

Statistical considerations for testing an AI algorithm used for prescreening lung CT images
- PMID: 31485545
- PMCID: PMC6717063
- DOI: 10.1016/j.conctc.2019.100434
Statistical considerations for testing an AI algorithm used for prescreening lung CT images
Erratum in
-
Erratum regarding missing Declaration of Competing Interest statements in previously published articles.Contemp Clin Trials Commun. 2020 Dec 10;20:100689. doi: 10.1016/j.conctc.2020.100689. eCollection 2020 Dec. Contemp Clin Trials Commun. 2020. PMID: 33392413 Free PMC article.
Abstract
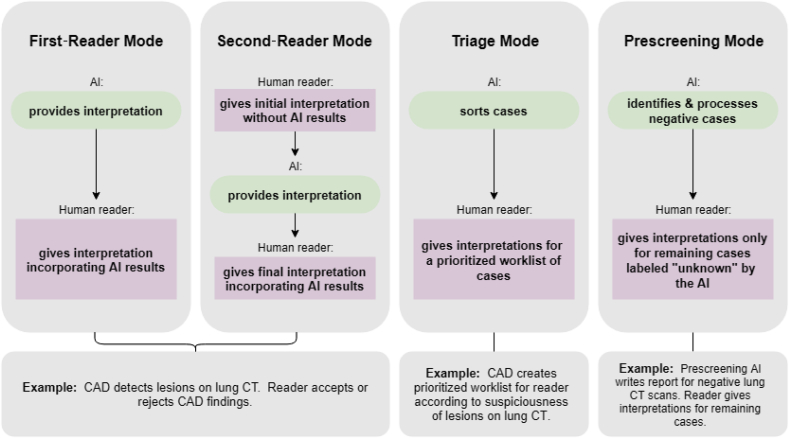
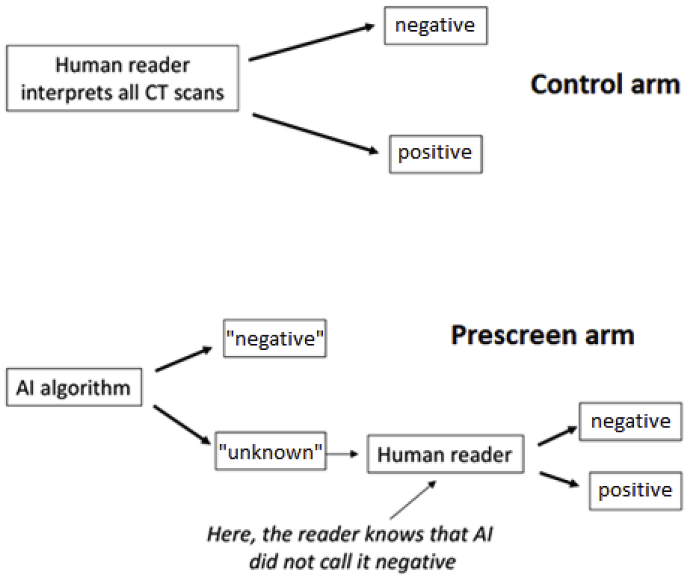
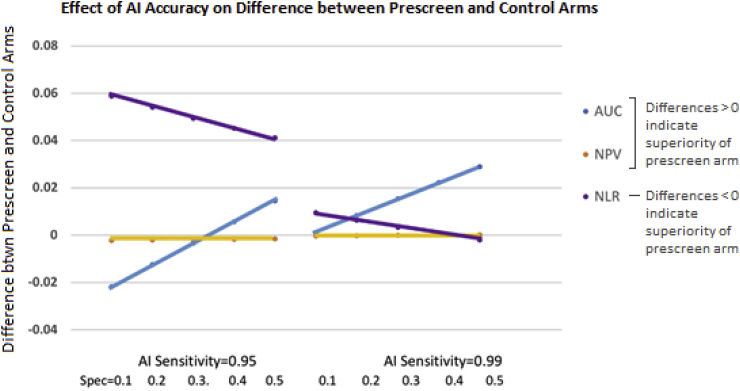
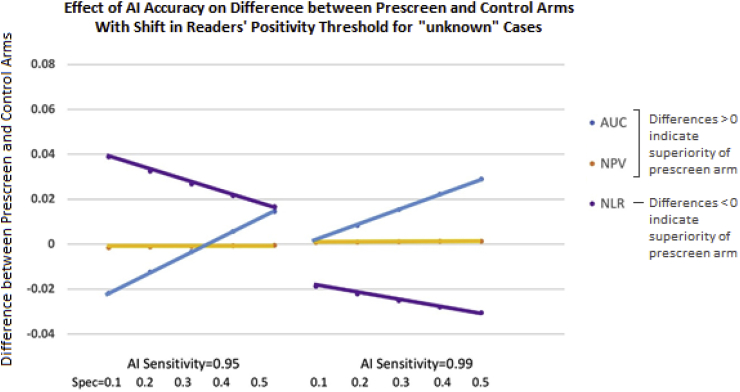
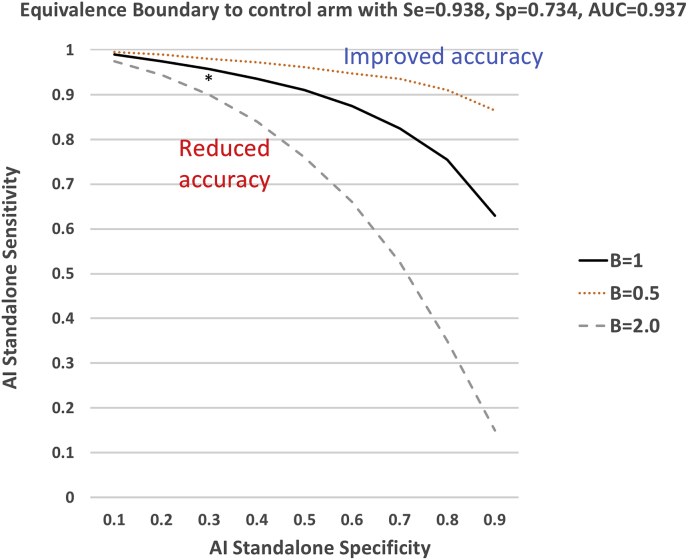
Artificial intelligence, as applied to medical images to detect, rule out, diagnose, and stage disease, has seen enormous growth over the last few years. There are multiple use cases of AI algorithms in medical imaging: first-reader (or concurrent) mode, second-reader mode, triage mode, and more recently prescreening mode as when an AI algorithm is applied to the worklist of images to identify obvious negative cases so that human readers do not need to review them and can focus on interpreting the remaining cases. In this paper we describe the statistical considerations for designing a study to test a new AI prescreening algorithm for identifying normal lung cancer screening CTs. We contrast agreement vs. accuracy studies, and retrospective vs. prospective designs. We evaluate various test performance metrics with respect to their sensitivity to changes in the AI algorithm's performance, as well as to shifts in reader behavior to a revised worklist. We consider sample size requirements for testing the AI prescreening algorithm.
Keywords: Area under the ROC curve; Artificial intelligence; Computer-aided detection; Diagnostic accuracy; Diagnostic accuracy studies; Prescreening.
Figures
References
-
- Park S.H.P., Han K. Methodologic guide for evaluating clinical performance and effect of artificial intelligence technology for medical diagnosis and prediction. Radiology. 2018;286:800–809. - PubMed
-
- Pepe M.S., Alonzo T.A. Comparing disease screening tests when true disease status is ascertained only for screen positives. Biostatistics. 2001;2:249–260. - PubMed
LinkOut - more resources
Full Text Sources
Other Literature Sources
Research Materials
