

Stable Representations of Decision Variables for Flexible Behavior
- PMID: 31280924
- PMCID: PMC7169950
- DOI: 10.1016/j.neuron.2019.06.001
Stable Representations of Decision Variables for Flexible Behavior
Abstract
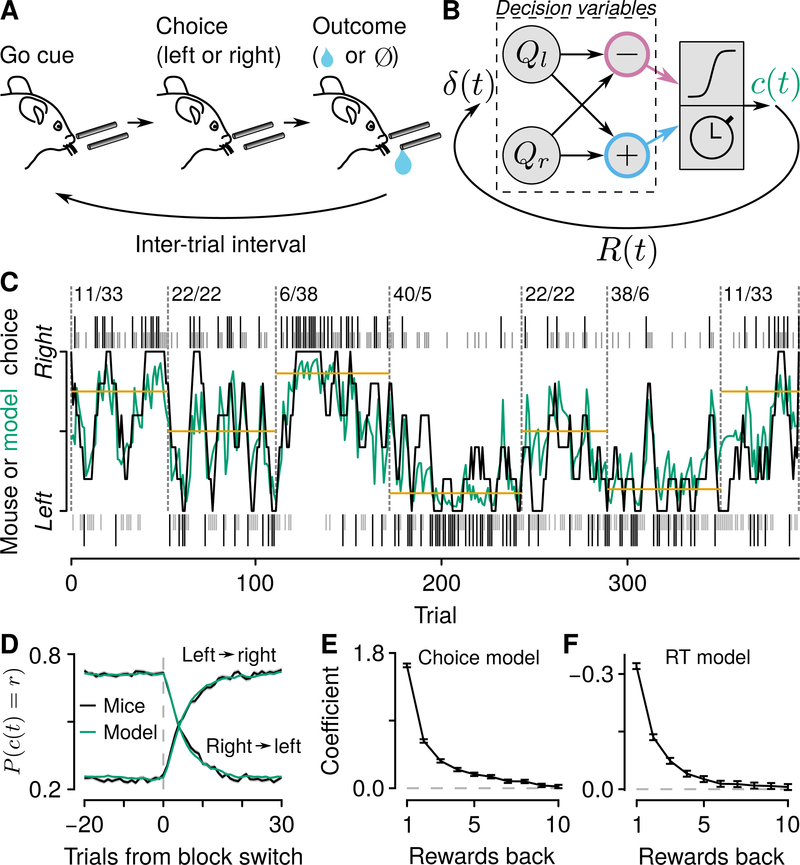
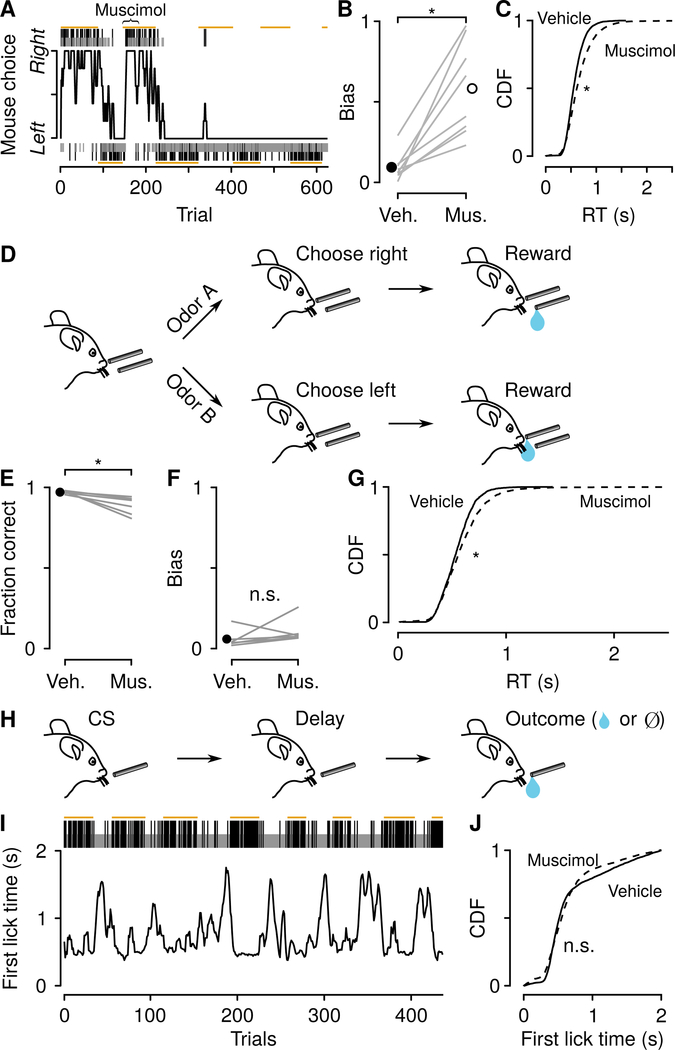
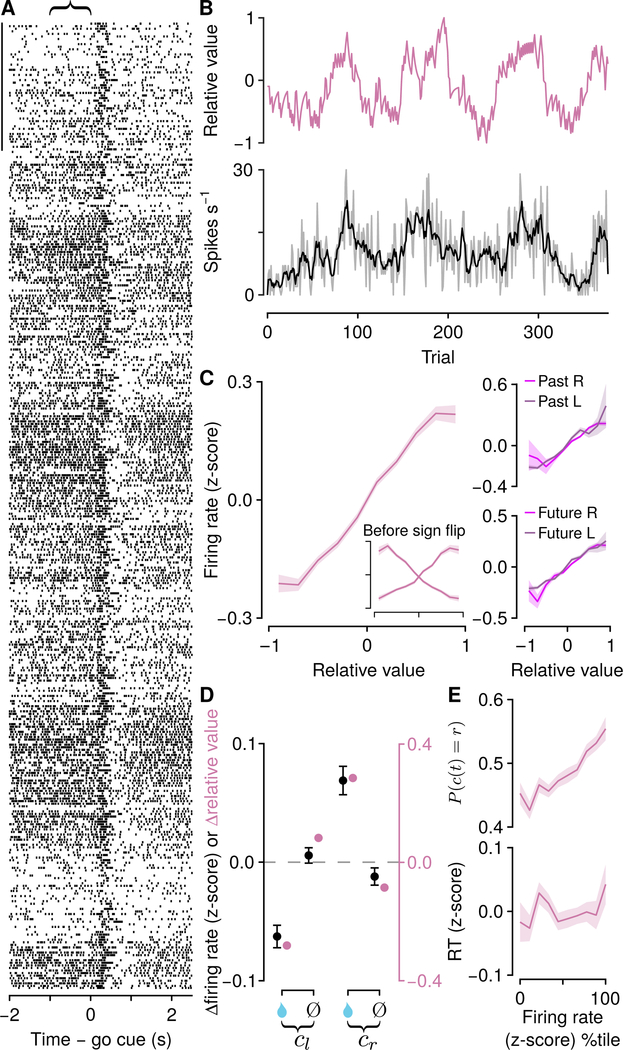
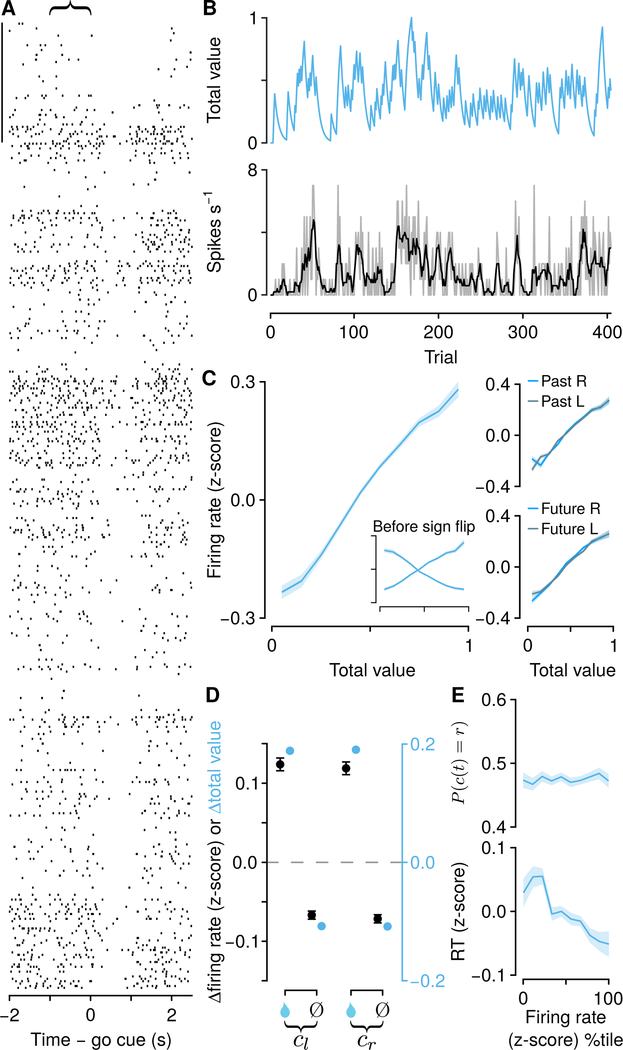
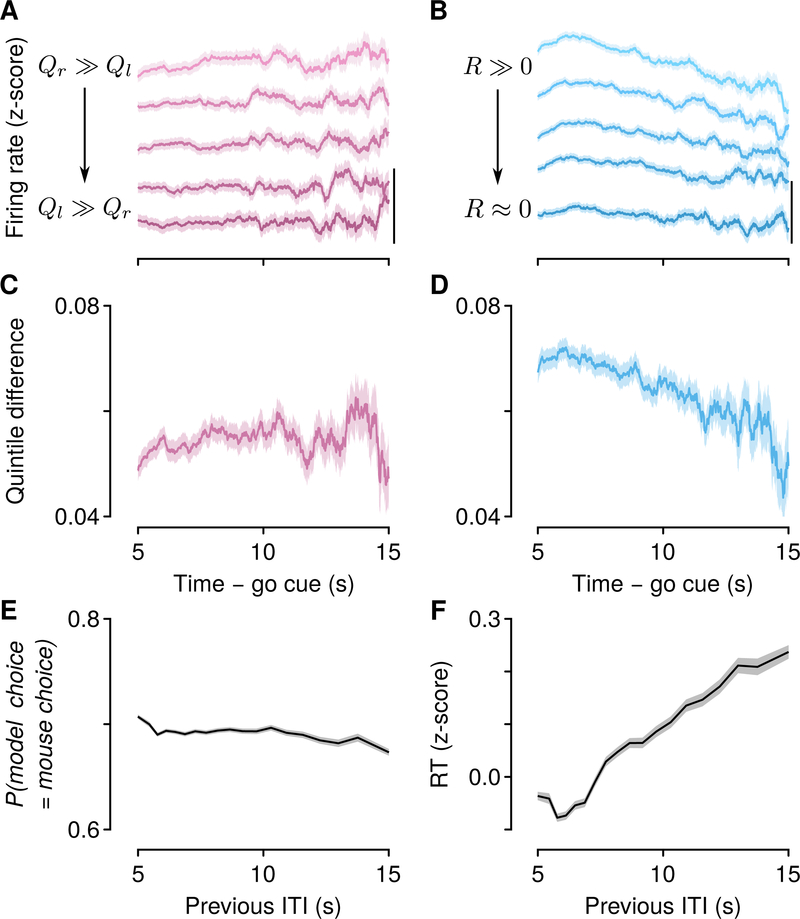
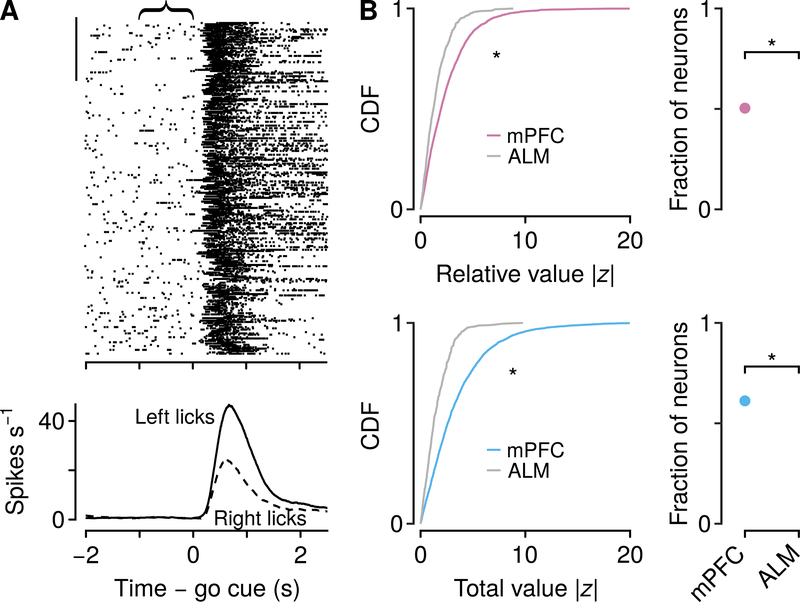
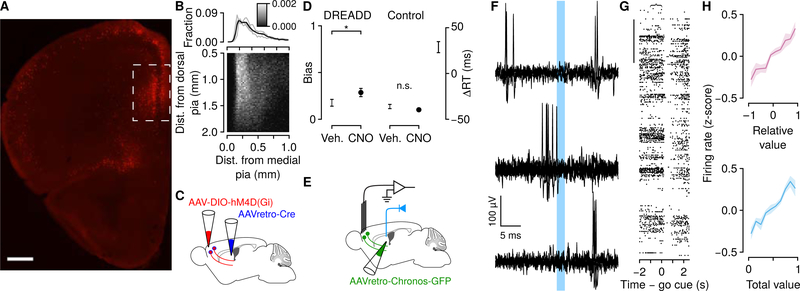
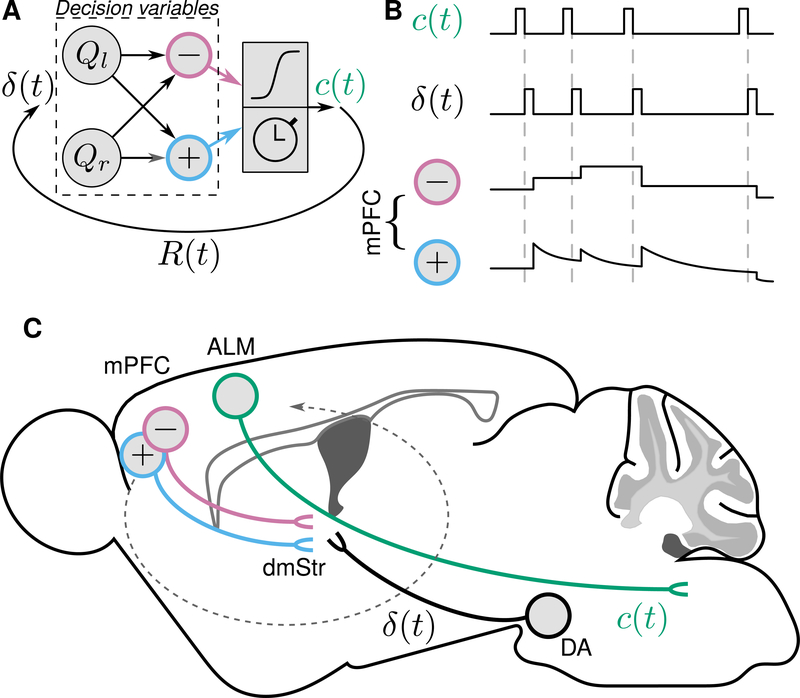
Decisions occur in dynamic environments. In the framework of reinforcement learning, the probability of performing an action is influenced by decision variables. Discrepancies between predicted and obtained rewards (reward prediction errors) update these variables, but they are otherwise stable between decisions. Although reward prediction errors have been mapped to midbrain dopamine neurons, it is unclear how the brain represents decision variables themselves. We trained mice on a dynamic foraging task in which they chose between alternatives that delivered reward with changing probabilities. Neurons in the medial prefrontal cortex, including projections to the dorsomedial striatum, maintained persistent firing rate changes over long timescales. These changes stably represented relative action values (to bias choices) and total action values (to bias response times) with slow decay. In contrast, decision variables were weakly represented in the anterolateral motor cortex, a region necessary for generating choices. Thus, we define a stable neural mechanism to drive flexible behavior.
Copyright © 2019 Elsevier Inc. All rights reserved.
Figures
Comment in
-
The Value of Persistent Value.Neuron. 2019 Sep 4;103(5):757-758. doi: 10.1016/j.neuron.2019.08.018. Neuron. 2019. PMID: 31487525
References
Publication types
MeSH terms
Grants and funding
LinkOut - more resources
Full Text Sources
Molecular Biology Databases
Research Materials
