

Facilitating phenotype transfer using a common data model
- PMID: 31325501
- PMCID: PMC6697565
- DOI: 10.1016/j.jbi.2019.103253
Facilitating phenotype transfer using a common data model
Abstract
Background: Implementing clinical phenotypes across a network is labor intensive and potentially error prone. Use of a common data model may facilitate the process.
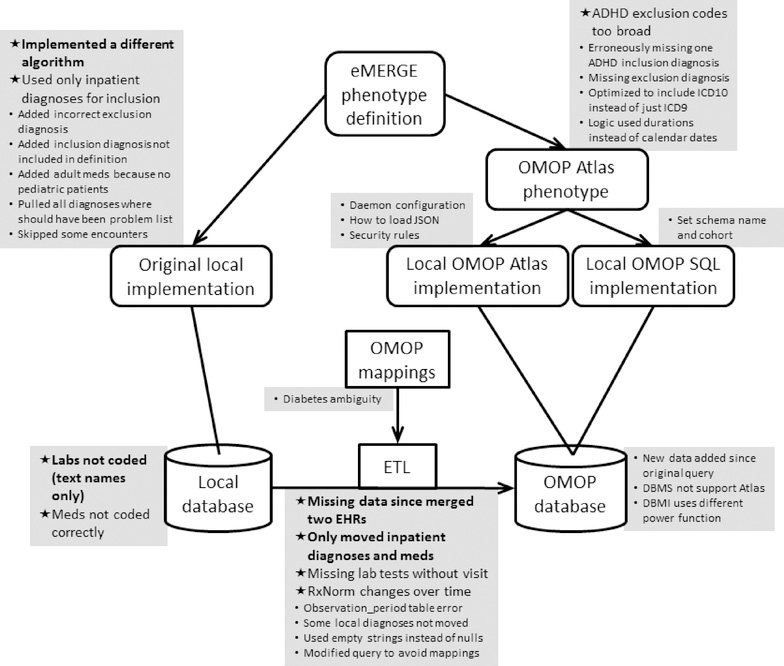
Methods: Electronic Medical Records and Genomics (eMERGE) sites implemented the Observational Health Data Sciences and Informatics (OHDSI) Observational Medical Outcomes Partnership (OMOP) Common Data Model across their electronic health record (EHR)-linked DNA biobanks. Two previously implemented eMERGE phenotypes were converted to OMOP and implemented across the network.
Results: It was feasible to implement the common data model across sites, with laboratory data producing the greatest challenge due to local encoding. Sites were then able to execute the OMOP phenotype in less than one day, as opposed to weeks of effort to manually implement an eMERGE phenotype in their bespoke research EHR databases. Of the sites that could compare the current OMOP phenotype implementation with the original eMERGE phenotype implementation, specific agreement ranged from 100% to 43%, with disagreements due to the original phenotype, the OMOP phenotype, changes in data, and issues in the databases. Using the OMOP query as a standard comparison revealed differences in the original implementations despite starting from the same definitions, code lists, flowcharts, and pseudocode.
Conclusion: Using a common data model can dramatically speed phenotype implementation at the cost of having to populate that data model, though this will produce a net benefit as the number of phenotype implementations increases. Inconsistencies among the implementations of the original queries point to a potential benefit of using a common data model so that actual phenotype code and logic can be shared, mitigating human error in reinterpretation of a narrative phenotype definition.
Keywords: Common data model; Electronic health records; Phenotyping.
Copyright © 2019 Elsevier Inc. All rights reserved.
Conflict of interest statement
Conflicts of interest:
None reported.
Figures
References
-
- Newton KM, Peissig PL, Kho AN, Bielinski SJ, Berg RL, Choudhary V, Basford M, Chute CG, Kullo IJ, Li R, Pacheco JA, Rasmussen LV, Spangler L, Denny JC. J Am Med Inform Assoc. 2013 Jun;20(e1):e147–54. Validation of electronic medical record–based phenotyping algorithms: results and lessons learned from the eMERGE network. J Am Med Inform Assoc 2013;20(e1):e147–54. - PMC - PubMed
-
- Mo H, Thompson WK, Rasmussen LV, Pacheco JA, Jiang G, Kiefer R, Zhu Q, Xu J, Montague E, Carrell DS, Lingren T, Mentch FD, Ni Y, Wehbe FH, Peissig PL, Tromp G, Larson EB, Chute CG, Pathak J, Denny JC, Speltz P, Kho AN, Jarvik GP, Bejan CA, Williams MS, Borthwick K, Kitchner TE, Roden DM, Harris PA. Desiderata for computable representations of electronic health records-driven phenotype algorithms. J Am Med Inform Assoc. 2015. November;22(6):1220–30. doi: 10.1093/jamia/ocv112. - DOI - PMC - PubMed
Publication types
MeSH terms
Grants and funding
- S10 RR025141/RR/NCRR NIH HHS/United States
- U01 HG008672/HG/NHGRI NIH HHS/United States
- U01 HG008684/HG/NHGRI NIH HHS/United States
- U01 HG008679/HG/NHGRI NIH HHS/United States
- OT2 OD026553/OD/NIH HHS/United States
- U54 MD007593/MD/NIMHD NIH HHS/United States
- U01 HG008680/HG/NHGRI NIH HHS/United States
- U01 HG006379/HG/NHGRI NIH HHS/United States
- U01 HG008664/HG/NHGRI NIH HHS/United States
- U01 HG008701/HG/NHGRI NIH HHS/United States
- U01 HG008676/HG/NHGRI NIH HHS/United States
- UL1 TR000445/TR/NCATS NIH HHS/United States
- R01 LM006910/LM/NLM NIH HHS/United States
- R01 HG009174/HG/NHGRI NIH HHS/United States
- U01 HG008657/HG/NHGRI NIH HHS/United States
- U01 HG008666/HG/NHGRI NIH HHS/United States
- R01 HL133786/HL/NHLBI NIH HHS/United States
- UL1 RR024975/RR/NCRR NIH HHS/United States
- U01 HG008673/HG/NHGRI NIH HHS/United States
- UL1 TR002243/TR/NCATS NIH HHS/United States
- U01 HG008685/HG/NHGRI NIH HHS/United States
LinkOut - more resources
Full Text Sources
Medical
