

Unsupervised Learning on Resistive Memory Array Based Spiking Neural Networks
- PMID: 31447634
- PMCID: PMC6691091
- DOI: 10.3389/fnins.2019.00812
Unsupervised Learning on Resistive Memory Array Based Spiking Neural Networks
Abstract
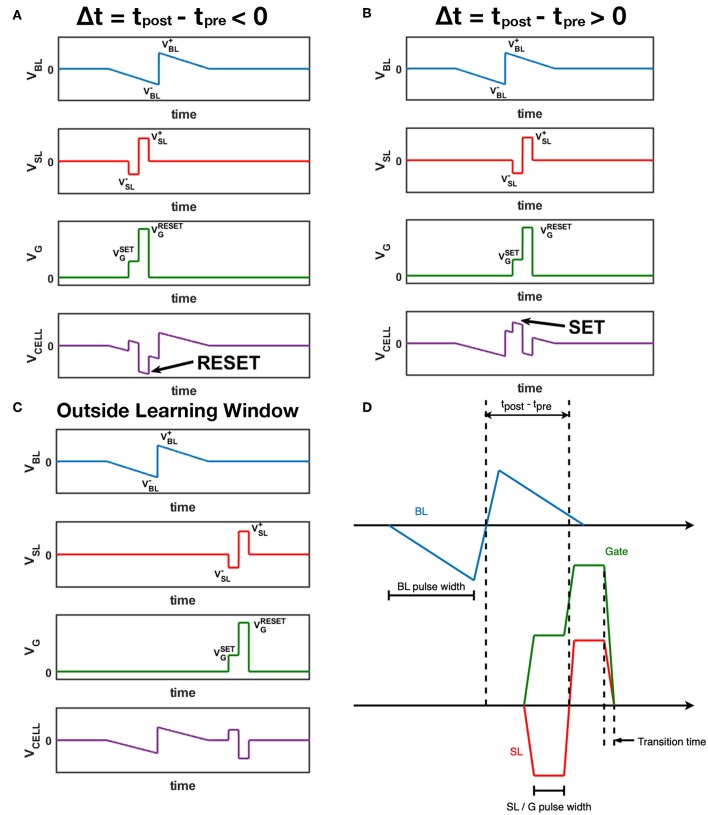
Spiking Neural Networks (SNNs) offer great potential to promote both the performance and efficiency of real-world computing systems, considering the biological plausibility of SNNs. The emerging analog Resistive Random Access Memory (RRAM) devices have drawn increasing interest as potential neuromorphic hardware for implementing practical SNNs. In this article, we propose a novel training approach (called greedy training) for SNNs by diluting spike events on the temporal dimension with necessary controls on input encoding phase switching, endowing SNNs with the ability to cooperate with the inevitable conductance variations of RRAM devices. The SNNs could utilize Spike-Timing-Dependent Plasticity (STDP) as the unsupervised learning rule, and this plasticity has been observed on our one-transistor-one-resistor (1T1R) RRAM devices under voltage pulses with designed waveforms. We have also conducted handwritten digit recognition task simulations on MNIST dataset. The results show that the unsupervised SNNs trained by the proposed method could mitigate the requirement for the number of gradual levels of RRAM devices, and also have immunity to both cycle-to-cycle and device-to-device RRAM conductance variations. Unsupervised SNNs trained by the proposed methods could cooperate with real RRAM devices with non-ideal behaviors better, promising high feasibility of RRAM array based neuromorphic systems for online training.
Keywords: 1T1R RRAM; RRAM (resistive random access memories); STDP; memristor; spiking neural network (SNN); unsupervised learning.
Figures










References
-
- Agarwal S., Plimpton S. J., Hughart D. R., Hsia A. H., Richter I., Cox J. A., et al. (2016). Resistive memory device requirements for a neural algorithm accelerator, in 2016 International Joint Conference on Neural Networks (IJCNN) (Vancouver, BC: IEEE; ), 929–938. 10.1109/IJCNN.2016.7727298 - DOI
-
- Ambrogio S., Balatti S., Milo V., Carboni R., Wang Z., Calderoni A., et al. (2016). Novel rram-enabled 1t1r synapse capable of low-power stdp via burst-mode communication and real-time unsupervised machine learning, in 2016 IEEE Symposium on VLSI Technology (Honolulu, HI: IEEE; ), 1–2. 10.1109/VLSIT.2016.7573432 - DOI
LinkOut - more resources
Full Text Sources
Other Literature Sources