

doi: 10.1093/bioinformatics/btz572.
Tailor-made multiple sequence alignments using the PRALINE 2 alignment toolkit
Affiliations
- PMID: 31368486
- PMCID: PMC6954659
- DOI: 10.1093/bioinformatics/btz572
Item in Clipboard
Tailor-made multiple sequence alignments using the PRALINE 2 alignment toolkit
Bioinformatics.
.
Abstract
Summary: PRALINE 2 is a toolkit for custom multiple sequence alignment workflows. It can be used to incorporate sequence annotations, such as secondary structure or (DNA) motifs, into the alignment scoring, as well as to customize many other aspects of a progressive multiple alignment workflow.
Availability and implementation: PRALINE 2 is implemented in Python and available as open source software on GitHub: https://github.com/ibivu/PRALINE/.
© The Author(s) 2019. Published by Oxford University Press.
Figures
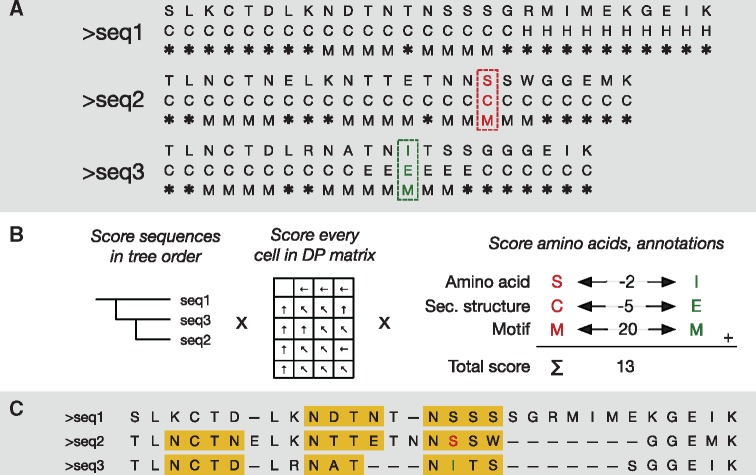
Overview of the PRALINE 2 algorithm, showing how an alignment can be improved by incorporating sequence annotations. (A) Three input amino acid sequences alongside two annotation tracks: the 3-state secondary structure (C, E, H) and an annotation predicting whether an N-terminal glycosylation site exists at a position (M) or not (*). A pair of columns, shown in red and green, is tracked throughout the steps of the algorithm. (B) Scoring in more detail. The three types of symbols contribute independently to the total score: amino acids are scored by BLOSUM62, secondary structure by a 5/-5 match/mismatch scheme, and, if both positions are a glycosylation motif, a score boost of 20 is applied. (C) The resulting alignment (amino acid sequences only); note that the motifs, shown in yellow, are correctly aligned, due to the motif scoring
References
-
- Heringa J. (1999) Two strategies for sequence comparison: profile-preprocessed and secondary structure-induced multiple alignment. Comput. Chem., 23, 341–364. - PubMed
-
- Hogeweg P., Hesper B. (1984) The alignment of sets of sequences and the construction of phyletic trees: an integrated method. J. Mol. Evol., 20, 175–186. - PubMed
