

Toward a Brain-Inspired System: Deep Recurrent Reinforcement Learning for a Simulated Self-Driving Agent
- PMID: 31316366
- PMCID: PMC6611356
- DOI: 10.3389/fnbot.2019.00040
Toward a Brain-Inspired System: Deep Recurrent Reinforcement Learning for a Simulated Self-Driving Agent
Abstract
An effective way to achieve intelligence is to simulate various intelligent behaviors in the human brain. In recent years, bio-inspired learning methods have emerged, and they are different from the classical mathematical programming principle. From the perspective of brain inspiration, reinforcement learning has gained additional interest in solving decision-making tasks as increasing neuroscientific research demonstrates that significant links exist between reinforcement learning and specific neural substrates. Because of the tremendous research that focuses on human brains and reinforcement learning, scientists have investigated how robots can autonomously tackle complex tasks in the form of making a self-driving agent control in a human-like way. In this study, we propose an end-to-end architecture using novel deep-Q-network architecture in conjunction with a recurrence to resolve the problem in the field of simulated self-driving. The main contribution of this study is that we trained the driving agent using a brain-inspired trial-and-error technique, which was in line with the real world situation. Besides, there are three innovations in the proposed learning network: raw screen outputs are the only information which the driving agent can rely on, a weighted layer that enhances the differences of the lengthy episode, and a modified replay mechanism that overcomes the problem of sparsity and accelerates learning. The proposed network was trained and tested under a third-party OpenAI Gym environment. After training for several episodes, the resulting driving agent performed advanced behaviors in the given scene. We hope that in the future, the proposed brain-inspired learning system would inspire practicable self-driving control solutions.
Keywords: brain-inspired learning; end-to-end architecture; recurrence; reinforcement learning; self-driving agent.
Figures
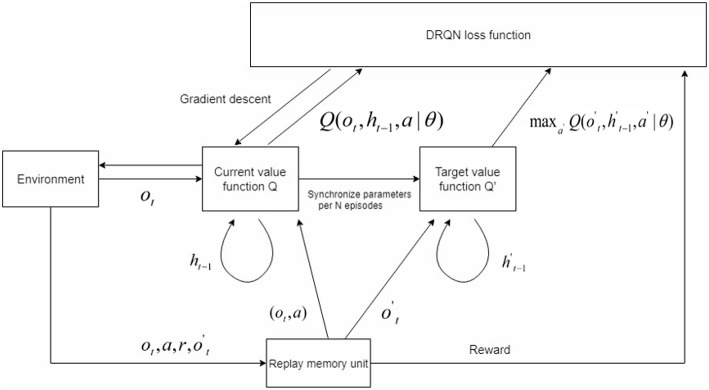
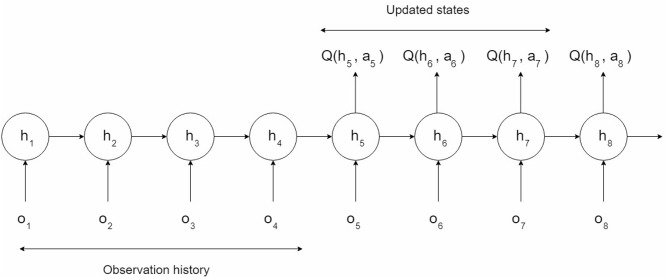
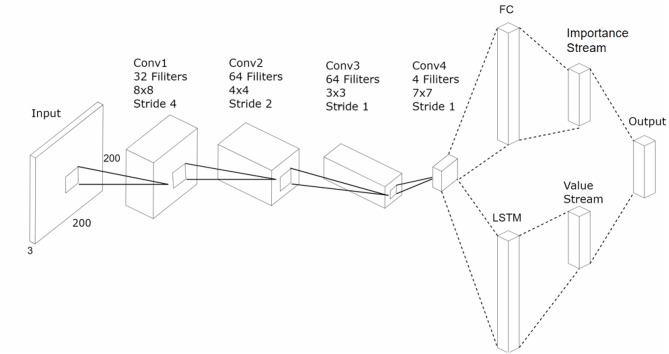
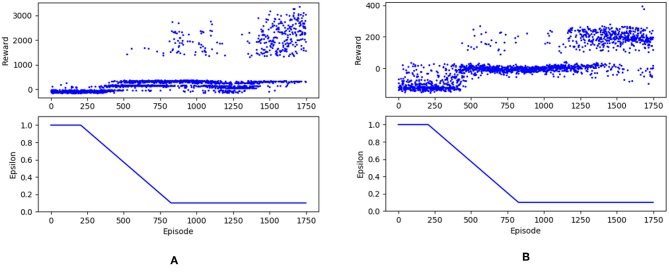

References
-
- Bellemare M. G., Naddaf Y., Veness J., Bowling M. (2013). The arcade learning environment: an evaluation platform for general agents. J. Artif. Intell. Res. 47, 253–279. 10.1613/jair.3912 - DOI
-
- Foerster J. N., Assael Y. M., de Freitas N., Whiteson S. (2016). Learning to communicate to solve riddles with deep distributed recurrent q-networks, in Advances in Neural Information Processing Systems (NeurIPS) (Barcelona: Curran Associates, Inc; ), 2137–2145.
LinkOut - more resources
Full Text Sources