

Massive metagenomic data analysis using abundance-based machine learning
- PMID: 31370905
- PMCID: PMC6676585
- DOI: 10.1186/s13062-019-0242-0
Massive metagenomic data analysis using abundance-based machine learning
Abstract
Background: Metagenomics is the application of modern genomic techniques to investigate the members of a microbial community directly in their natural environments and is widely used in many studies to survey the communities of microbial organisms that live in diverse ecosystems. In order to understand the metagenomic profile of one of the densest interaction spaces for millions of people, the public transit system, the MetaSUB international Consortium has collected and sequenced metagenomes from subways of different cities across the world. In collaboration with CAMDA, MetaSUB has made the metagenomic samples from these cities available for an open challenge of data analysis including, but not limited in scope to, the identification of unknown samples.
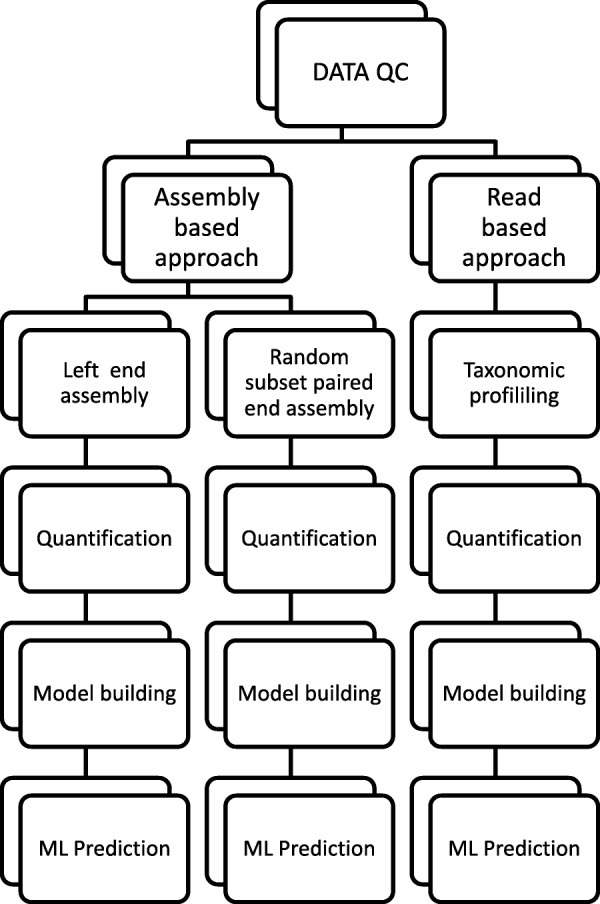
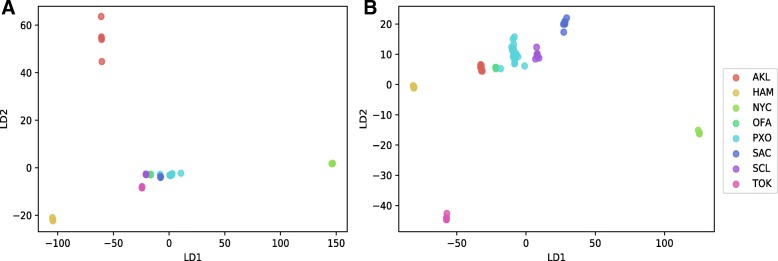
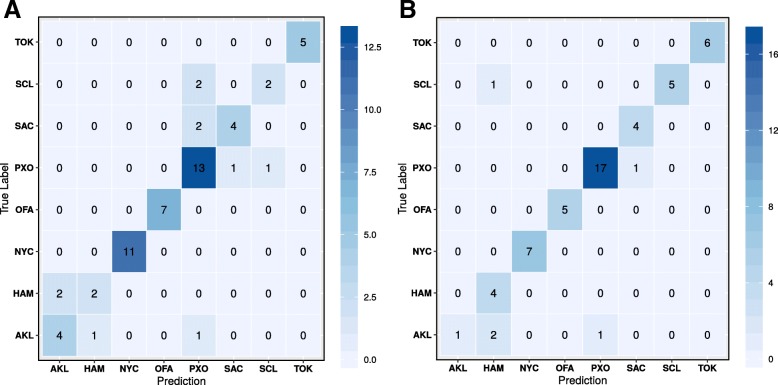
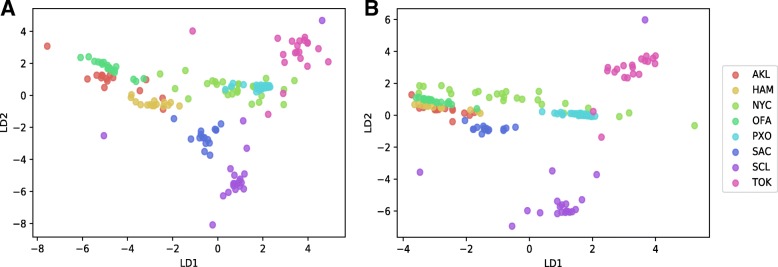
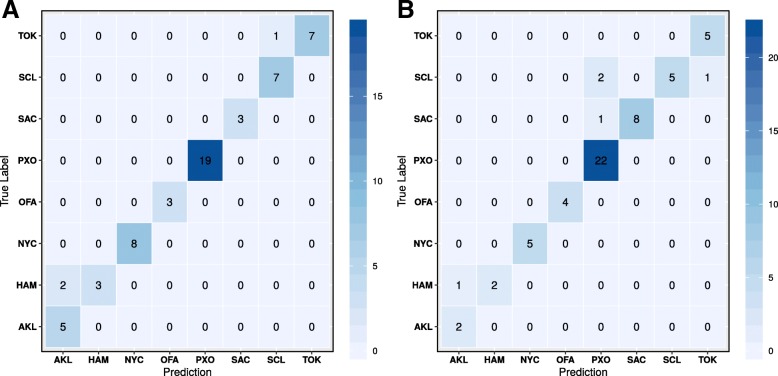
Results: To distinguish the metagenomic profiling among different cities and also predict unknown samples precisely based on the profiling, two different approaches are proposed using machine learning techniques; one is a read-based taxonomy profiling of each sample and prediction method, and the other is a reduced representation assembly-based method. Among various machine learning techniques tested, the random forest technique showed promising results as a suitable classifier for both approaches. Random forest models developed from read-based taxonomic profiling could achieve an accuracy of 91% with 95% confidence interval between 80 and 93%. The assembly-based random forest model prediction also reached 90% accuracy. However, both models achieved roughly the same accuracy on the testing test, whereby they both failed to predict the most abundant label.
Conclusion: Our results suggest that both read-based and assembly-based approaches are powerful tools for the analysis of metagenomics data. Moreover, our results suggest that reduced representation assembly-based methods are able to simultaneous provide high-accuracy prediction on available data. Overall, we show that metagenomic samples can be traced back to their location with careful generation of features from the composition of microbes and utilizing existing machine learning algorithms. Proposed approaches show high accuracy of prediction, but require careful inspection before making any decisions due to sample noise or complexity.
Reviewers: This article was reviewed by Eugene V. Koonin, Jing Zhou and Serghei Mangul.
Keywords: CAMDA; Machine learning; MetaSUB; Metagenomics; Taxonomy profiling.
Conflict of interest statement
The authors declare they have no competing interests.
Figures
Similar articles
-
A machine learning framework to determine geolocations from metagenomic profiling.Biol Direct. 2020 Nov 23;15(1):27. doi: 10.1186/s13062-020-00278-z. Biol Direct. 2020. PMID: 33225966 Free PMC article.
-
Application of machine learning techniques for creating urban microbial fingerprints.Biol Direct. 2019 Aug 16;14(1):13. doi: 10.1186/s13062-019-0245-x. Biol Direct. 2019. PMID: 31420049 Free PMC article.
-
Identification of city specific important bacterial signature for the MetaSUB CAMDA challenge microbiome data.Biol Direct. 2019 Jul 24;14(1):11. doi: 10.1186/s13062-019-0243-z. Biol Direct. 2019. PMID: 31340852 Free PMC article.
-
Practical considerations for sampling and data analysis in contemporary metagenomics-based environmental studies.J Microbiol Methods. 2018 Nov;154:14-18. doi: 10.1016/j.mimet.2018.09.020. Epub 2018 Oct 1. J Microbiol Methods. 2018. PMID: 30287354 Review.
-
A review of neural networks for metagenomic binning.Brief Bioinform. 2025 Mar 4;26(2):bbaf065. doi: 10.1093/bib/bbaf065. Brief Bioinform. 2025. PMID: 40131312 Free PMC article. Review.
Cited by
-
Metagenomic Studies in Inflammatory Skin Diseases.Curr Microbiol. 2020 Nov;77(11):3201-3212. doi: 10.1007/s00284-020-02163-4. Epub 2020 Aug 19. Curr Microbiol. 2020. PMID: 32813091 Free PMC article. Review.
-
Involvement of transcribed lncRNA uc.291 and SWI/SNF complex in cutaneous squamous cell carcinoma.Discov Oncol. 2021 May 3;12(1):14. doi: 10.1007/s12672-021-00409-6. Discov Oncol. 2021. PMID: 35201472 Free PMC article.
-
Serine and one-carbon metabolisms bring new therapeutic venues in prostate cancer.Discov Oncol. 2021 Oct 27;12(1):45. doi: 10.1007/s12672-021-00440-7. Discov Oncol. 2021. PMID: 35201488 Free PMC article. Review.
-
Comparison of 16S and whole genome dog microbiomes using machine learning.BioData Min. 2021 Aug 21;14(1):41. doi: 10.1186/s13040-021-00270-x. BioData Min. 2021. PMID: 34419136 Free PMC article.
-
A machine learning framework to determine geolocations from metagenomic profiling.Biol Direct. 2020 Nov 23;15(1):27. doi: 10.1186/s13062-020-00278-z. Biol Direct. 2020. PMID: 33225966 Free PMC article.
References
Publication types
MeSH terms
LinkOut - more resources
Full Text Sources
