

RNA Synthesis and Capping by Non-segmented Negative Strand RNA Viral Polymerases: Lessons From a Prototypic Virus
- PMID: 31354644
- PMCID: PMC6636387
- DOI: 10.3389/fmicb.2019.01490
RNA Synthesis and Capping by Non-segmented Negative Strand RNA Viral Polymerases: Lessons From a Prototypic Virus
Abstract
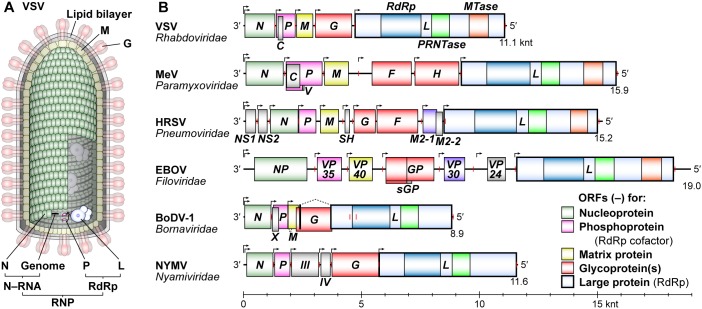
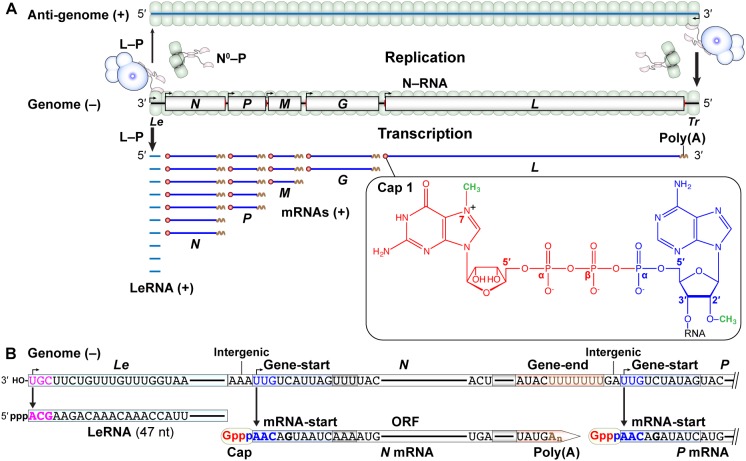
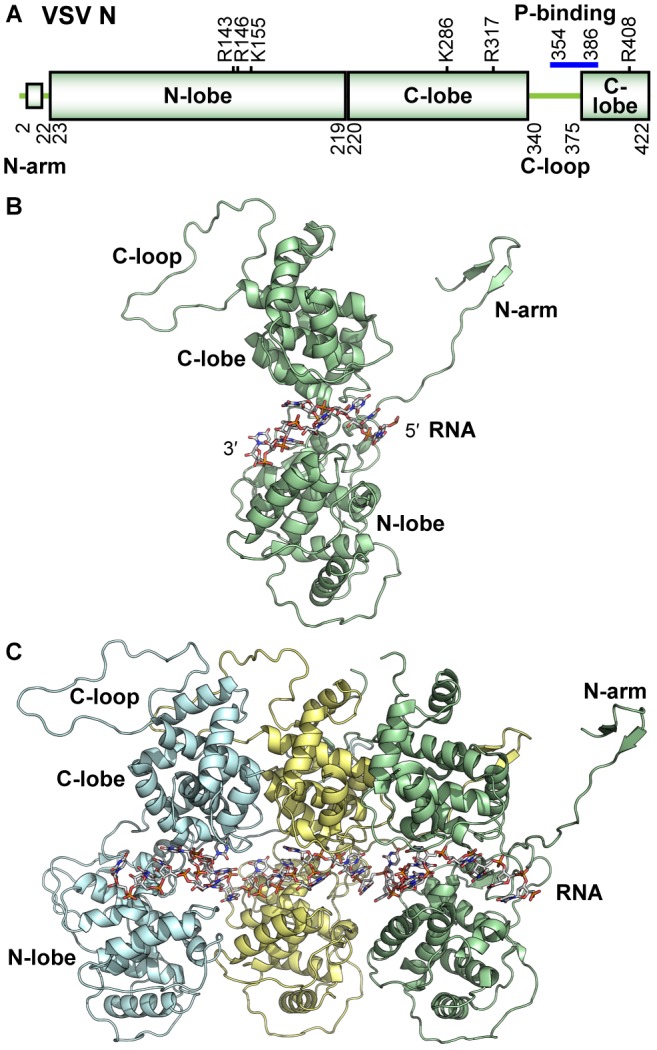
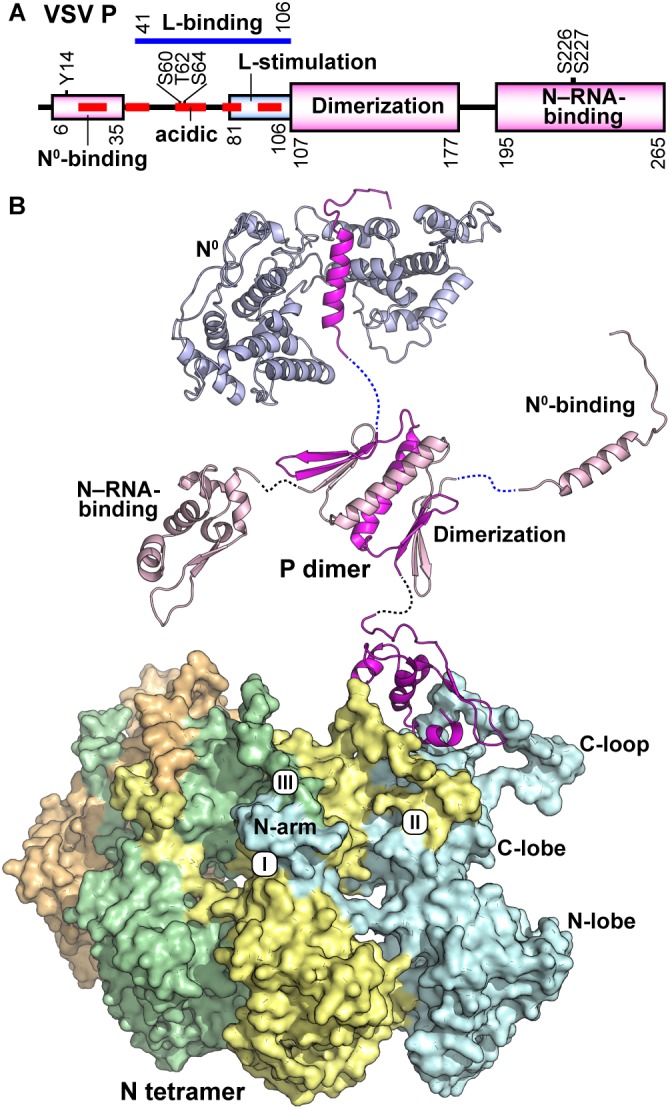
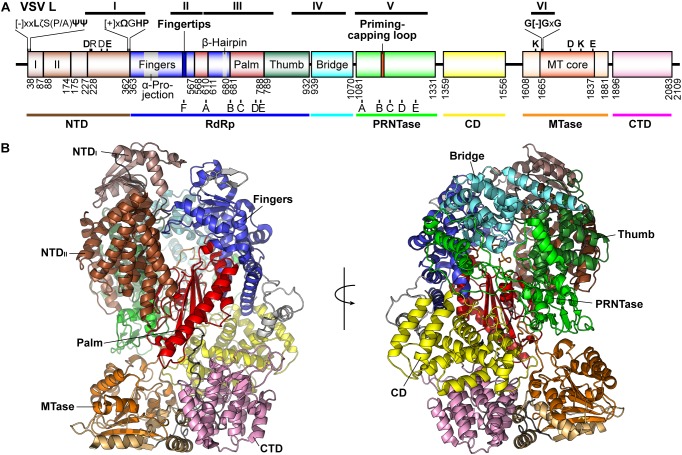
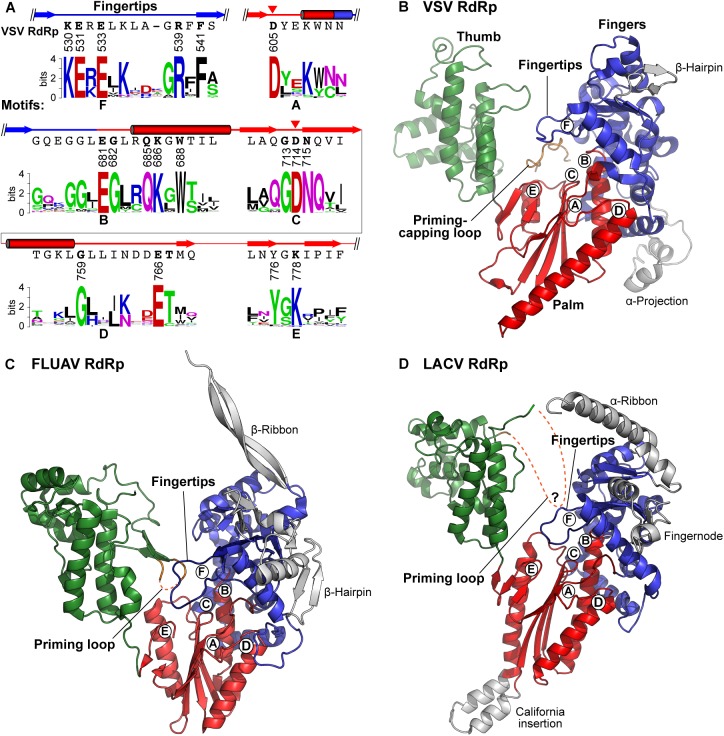
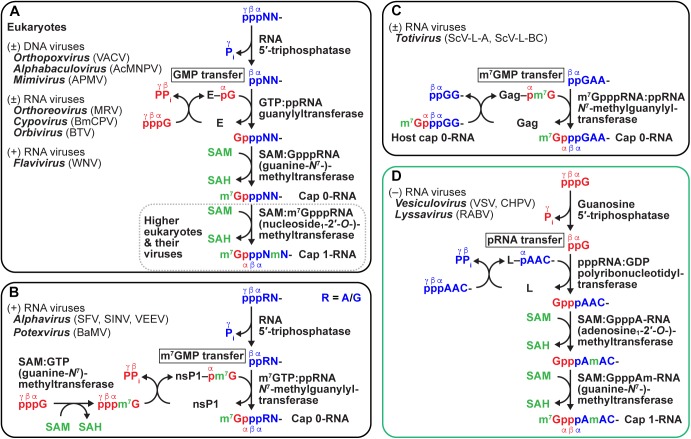
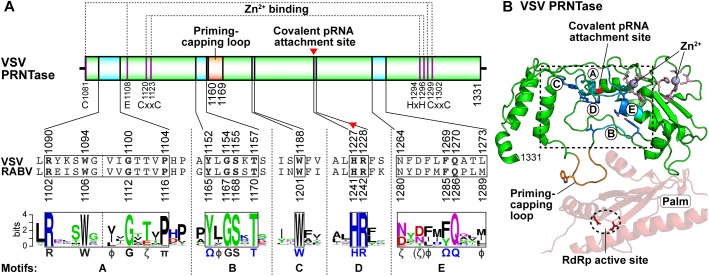
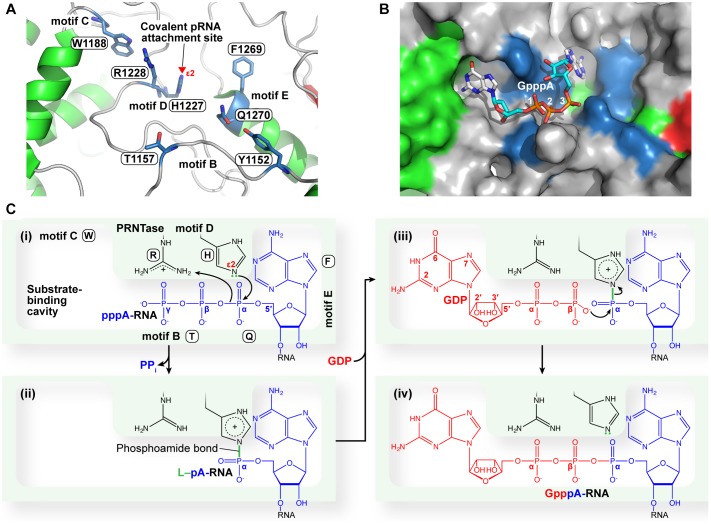
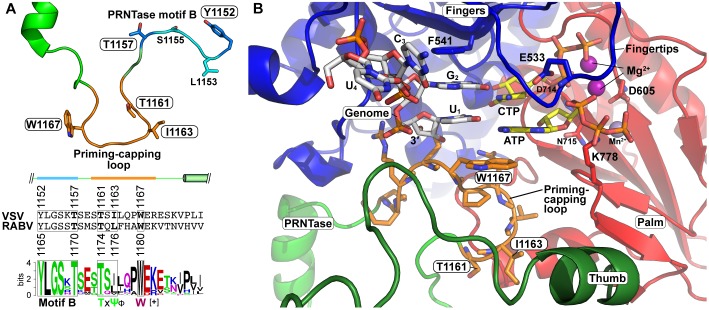
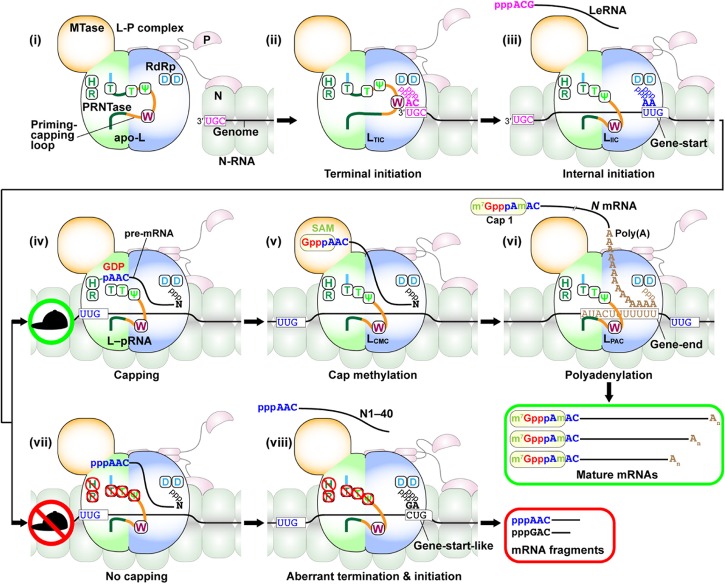
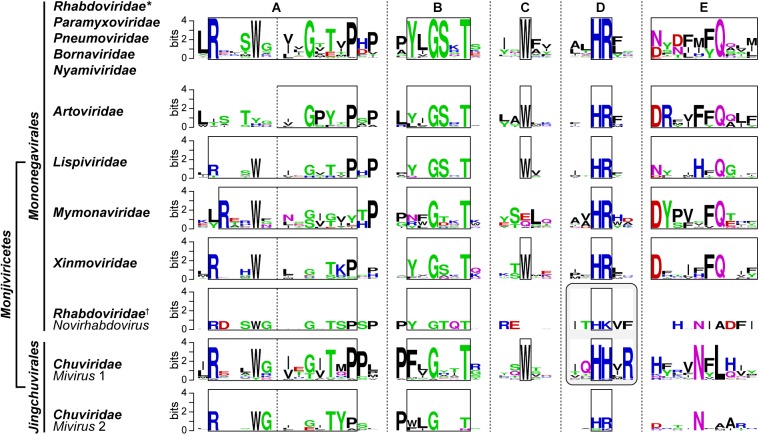
Non-segmented negative strand (NNS) RNA viruses belonging to the order Mononegavirales are highly diversified eukaryotic viruses including significant human pathogens, such as rabies, measles, Nipah, and Ebola. Elucidation of their unique strategies to replicate in eukaryotic cells is crucial to aid in developing anti-NNS RNA viral agents. Over the past 40 years, vesicular stomatitis virus (VSV), closely related to rabies virus, has served as a paradigm to study the fundamental molecular mechanisms of transcription and replication of NNS RNA viruses. These studies provided insights into how NNS RNA viruses synthesize 5'-capped mRNAs using their RNA-dependent RNA polymerase L proteins equipped with an unconventional mRNA capping enzyme, namely GDP polyribonucleotidyltransferase (PRNTase), domain. PRNTase or PRNTase-like domains are evolutionally conserved among L proteins of all known NNS RNA viruses and their related viruses belonging to Jingchuvirales, a newly established order, in the class Monjiviricetes, suggesting that they may have evolved from a common ancestor that acquired the unique capping system to replicate in a primitive eukaryotic host. This article reviews what has been learned from biochemical and structural studies on the VSV RNA biosynthesis machinery, and then focuses on recent advances in our understanding of regulatory and catalytic roles of the PRNTase domain in RNA synthesis and capping.
Keywords: GDP polyribonucleotidyltransferase; RNA-dependent RNA polymerase; mRNA capping; non-segmented negative strand RNA viruses; rabies virus; replication; transcription; vesicular stomatitis virus.
Figures
References
-
- Abbas Y. M., Laudenbach B. T., Martinez-Montero S., Cencic R., Habjan M., Pichlmair A., et al. (2017). Structure of human IFIT1 with capped RNA reveals adaptable mRNA binding and mechanisms for sensing N1 and N2 ribose 2′-O methylations. Proc. Natl. Acad. Sci. U.S.A. 114 E2106–E2115. 10.1073/pnas.1612444114 - DOI - PMC - PubMed
Publication types
Grants and funding
LinkOut - more resources
Full Text Sources
Other Literature Sources
Miscellaneous