

Estimating the success of re-identifications in incomplete datasets using generative models
- PMID: 31337762
- PMCID: PMC6650473
- DOI: 10.1038/s41467-019-10933-3
Estimating the success of re-identifications in incomplete datasets using generative models
Abstract
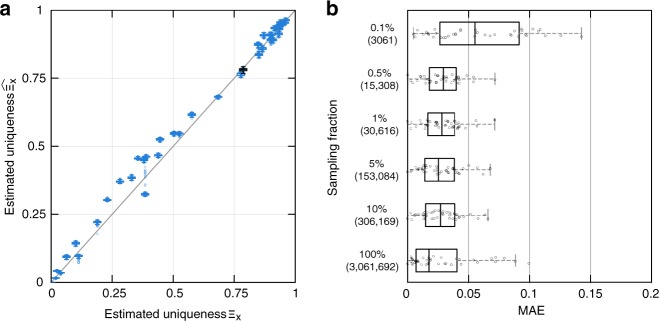
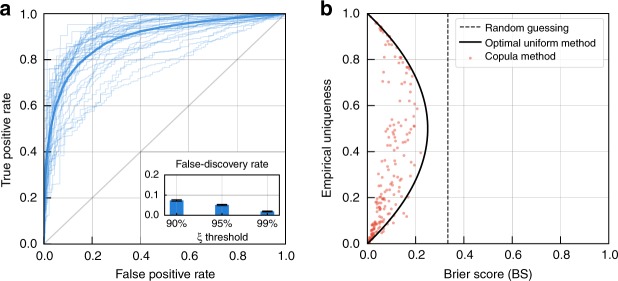
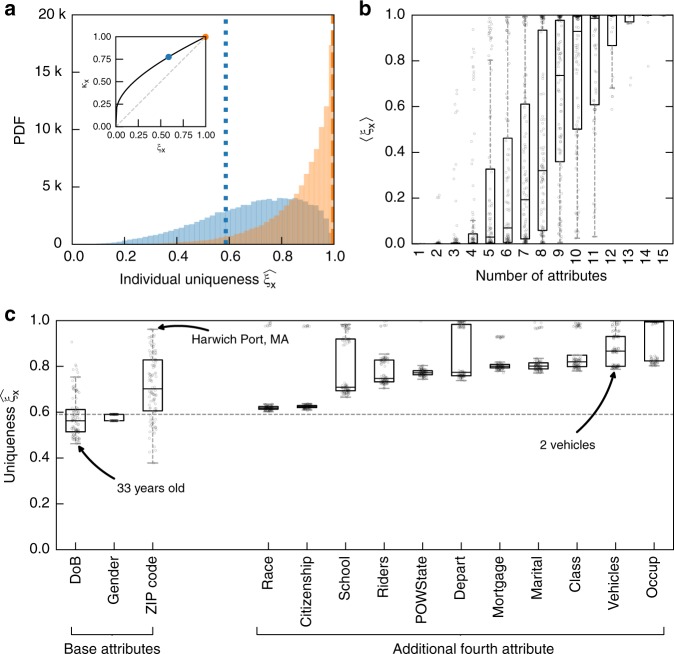
While rich medical, behavioral, and socio-demographic data are key to modern data-driven research, their collection and use raise legitimate privacy concerns. Anonymizing datasets through de-identification and sampling before sharing them has been the main tool used to address those concerns. We here propose a generative copula-based method that can accurately estimate the likelihood of a specific person to be correctly re-identified, even in a heavily incomplete dataset. On 210 populations, our method obtains AUC scores for predicting individual uniqueness ranging from 0.84 to 0.97, with low false-discovery rate. Using our model, we find that 99.98% of Americans would be correctly re-identified in any dataset using 15 demographic attributes. Our results suggest that even heavily sampled anonymized datasets are unlikely to satisfy the modern standards for anonymization set forth by GDPR and seriously challenge the technical and legal adequacy of the de-identification release-and-forget model.
Conflict of interest statement
The authors declare no competing interests.
Figures
Comment in
-
Time to discuss consent in digital-data studies.Nature. 2019 Aug;572(7767):5. doi: 10.1038/d41586-019-02322-z. Nature. 2019. PMID: 31367033 No abstract available.
-
Anonymity takes more than protecting personal details.Nature. 2019 Oct;574(7777):176. doi: 10.1038/d41586-019-03023-3. Nature. 2019. PMID: 31595072 No abstract available.
-
Show evidence that apps for COVID-19 contact-tracing are secure and effective.Nature. 2020 Apr;580(7805):563. doi: 10.1038/d41586-020-01264-1. Nature. 2020. PMID: 32350479 No abstract available.
References
-
- Poushter, J. Smartphone ownership and internet usage continues to climb in emerging economies (Pew Research Center, Washington, DC, 2016). http://www.pewglobal.org/2016/02/22/smartphone-ownership-and-internet-us....
-
- Yang, N. & Hing, E. National electronic health records survey. https://cdc.gov/nchs/data/ahcd/nehrs/2015_nehrs_ehr_by_specialty.pdf (2015).
Publication types
MeSH terms
LinkOut - more resources
Full Text Sources
Other Literature Sources
Molecular Biology Databases
