

Evaluation of Deep Learning Strategies for Nucleus Segmentation in Fluorescence Images
- PMID: 31313519
- PMCID: PMC6771982
- DOI: 10.1002/cyto.a.23863
Evaluation of Deep Learning Strategies for Nucleus Segmentation in Fluorescence Images
Abstract
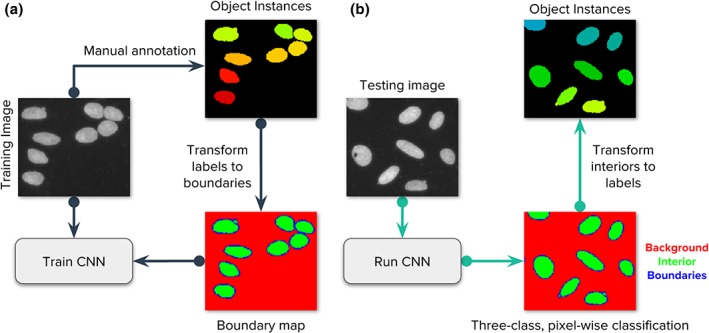
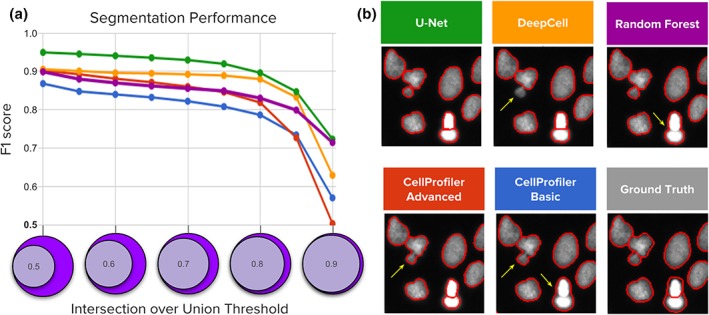
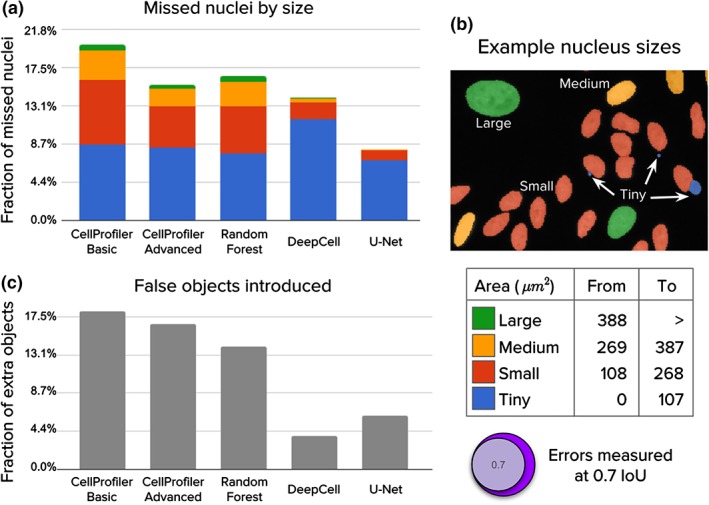
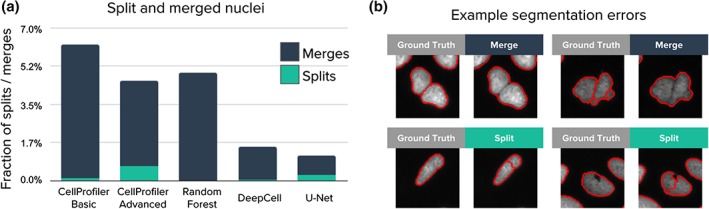
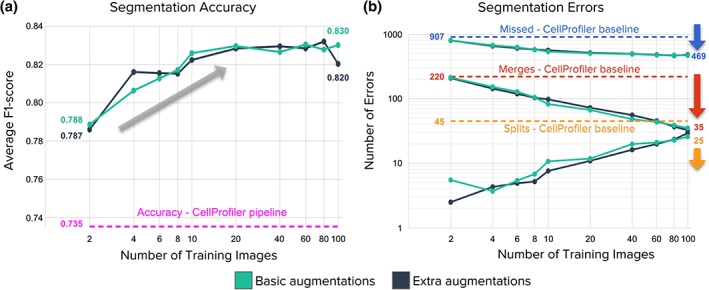
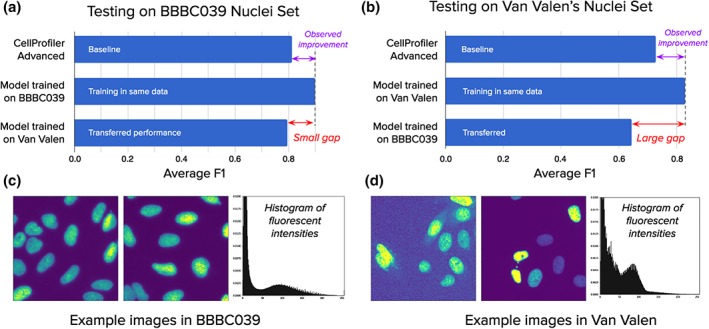
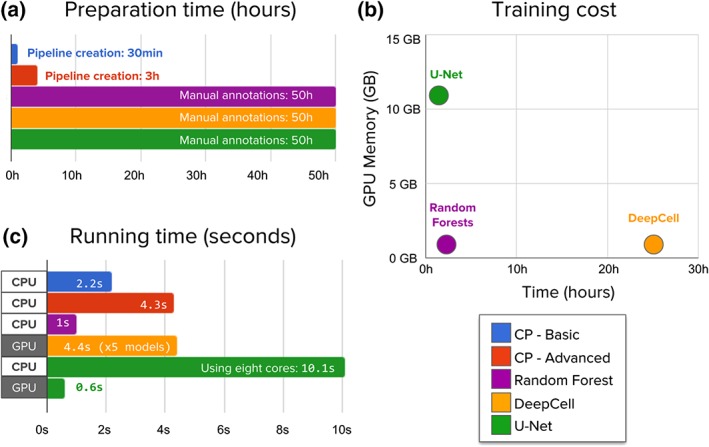
Identifying nuclei is often a critical first step in analyzing microscopy images of cells and classical image processing algorithms are most commonly used for this task. Recent developments in deep learning can yield superior accuracy, but typical evaluation metrics for nucleus segmentation do not satisfactorily capture error modes that are relevant in cellular images. We present an evaluation framework to measure accuracy, types of errors, and computational efficiency; and use it to compare deep learning strategies and classical approaches. We publicly release a set of 23,165 manually annotated nuclei and source code to reproduce experiments and run the proposed evaluation methodology. Our evaluation framework shows that deep learning improves accuracy and can reduce the number of biologically relevant errors by half. © 2019 The Authors. Cytometry Part A published by Wiley Periodicals, Inc. on behalf of International Society for Advancement of Cytometry.
Keywords: chemical screen; deep learning; fluorescence imaging; image analysis; nuclear segmentation.
© 2019 The Authors. Cytometry Part A published by Wiley Periodicals, Inc. on behalf of International Society for Advancement of Cytometry.
Figures
References
-
- Boutros M, Heigwer F, Laufer C. Microscopy‐based high‐content screening. Cell 2015;163:1314–1325. - PubMed
-
- Mattiazzi Usaj M, Styles EB, Verster AJ, Friesen H, Boone C, Andrews BJ. High‐content screening for quantitative cell biology. Trends Cell Biol 2016;26(8):598–611. - PubMed
-
- Caicedo JC, Singh S, Carpenter AE. Applications in image‐based profiling of perturbations. Curr Opin Biotechnol 2016;39:134–142. - PubMed
Publication types
MeSH terms
Grants and funding
LinkOut - more resources
Full Text Sources
Other Literature Sources
