

Origin of the Genetic Code Is Found at the Transition between a Thioester World of Peptides and the Phosphoester World of Polynucleotides
- PMID: 31443422
- PMCID: PMC6789786
- DOI: 10.3390/life9030069
Origin of the Genetic Code Is Found at the Transition between a Thioester World of Peptides and the Phosphoester World of Polynucleotides
Abstract
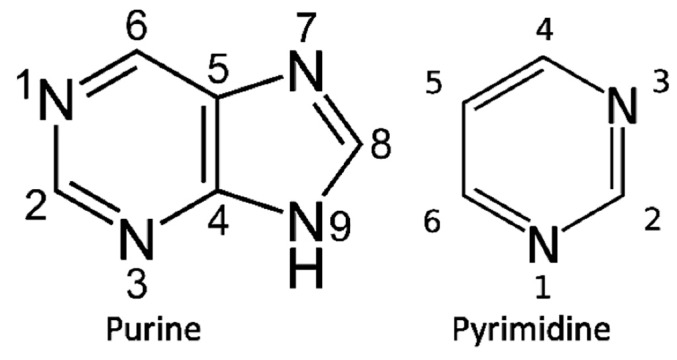
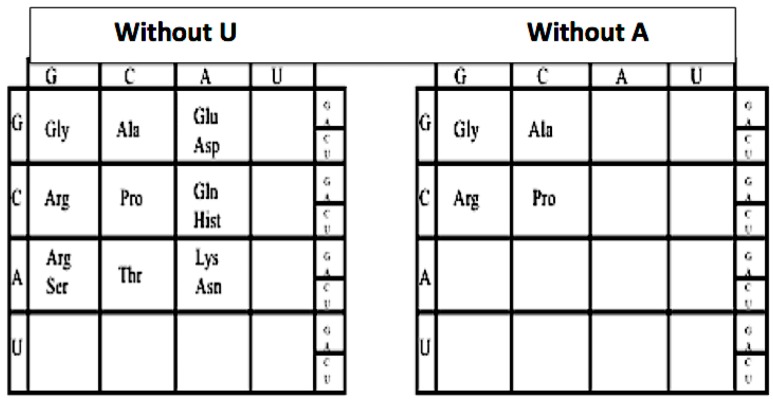
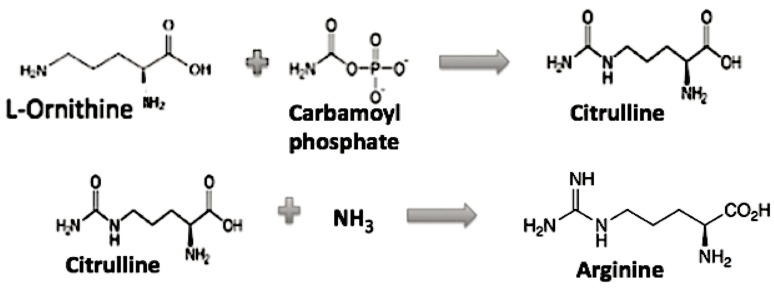
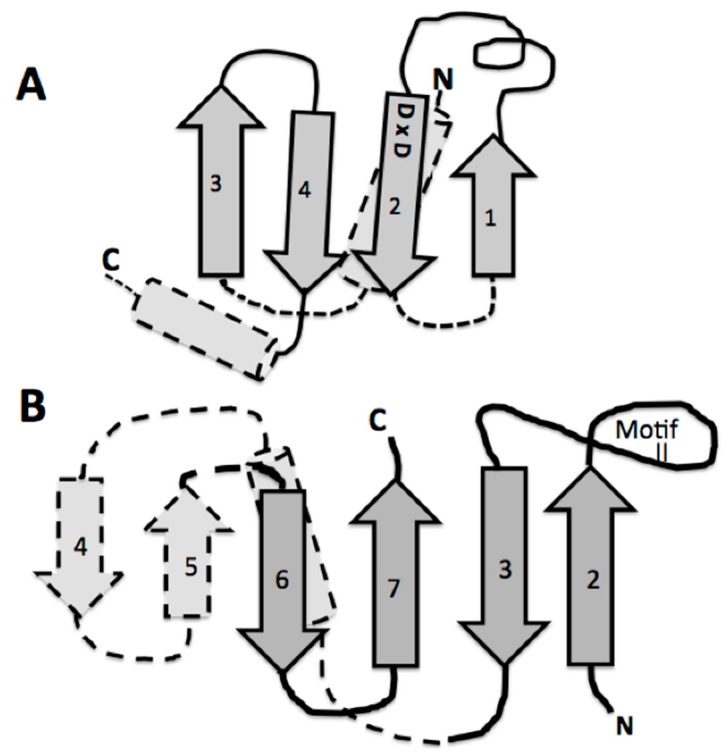
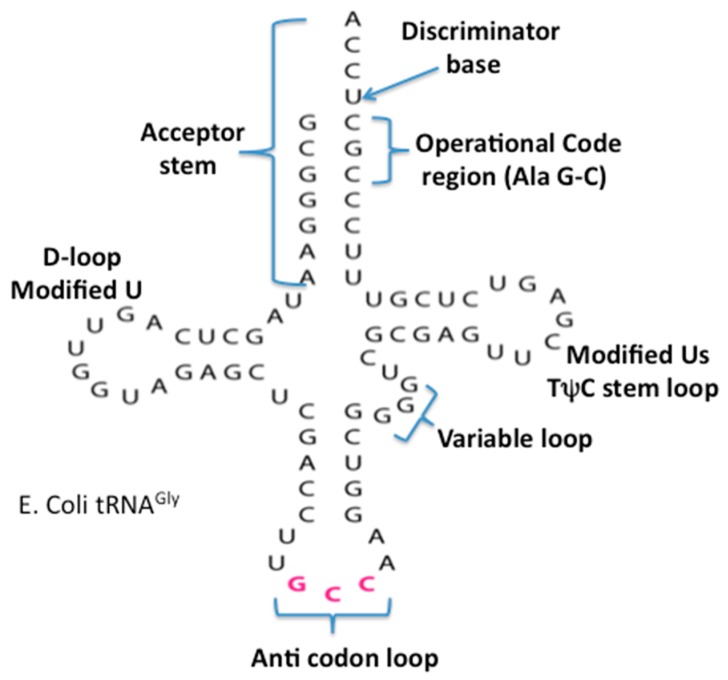
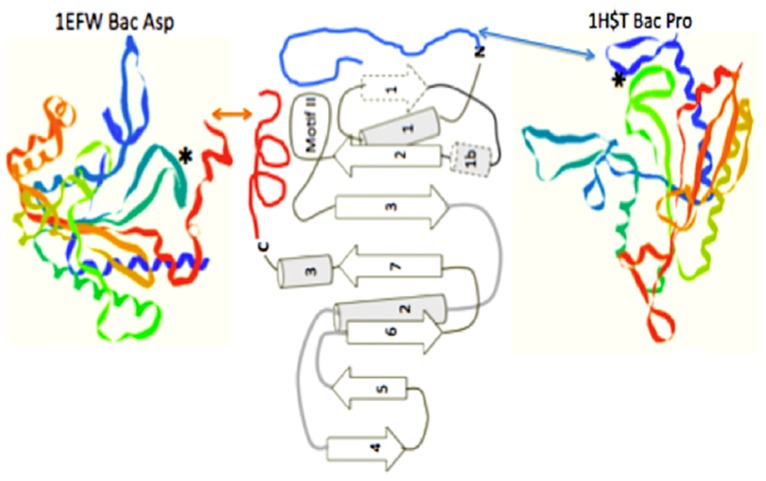
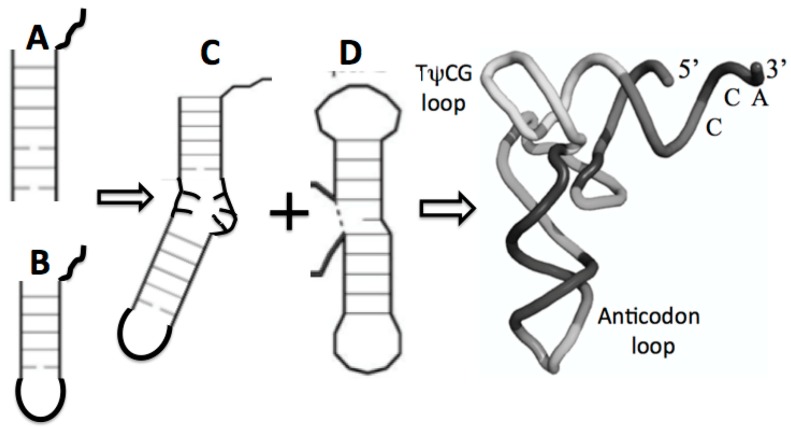
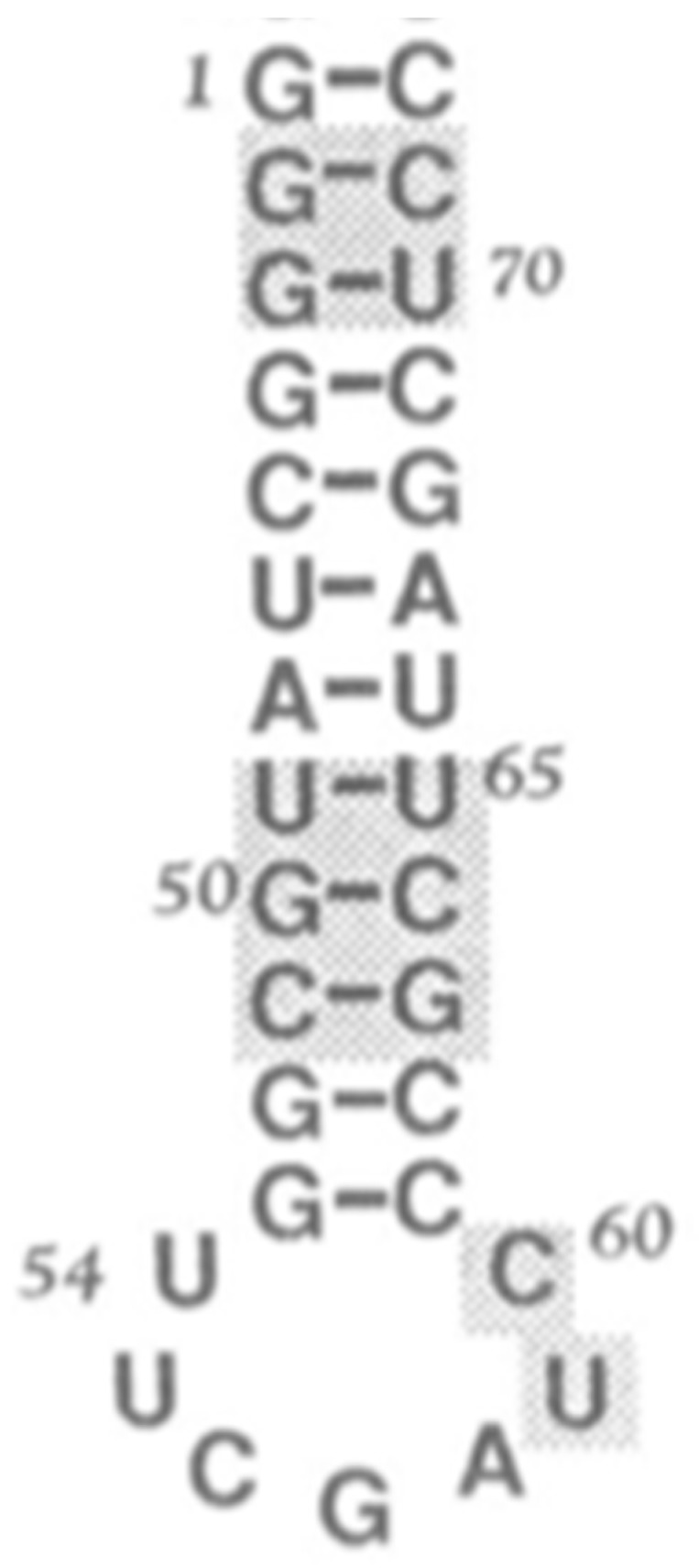
The early metabolism arising in a Thioester world gave rise to amino acids and their simple peptides. The catalytic activity of these early simple peptides became instrumental in the transition from Thioester World to a Phosphate World. This transition involved the appearances of sugar phosphates, nucleotides, and polynucleotides. The coupling of the amino acids and peptides to nucleotides and polynucleotides is the origin for the genetic code. Many of the key steps in this transition are seen in in the catalytic cores of the nucleotidyltransferases, the class II tRNA synthetases (aaRSs) and the CCA adding enzyme. These catalytic cores are dominated by simple beta hairpin structures formed in the Thioester World. The code evolved from a proto-tRNA a tetramer XCCA interacting with a proto-aminoacyl-tRNA synthetase (aaRS) activating Glycine and Proline, the initial expanded code is found in the acceptor arm of the tRNA, the operational code. It is the coevolution of the tRNA with the aaRSs that is at the heart of the origin and evolution of the genetic code. There is also a close relationship between the accretion models of the evolving tRNA and that of the ribosome.
Keywords: early peptides; genetic code origin; metabolism; nucleotidyltransferases; ribosome; tRNA accretion model; tRNA-synthetase; thioester.
Conflict of interest statement
The authors declare no conflicts of interest.
Figures
References
-
- Dyson F. ; Origins of Life. Cambridge Press; Cambridge, UK: 1999.
LinkOut - more resources
Full Text Sources
Miscellaneous
