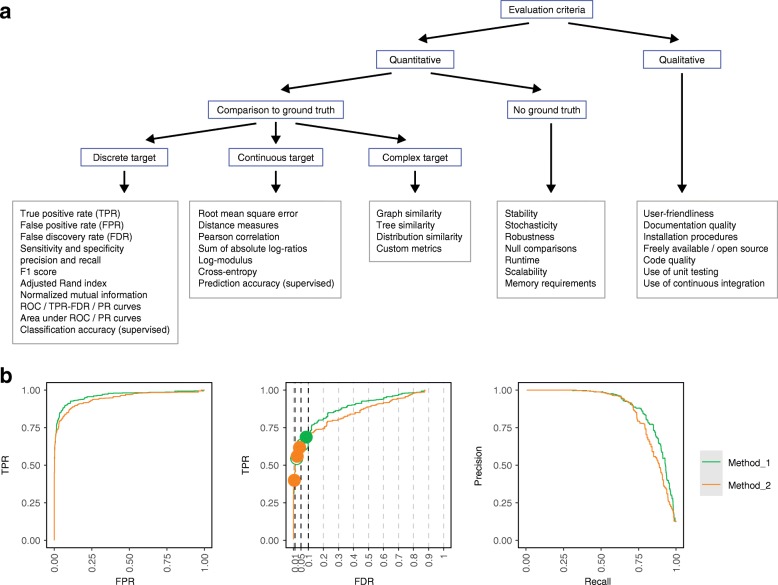
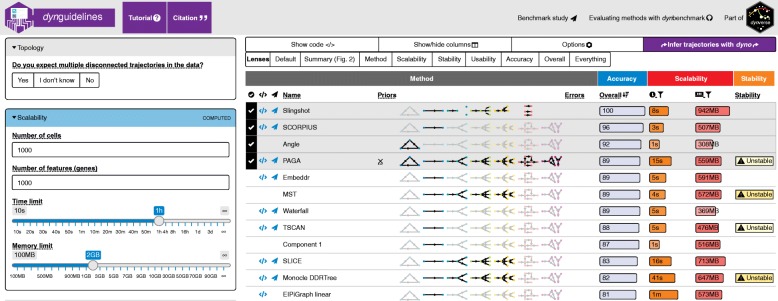
In computational biology and other sciences, researchers are frequently faced with a choice between several computational methods for performing data analyses. Benchmarking studies aim to rigorously compare the performance of different methods using well-characterized benchmark datasets, to determine the strengths of each method or to provide recommendations regarding suitable choices of methods for an analysis. However, benchmarking studies must be carefully designed and implemented to provide accurate, unbiased, and informative results. Here, we summarize key practical guidelines and recommendations for performing high-quality benchmarking analyses, based on our experiences in computational biology.
Conflict of interest statement
The authors declare that they have no competing interests.
Figures

References
Publication types
MeSH terms
LinkOut - more resources
Full Text Sources
Molecular Biology Databases
