

Skeletal descriptions of shape provide unique perceptual information for object recognition
- PMID: 31249321
- PMCID: PMC6597715
- DOI: 10.1038/s41598-019-45268-y
Skeletal descriptions of shape provide unique perceptual information for object recognition
Abstract
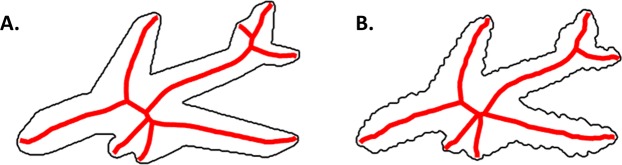
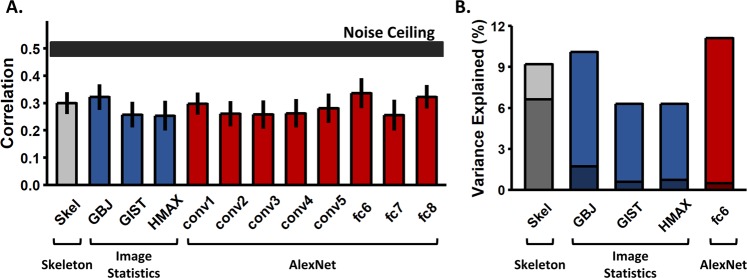
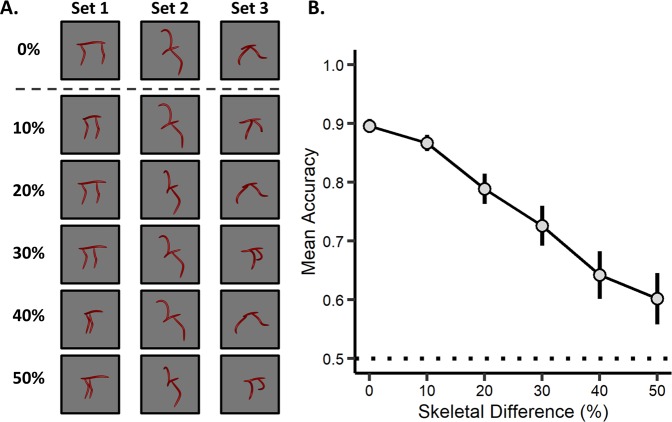
With seemingly little effort, humans can both identify an object across large changes in orientation and extend category membership to novel exemplars. Although researchers argue that object shape is crucial in these cases, there are open questions as to how shape is represented for object recognition. Here we tested whether the human visual system incorporates a three-dimensional skeletal descriptor of shape to determine an object's identity. Skeletal models not only provide a compact description of an object's global shape structure, but also provide a quantitative metric by which to compare the visual similarity between shapes. Our results showed that a model of skeletal similarity explained the greatest amount of variance in participants' object dissimilarity judgments when compared with other computational models of visual similarity (Experiment 1). Moreover, parametric changes to an object's skeleton led to proportional changes in perceived similarity, even when controlling for another model of structure (Experiment 2). Importantly, participants preferentially categorized objects by their skeletons across changes to local shape contours and non-accidental properties (Experiment 3). Our findings highlight the importance of skeletal structure in vision, not only as a shape descriptor, but also as a diagnostic cue of object identity.
Conflict of interest statement
The authors declare no competing interests.
Figures



References
MeSH terms
LinkOut - more resources
Full Text Sources
