

Creating reproducible pharmacogenomic analysis pipelines
- PMID: 31481707
- PMCID: PMC6722117
- DOI: 10.1038/s41597-019-0174-7
Creating reproducible pharmacogenomic analysis pipelines
Abstract
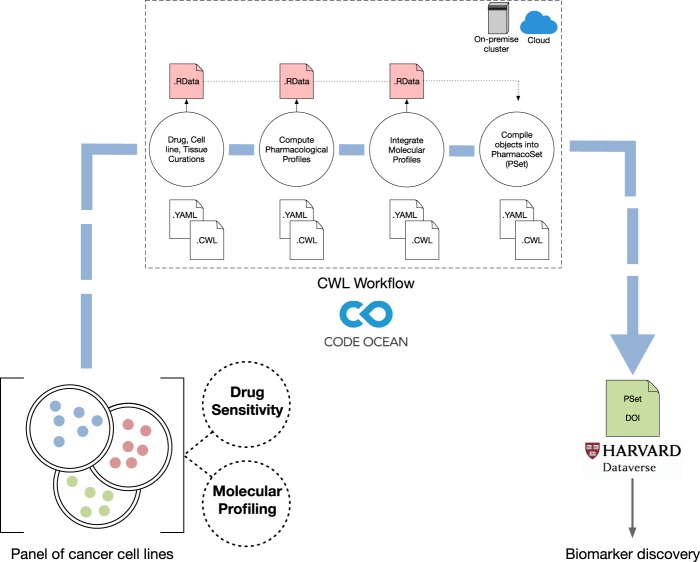
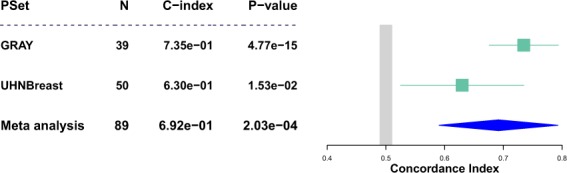
The field of pharmacogenomics presents great challenges for researchers that are willing to make their studies reproducible and shareable. This is attributed to the generation of large volumes of high-throughput multimodal data, and the lack of standardized workflows that are robust, scalable, and flexible to perform large-scale analyses. To address this issue, we developed pharmacogenomic workflows in the Common Workflow Language to process two breast cancer datasets in a reproducible and transparent manner. Our pipelines combine both pharmacological and molecular profiles into a portable data object that can be used for future analyses in cancer research. Our data objects and workflows are shared on Harvard Dataverse and Code Ocean where they have been assigned a unique Digital Object Identifier, providing a level of data provenance and a persistent location to access and share our data with the community.
Conflict of interest statement
The authors declare no competing interests.
Figures

References
-
- Sivarajah U, Kamal MM, Irani Z, Weerakkody V. Critical analysis of Big Data challenges and analytical methods. J. Bus. Res. 2017;70:263–286. doi: 10.1016/j.jbusres.2016.08.001. - DOI
-
- Oussous A, Benjelloun F-Z, Ait Lahcen A, Belfkih S. Big Data technologies: A survey. Journal of King Saud University - Computer and Information Sciences. 2018;30:431–448. doi: 10.1016/j.jksuci.2017.06.001. - DOI
-
- Xu Z, Shi Y. Exploring Big Data Analysis: Fundamental Scientific Problems. Annals of Data Science. 2015;2:363–372. doi: 10.1007/s40745-015-0063-7. - DOI
MeSH terms
LinkOut - more resources
Full Text Sources
