

Entangled-photon decision maker
- PMID: 31439920
- PMCID: PMC6706396
- DOI: 10.1038/s41598-019-48647-7
Entangled-photon decision maker
Abstract
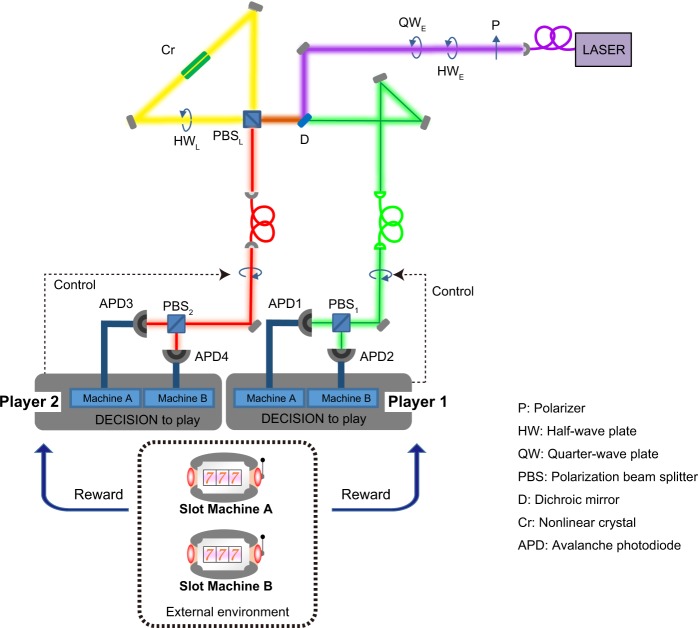
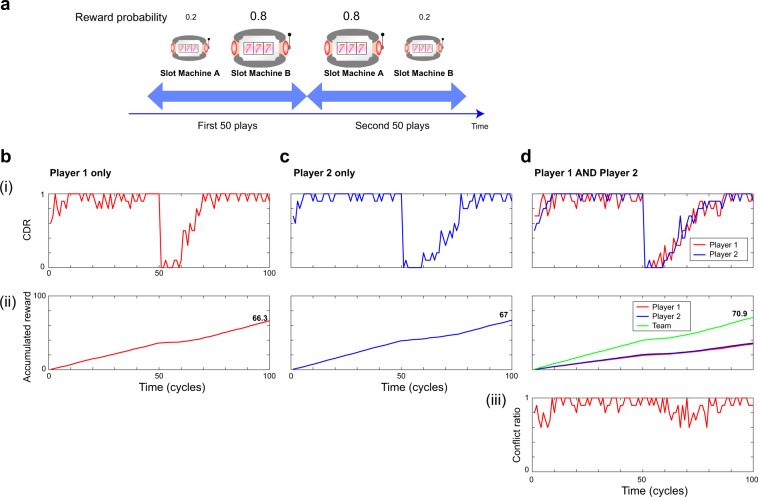
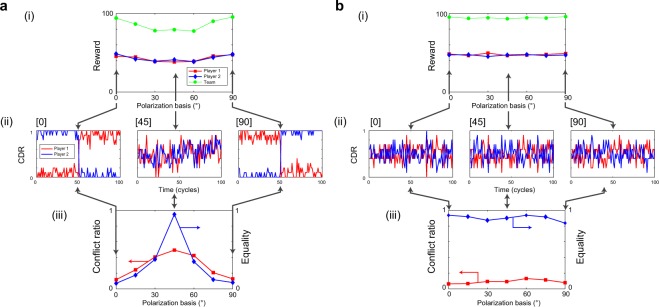
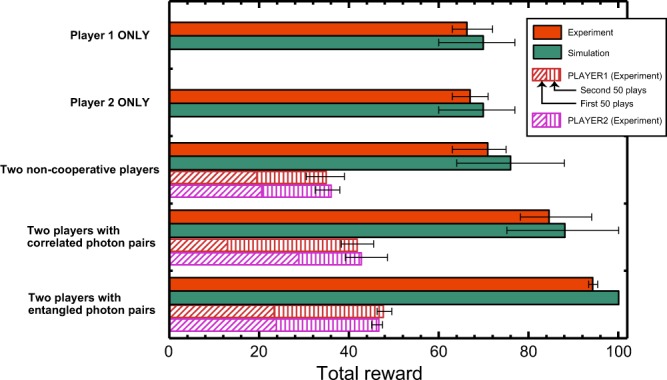
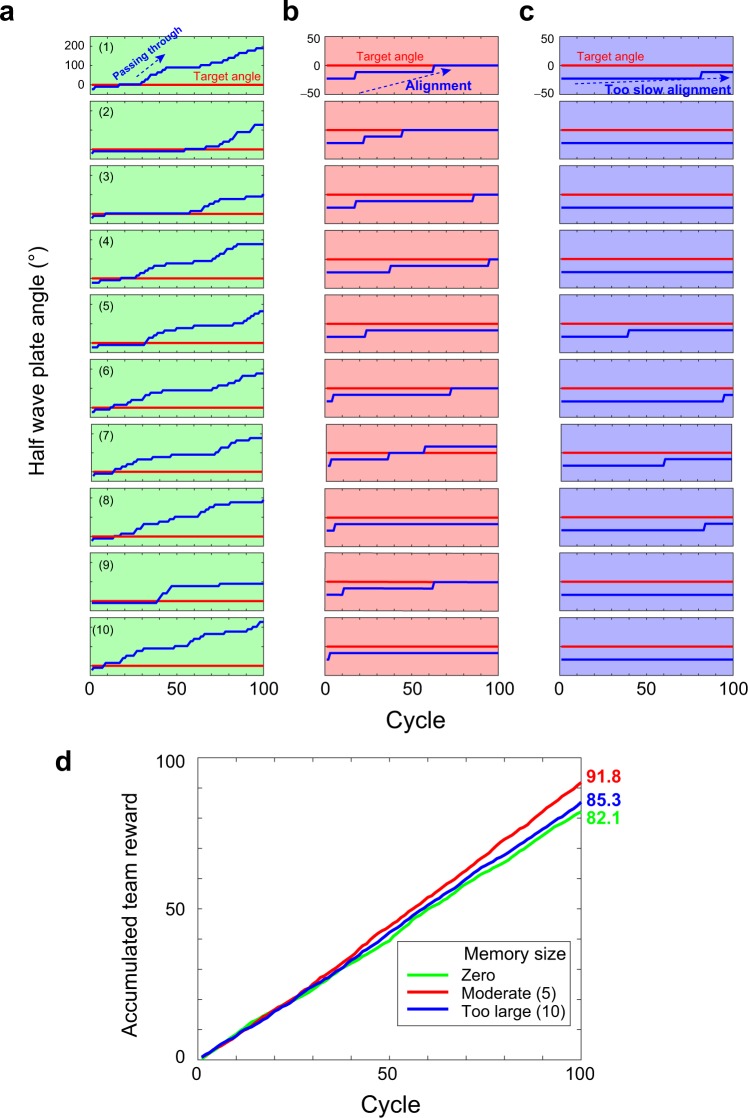
The competitive multi-armed bandit (CMAB) problem is related to social issues such as maximizing total social benefits while preserving equality among individuals by overcoming conflicts between individual decisions, which could seriously decrease social benefits. The study described herein provides experimental evidence that entangled photons physically resolve the CMAB in the 2-arms 2-players case, maximizing the social rewards while ensuring equality. Moreover, we demonstrated that deception, or outperforming the other player by receiving a greater reward, cannot be accomplished in a polarization-entangled-photon-based system, while deception is achievable in systems based on classical polarization-correlated photons with fixed polarizations. Besides, random polarization-correlated photons have been studied numerically and shown to ensure equality between players and deception prevention as well, although the CMAB maximum performance is reduced as compared with entangled photon experiments. Autonomous alignment schemes for polarization bases were also experimentally demonstrated based only on decision conflict information observed by an individual without communications between players. This study paves a way for collective decision making in uncertain dynamically changing environments based on entangled quantum states, a crucial step toward utilizing quantum systems for intelligent functionalities.
Conflict of interest statement
The authors declare no competing interests.
Figures

References
-
- Shen Y, et al. Deep learning with coherent nanophotonic circuits. Nat. Photon. 2017;11:441–446. doi: 10.1038/nphoton.2017.93. - DOI
-
- Sutton, R. S. & Barto, A. G. Reinforcement Learning: An Introduction (The MIT Press, 1998).
Publication types
LinkOut - more resources
Full Text Sources
