

Comparison of Two-Talker Attention Decoding from EEG with Nonlinear Neural Networks and Linear Methods
- PMID: 31395905
- PMCID: PMC6687829
- DOI: 10.1038/s41598-019-47795-0
Comparison of Two-Talker Attention Decoding from EEG with Nonlinear Neural Networks and Linear Methods
Abstract
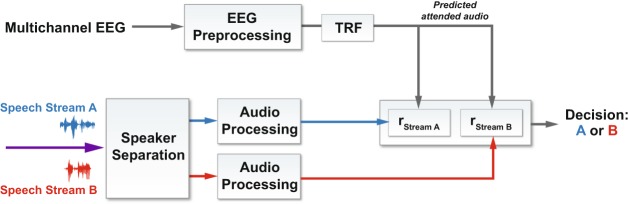
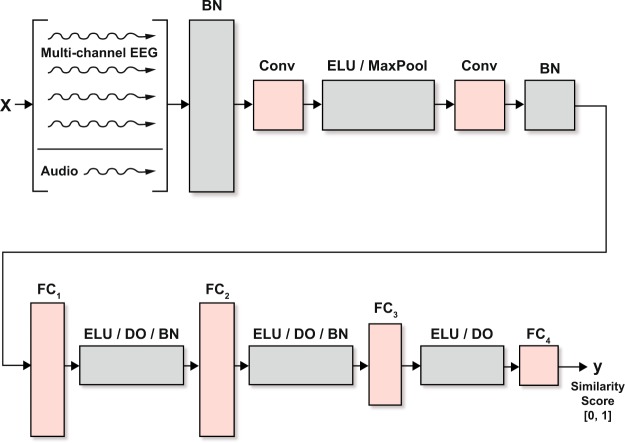
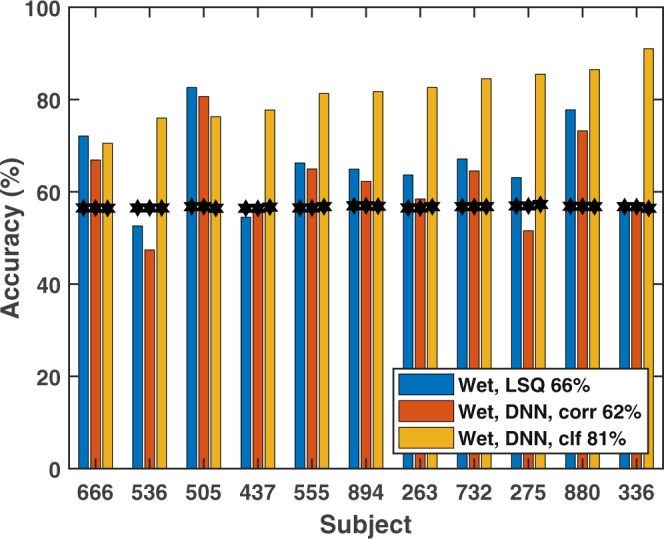
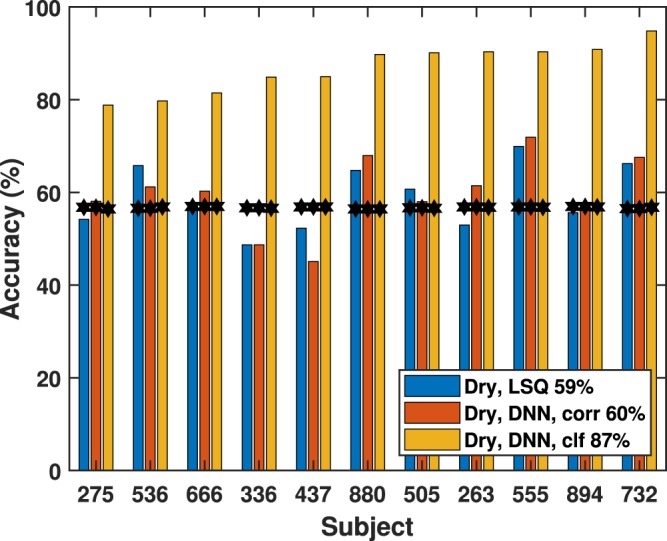
Auditory attention decoding (AAD) through a brain-computer interface has had a flowering of developments since it was first introduced by Mesgarani and Chang (2012) using electrocorticograph recordings. AAD has been pursued for its potential application to hearing-aid design in which an attention-guided algorithm selects, from multiple competing acoustic sources, which should be enhanced for the listener and which should be suppressed. Traditionally, researchers have separated the AAD problem into two stages: reconstruction of a representation of the attended audio from neural signals, followed by determining the similarity between the candidate audio streams and the reconstruction. Here, we compare the traditional two-stage approach with a novel neural-network architecture that subsumes the explicit similarity step. We compare this new architecture against linear and non-linear (neural-network) baselines using both wet and dry electroencephalogram (EEG) systems. Our results indicate that the new architecture outperforms the baseline linear stimulus-reconstruction method, improving decoding accuracy from 66% to 81% using wet EEG and from 59% to 87% for dry EEG. Also of note was the finding that the dry EEG system can deliver comparable or even better results than the wet, despite the latter having one third as many EEG channels as the former. The 11-subject, wet-electrode AAD dataset for two competing, co-located talkers, the 11-subject, dry-electrode AAD dataset, and our software are available for further validation, experimentation, and modification.
Conflict of interest statement
All authors are part of a provisional patent application on the end-to-end, deep neural network auditory attention decoding algorithm described in this work. NM and J O’S are inventors on submitted patent WO2017218492A1 which covers neural decoding of auditory attention.
Figures



References
-
- USVA. Annual Benefits Report Fiscal Year 2017. US Department of Veterans Affairs, Veterans Benefits Administration (2017).
-
- Kochkin S. Customer satisfaction with hearing instruments in the digital age. The Hearing Journal. 2005;58(9):30–43. doi: 10.1097/01.HJ.0000286545.33961.e7. - DOI
-
- Abrams H, Kihm J. An introduction to MarkeTrak IX: A new baseline for the hearing aid market. Hearing Review. 2015;22(6):16.
Publication types
MeSH terms
Grants and funding
LinkOut - more resources
Full Text Sources
Other Literature Sources
