

Discovery of food identity markers by metabolomics and machine learning technology
- PMID: 31273246
- PMCID: PMC6609671
- DOI: 10.1038/s41598-019-46113-y
Discovery of food identity markers by metabolomics and machine learning technology
Abstract
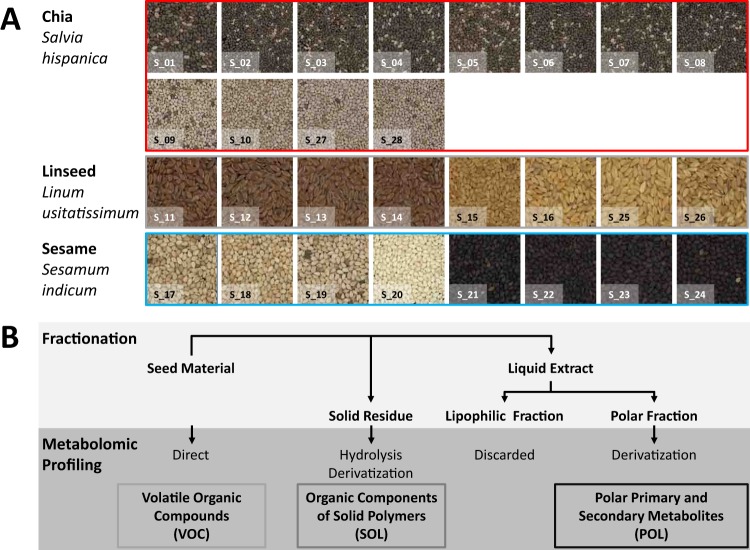
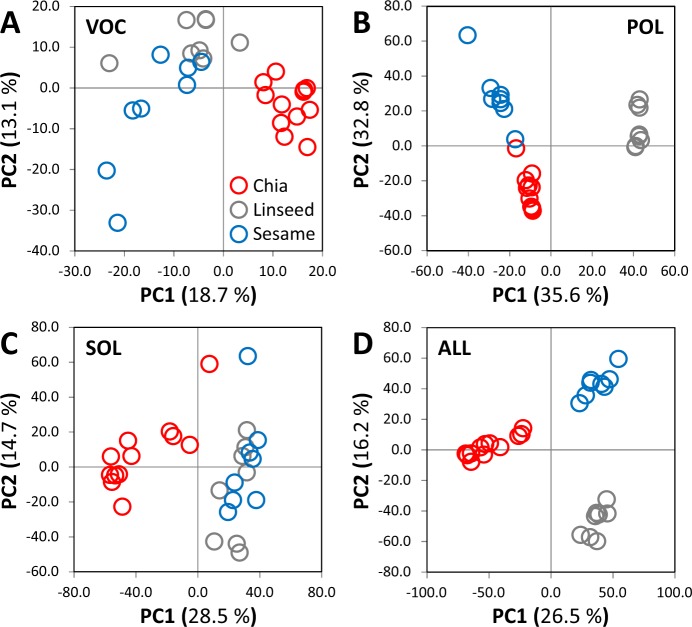
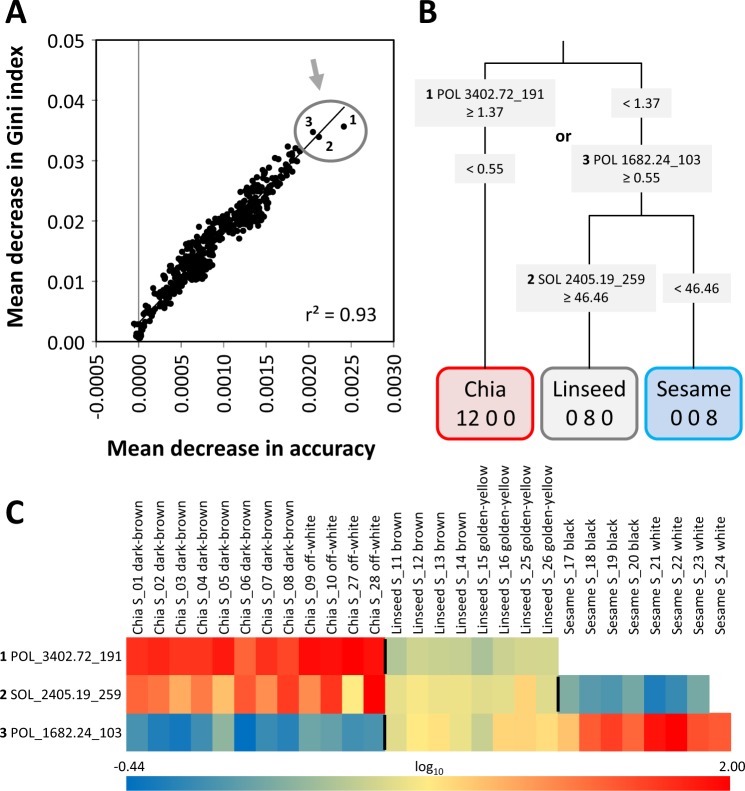
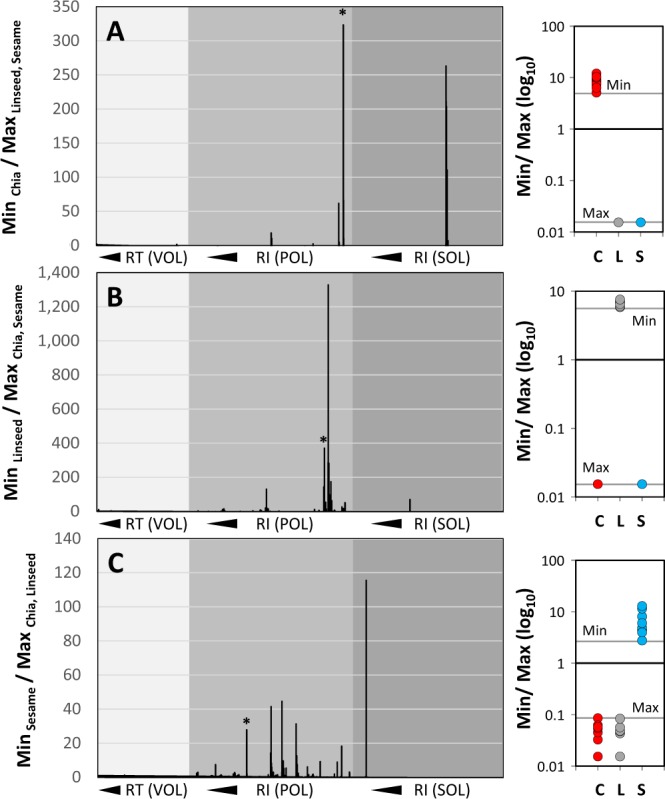
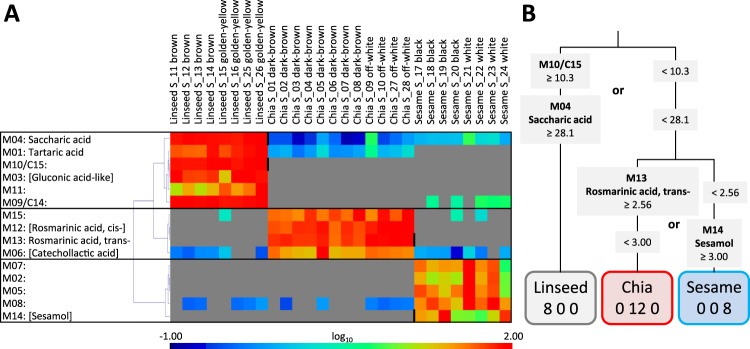
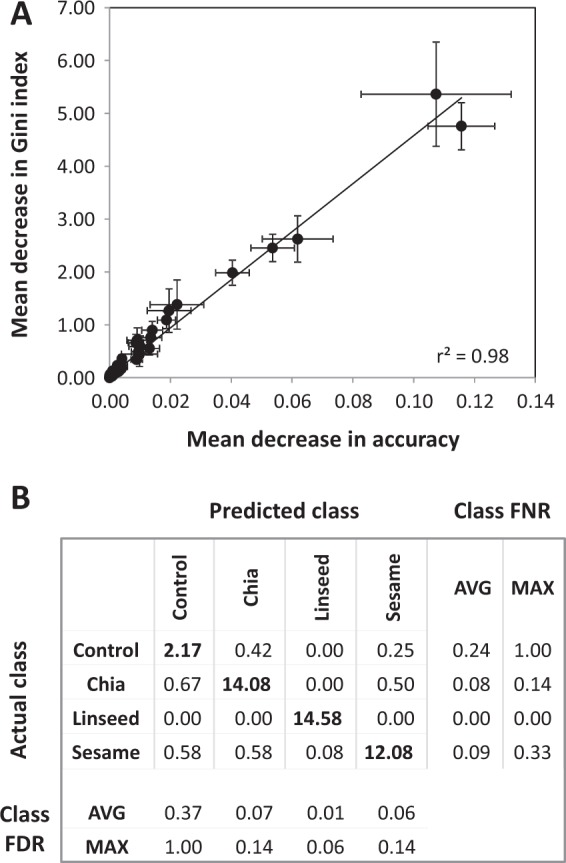
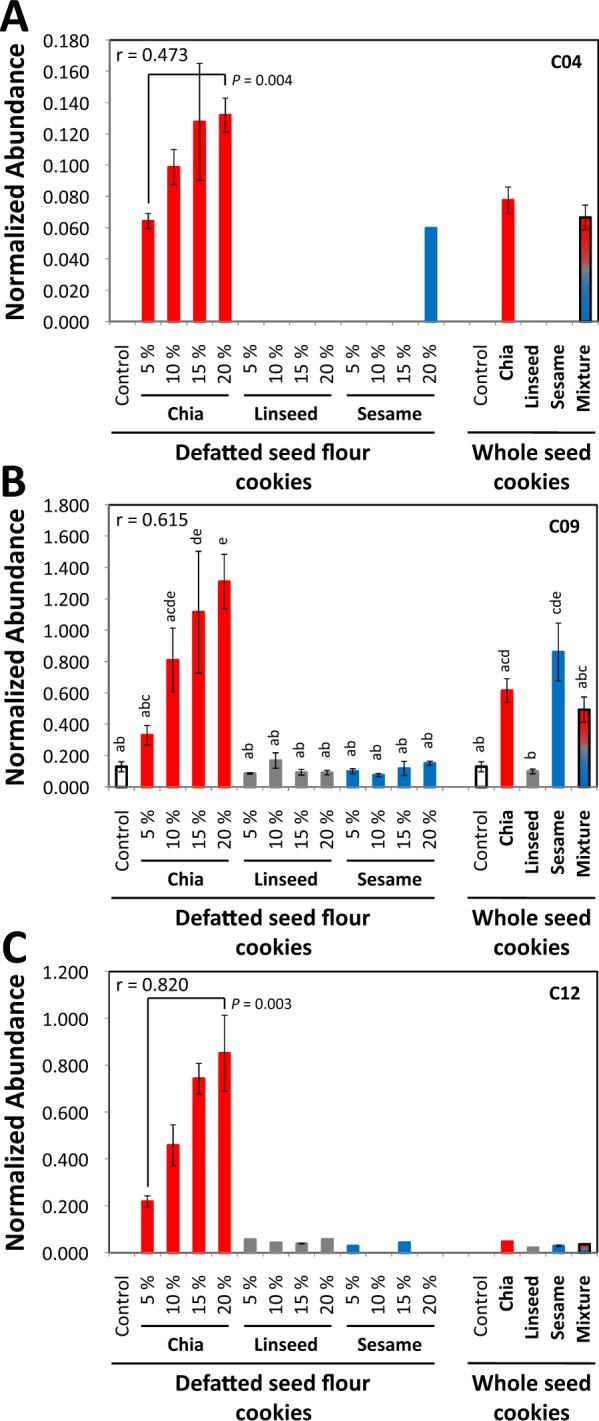
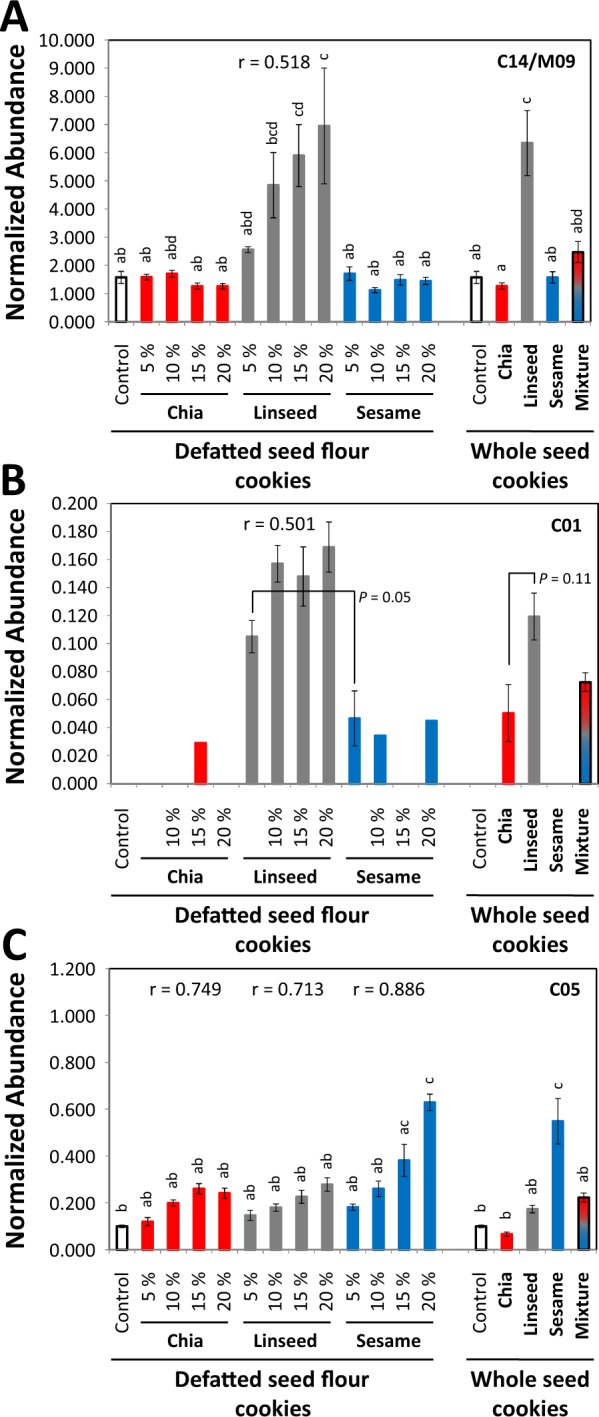
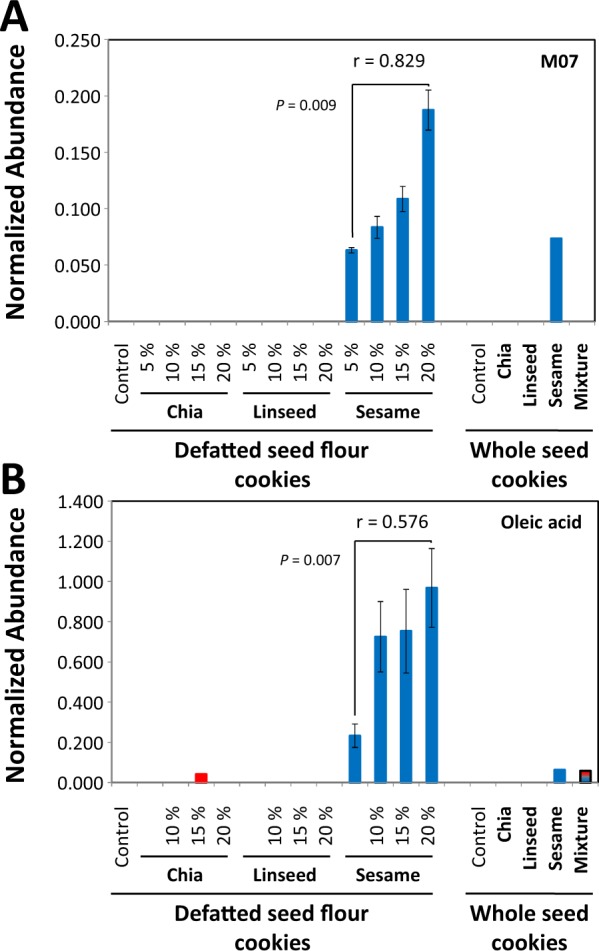
Verification of food authenticity establishes consumer trust in food ingredients and components of processed food. Next to genetic or protein markers, chemicals are unique identifiers of food components. Non-targeted metabolomics is ideally suited to screen food markers when coupled to efficient data analysis. This study explored feasibility of random forest (RF) machine learning, specifically its inherent feature extraction for non-targeted metabolic marker discovery. The distinction of chia, linseed, and sesame that have gained attention as "superfoods" served as test case. Chemical fractions of non-processed seeds and of wheat cookies with seed ingredients were profiled. RF technology classified original seeds unambiguously but appeared overdesigned for material with unique secondary metabolites, like sesamol or rosmarinic acid in the Lamiaceae, chia. Most unique metabolites were diluted or lost during cookie production but RF technology classified the presence of the seed ingredients in cookies with 6.7% overall error and revealed food processing markers, like 4-hydroxybenzaldehyde for chia and succinic acid monomethylester for linseed additions. RF based feature extraction was adequate for difficult classifications but marker selection should not be without human supervision. Combination with alternative data analysis technologies is advised and further testing of a wide range of seeds and food processing methods.
Conflict of interest statement
The authors declare no competing interests.
Figures
Similar articles
-
Targeted metabolomics to assess the authenticity of bakery products containing chia, sesame and flax seeds.Food Chem. 2020 May 15;312:126059. doi: 10.1016/j.foodchem.2019.126059. Epub 2019 Dec 18. Food Chem. 2020. PMID: 31896449
-
Identification of chia, flax and sesame seeds authenticity markers by NMR-based untargeted metabolomics and their validation in bakery products containing them.Food Chem. 2022 Sep 1;387:132925. doi: 10.1016/j.foodchem.2022.132925. Epub 2022 Apr 9. Food Chem. 2022. PMID: 35429933
-
Comparative metabolite fingerprinting of chia, flax and sesame seeds using LC-MS untargeted metabolomics.Food Chem. 2022 Mar 1;371:131355. doi: 10.1016/j.foodchem.2021.131355. Epub 2021 Oct 7. Food Chem. 2022. PMID: 34808769
-
Chia seeds: an ancient grain trending in modern human diets.Food Funct. 2019 Jun 19;10(6):3068-3089. doi: 10.1039/c9fo00239a. Food Funct. 2019. PMID: 31086922 Review.
-
Clinical evidence on dietary supplementation with chia seed (Salvia hispanica L.): a systematic review and meta-analysis.Nutr Rev. 2018 Apr 1;76(4):219-242. doi: 10.1093/nutrit/nux071. Nutr Rev. 2018. PMID: 29452425
Cited by
-
Opening the Random Forest Black Box of the Metabolome by the Application of Surrogate Minimal Depth.Metabolites. 2021 Dec 21;12(1):5. doi: 10.3390/metabo12010005. Metabolites. 2021. PMID: 35050127 Free PMC article.
-
Dysregulation of amino acids and lipids metabolism in schizophrenia with violence.BMC Psychiatry. 2020 Mar 4;20(1):97. doi: 10.1186/s12888-020-02499-y. BMC Psychiatry. 2020. PMID: 32131778 Free PMC article.
-
Comparative Metabolomics and Molecular Phylogenetics of Melon (Cucumis melo, Cucurbitaceae) Biodiversity.Metabolites. 2020 Mar 24;10(3):121. doi: 10.3390/metabo10030121. Metabolites. 2020. PMID: 32213984 Free PMC article.
-
Metabolomics for origin traceability of lamb: An ensemble learning approach based on random forest recursive feature elimination.Food Chem X. 2025 Aug 1;29:102856. doi: 10.1016/j.fochx.2025.102856. eCollection 2025 Jul. Food Chem X. 2025. PMID: 40799190 Free PMC article.
-
Application of a comprehensive metabolomics approach for the selection of flaxseed varieties with the highest nutritional and medicinal attributes.J Food Drug Anal. 2021 Jun 15;29(2):214-239. doi: 10.38212/2224-6614.3347. J Food Drug Anal. 2021. PMID: 35696216 Free PMC article.
References
-
- Kelly S, Heaton K, Hoogewerff J. Tracing the geographical origin of food: The application of multi-element and multi-isotope analysis. Trends in Food Science and Technology. 2005;16:555–567. doi: 10.1016/j.tifs.2005.08.008. - DOI
-
- Sforza, S. Food authentication using bioorganic molecules. DEStech Publications, Lancaster, PA, USA. ISBN: 978-1-60595-045-7 (2013).
-
- De la Guardia, M. & Gonzalvez, A. Food protected designation of origin: Methodologies and applications. Comprehensive Analytical Chemistry Vol. 60. Elsevier Publications, Oxford, UK. ISBN: 978-0-444-59562-1 (2013).
Publication types
MeSH terms
Substances
LinkOut - more resources
Full Text Sources
Other Literature Sources
Molecular Biology Databases
