

Assessment of network module identification across complex diseases
- PMID: 31471613
- PMCID: PMC6719725
- DOI: 10.1038/s41592-019-0509-5
Assessment of network module identification across complex diseases
Abstract
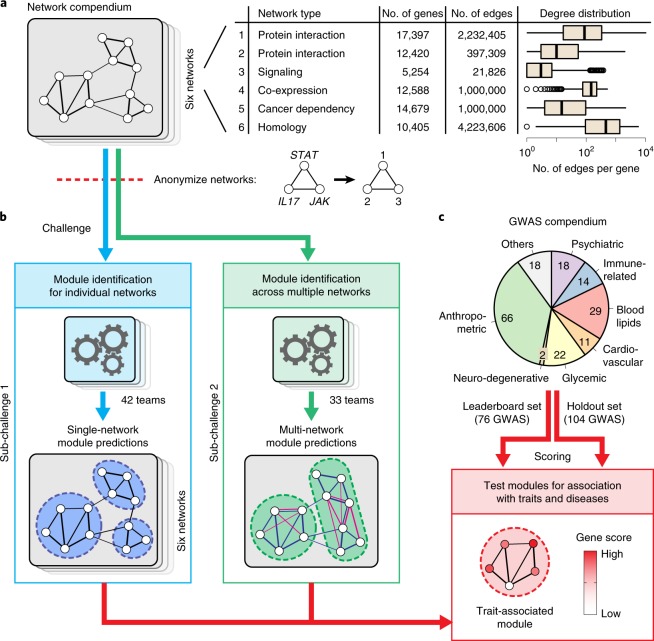
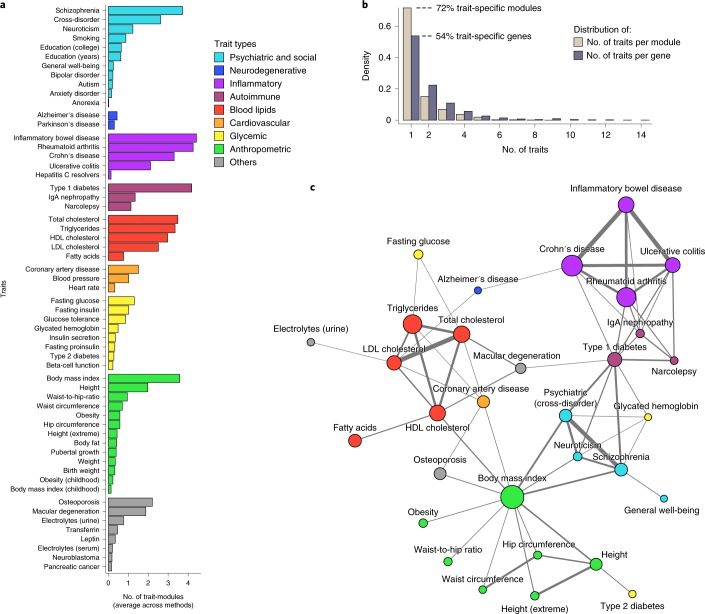
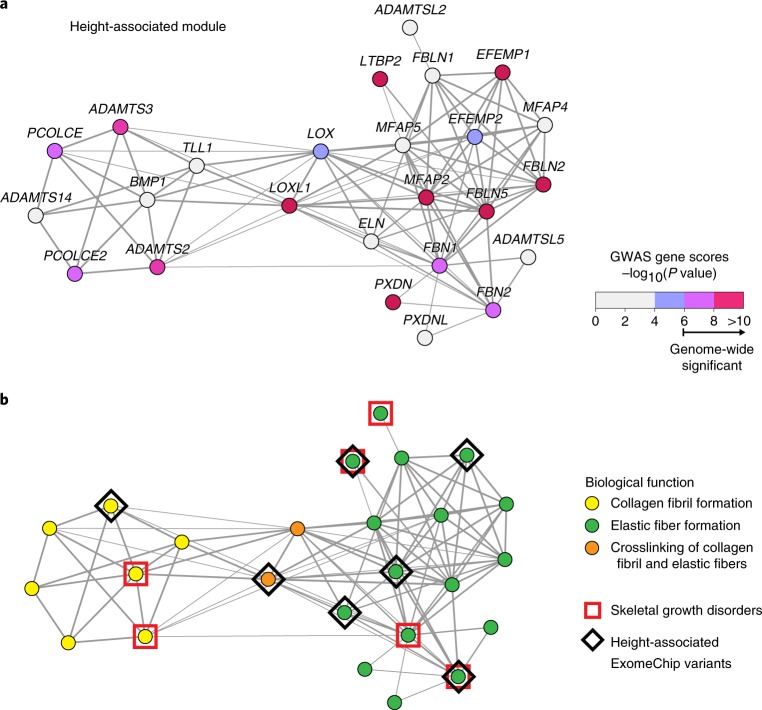
Many bioinformatics methods have been proposed for reducing the complexity of large gene or protein networks into relevant subnetworks or modules. Yet, how such methods compare to each other in terms of their ability to identify disease-relevant modules in different types of network remains poorly understood. We launched the 'Disease Module Identification DREAM Challenge', an open competition to comprehensively assess module identification methods across diverse protein-protein interaction, signaling, gene co-expression, homology and cancer-gene networks. Predicted network modules were tested for association with complex traits and diseases using a unique collection of 180 genome-wide association studies. Our robust assessment of 75 module identification methods reveals top-performing algorithms, which recover complementary trait-associated modules. We find that most of these modules correspond to core disease-relevant pathways, which often comprise therapeutic targets. This community challenge establishes biologically interpretable benchmarks, tools and guidelines for molecular network analysis to study human disease biology.
Conflict of interest statement
The authors declare no competing interests.
Figures



References
Publication types
MeSH terms
Grants and funding
LinkOut - more resources
Full Text Sources
Other Literature Sources
