

The community structure of functional brain networks exhibits scale-specific patterns of inter- and intra-subject variability
- PMID: 31291606
- PMCID: PMC7734597
- DOI: 10.1016/j.neuroimage.2019.07.003
The community structure of functional brain networks exhibits scale-specific patterns of inter- and intra-subject variability
Abstract
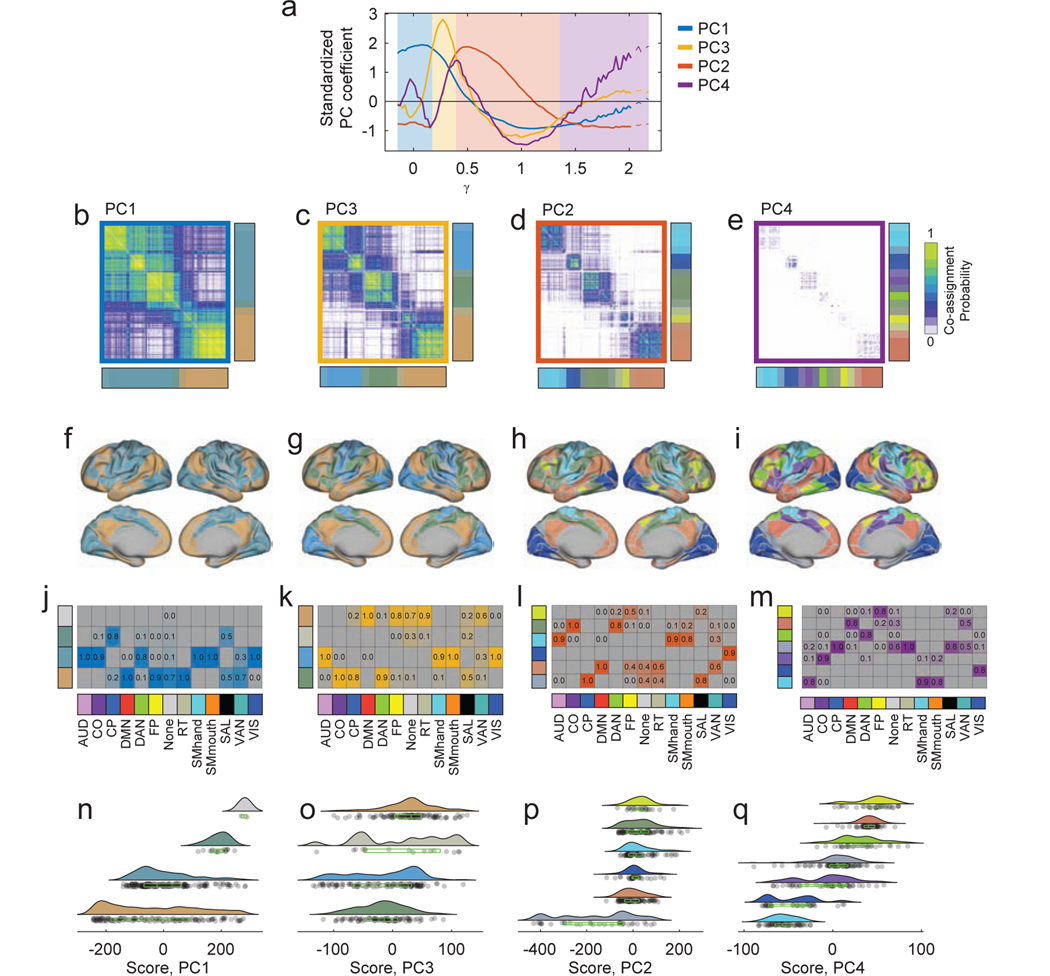
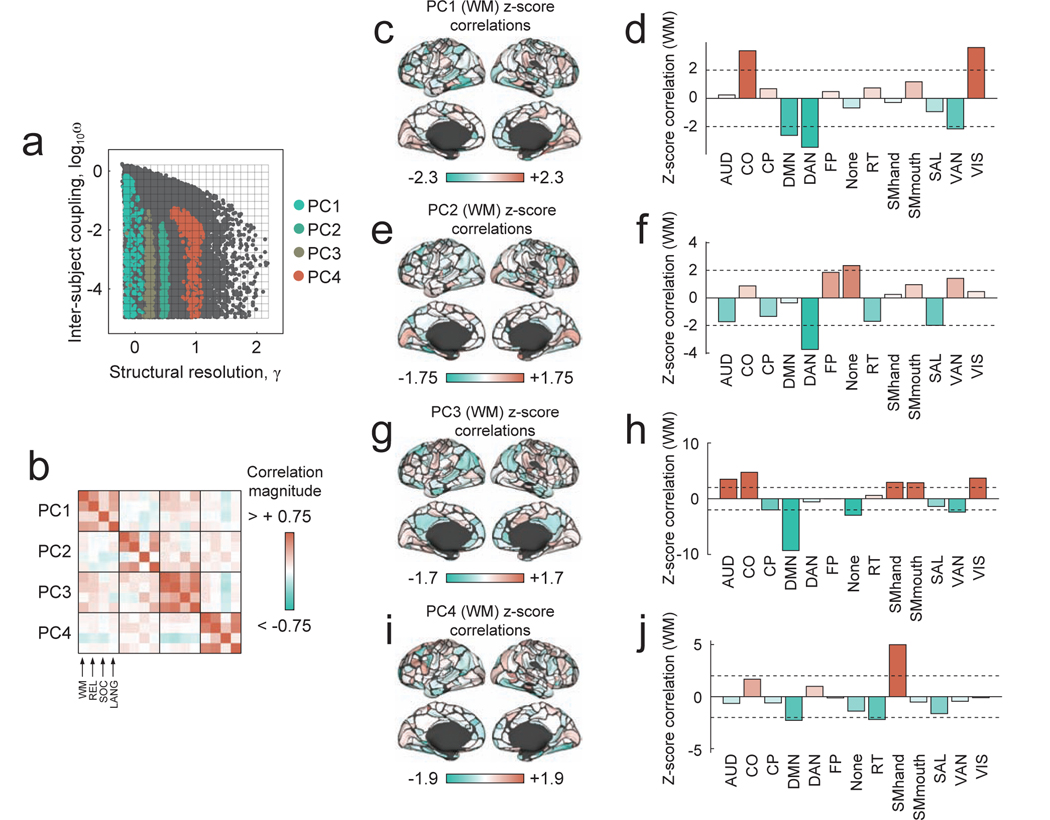
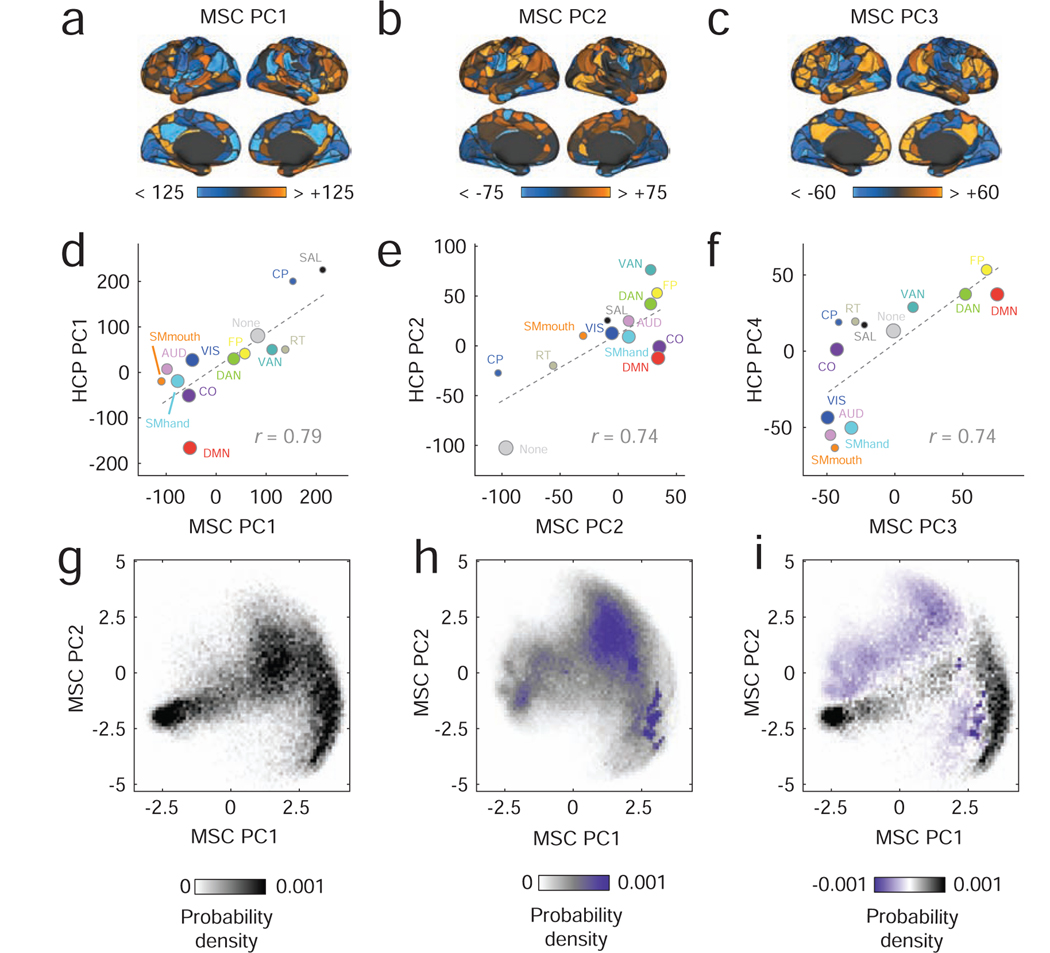
The network organization of the human brain varies across individuals, changes with development and aging, and differs in disease. Discovering the major dimensions along which this variability is displayed remains a central goal of both neuroscience and clinical medicine. Such efforts can be usefully framed within the context of the brain's modular network organization, which can be assessed quantitatively using computational techniques and extended for the purposes of multi-scale analysis, dimensionality reduction, and biomarker generation. Although the concept of modularity and its utility in describing brain network organization is clear, principled methods for comparing multi-scale communities across individuals and time are surprisingly lacking. Here, we present a method that uses multi-layer networks to simultaneously discover the modular structure of many subjects at once. This method builds upon the well-known multi-layer modularity maximization technique, and provides a viable and principled tool for studying differences in network communities across individuals and within individuals across time. We test this method on two datasets and identify consistent patterns of inter-subject community variability, demonstrating that this variability - which would be undetectable using past approaches - is associated with measures of cognitive performance. In general, the multi-layer, multi-subject framework proposed here represents an advance over current approaches by straighforwardly mapping community assignments across subjects and holds promise for future investigations of inter-subject community variation in clinical populations or as a result of task constraints.
Copyright © 2019 The Authors. Published by Elsevier Inc. All rights reserved.
Figures
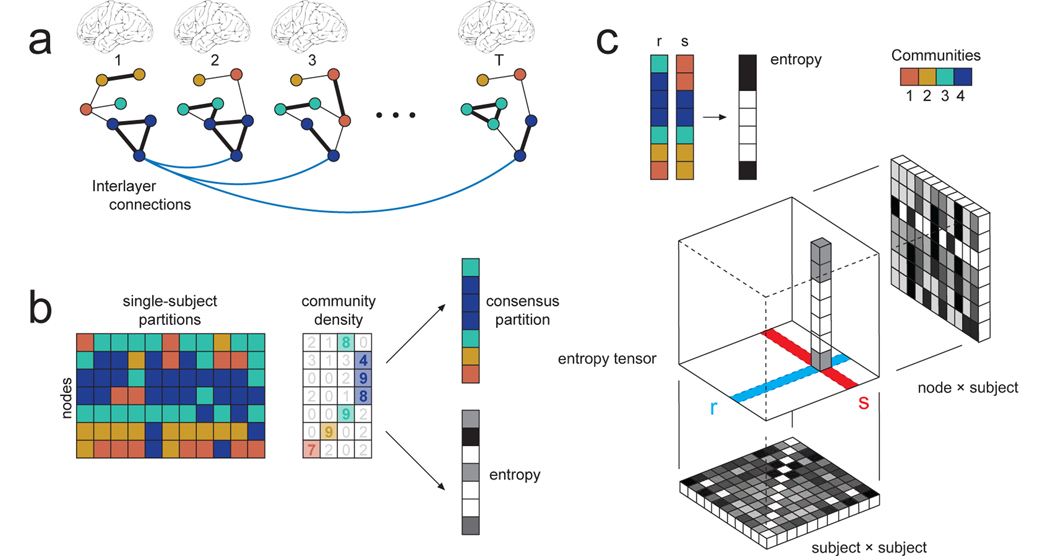
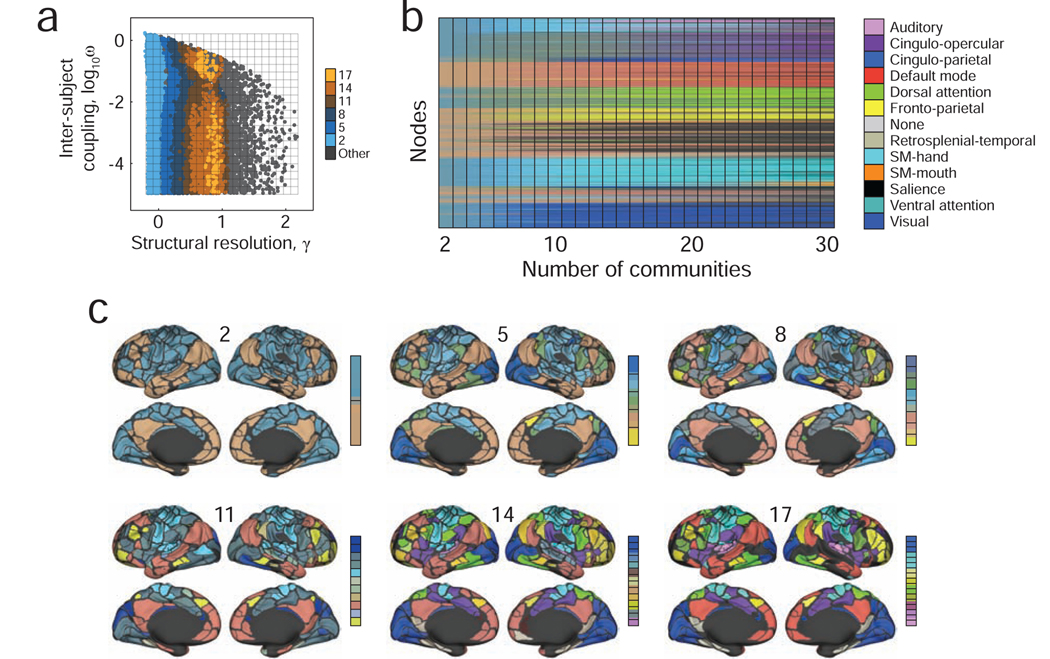
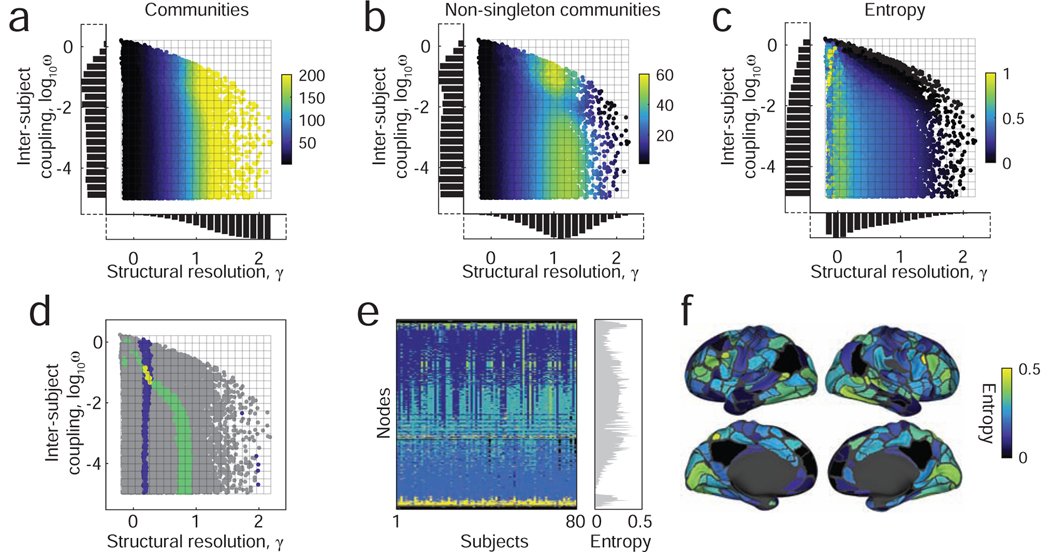
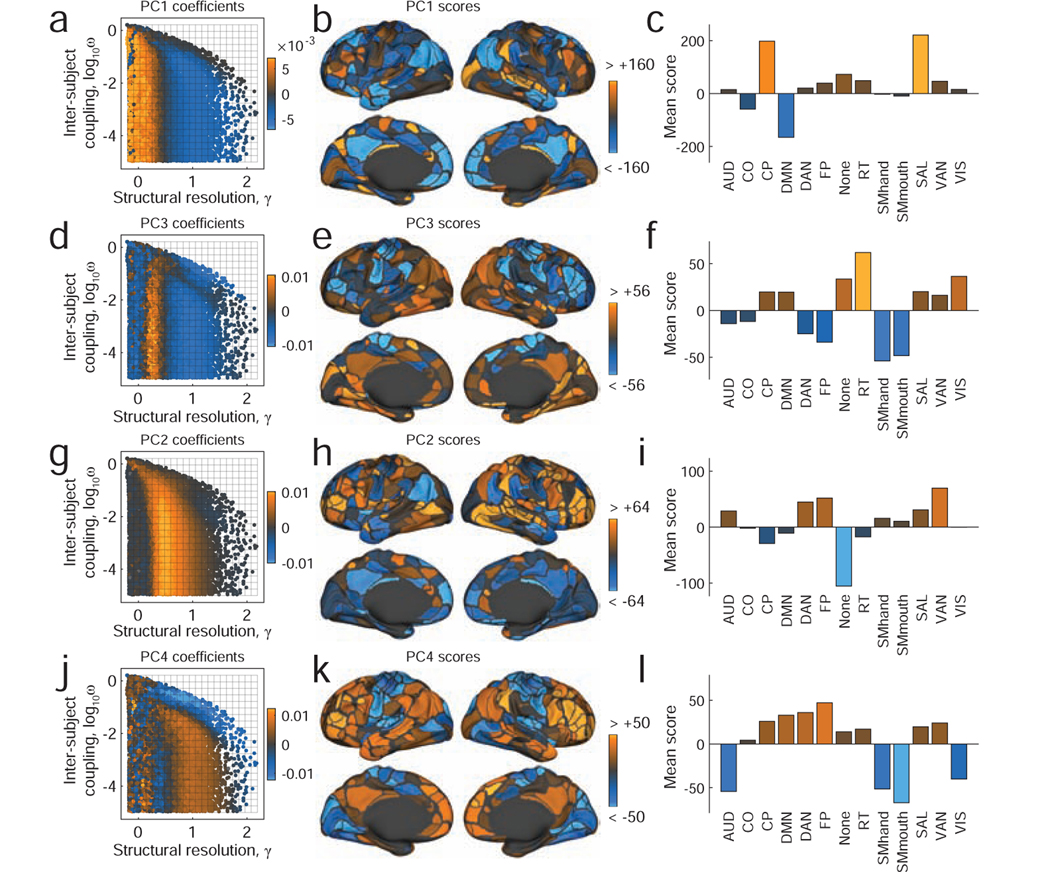
References
-
- Bullmore Ed and Sporns Olaf, “Complex brain networks: graph theoretical analysis of structural and functional systems,” Nature Reviews Neuroscience 10, 186 (2009). - PubMed
-
- Newman Mark EJ, “Communities, modules and large-scale structure in networks,” Nature physics 8, 25 (2012).
Publication types
MeSH terms
Grants and funding
LinkOut - more resources
Full Text Sources
Miscellaneous
