

Multi-agent reinforcement learning with approximate model learning for competitive games
- PMID: 31509568
- PMCID: PMC6739057
- DOI: 10.1371/journal.pone.0222215
Multi-agent reinforcement learning with approximate model learning for competitive games
Abstract
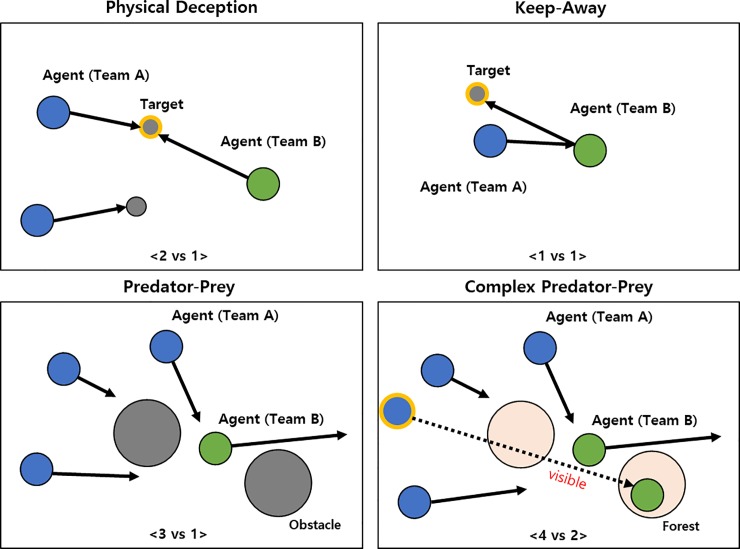
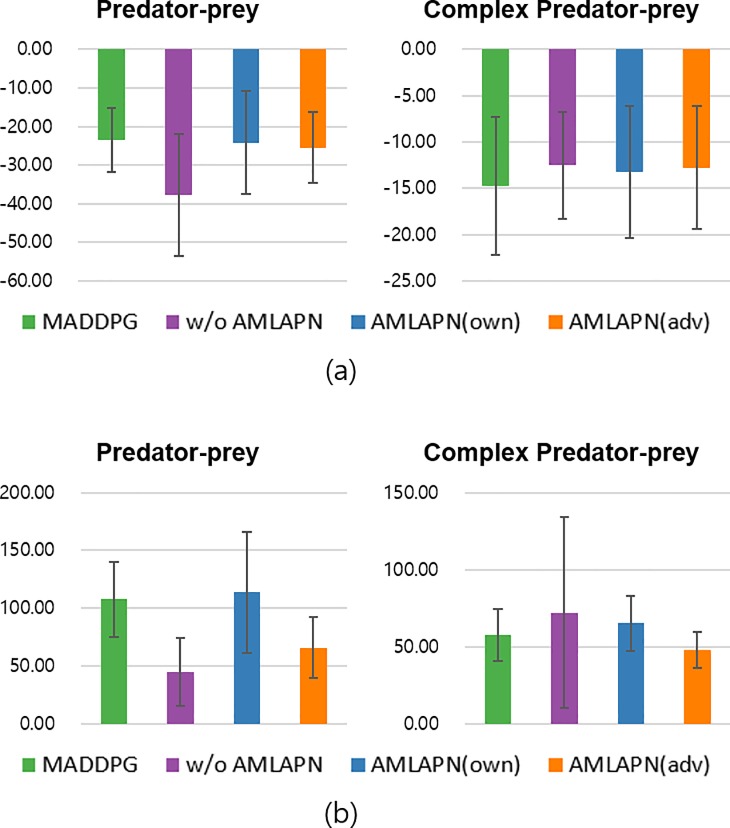
We propose a method for learning multi-agent policies to compete against multiple opponents. The method consists of recurrent neural network-based actor-critic networks and deterministic policy gradients that promote cooperation between agents by communication. The learning process does not require access to opponents' parameters or observations because the agents are trained separately from the opponents. The actor networks enable the agents to communicate using forward and backward paths while the critic network helps to train the actors by delivering them gradient signals based on their contribution to the global reward. Moreover, to address nonstationarity due to the evolving of other agents, we propose approximate model learning using auxiliary prediction networks for modeling the state transitions, reward function, and opponent behavior. In the test phase, we use competitive multi-agent environments to demonstrate by comparison the usefulness and superiority of the proposed method in terms of learning efficiency and goal achievements. The comparison results show that the proposed method outperforms the alternatives.
Conflict of interest statement
The authors have declared that no competing interests exist.
Figures





Similar articles
-
Optimistic sequential multi-agent reinforcement learning with motivational communication.Neural Netw. 2024 Nov;179:106547. doi: 10.1016/j.neunet.2024.106547. Epub 2024 Jul 22. Neural Netw. 2024. PMID: 39068677
-
Semicentralized Deep Deterministic Policy Gradient in Cooperative StarCraft Games.IEEE Trans Neural Netw Learn Syst. 2022 Apr;33(4):1584-1593. doi: 10.1109/TNNLS.2020.3042943. Epub 2022 Apr 4. IEEE Trans Neural Netw Learn Syst. 2022. PMID: 33351767
-
Meta attention for Off-Policy Actor-Critic.Neural Netw. 2023 Jun;163:86-96. doi: 10.1016/j.neunet.2023.03.024. Epub 2023 Mar 28. Neural Netw. 2023. PMID: 37030278
-
All by Myself: Learning individualized competitive behavior with a contrastive reinforcement learning optimization.Neural Netw. 2022 Jun;150:364-376. doi: 10.1016/j.neunet.2022.03.013. Epub 2022 Mar 18. Neural Netw. 2022. PMID: 35358886
-
Competitive and cooperative games for probing the neural basis of social decision-making in animals.Neurosci Biobehav Rev. 2023 Jun;149:105158. doi: 10.1016/j.neubiorev.2023.105158. Epub 2023 Apr 4. Neurosci Biobehav Rev. 2023. PMID: 37019249 Free PMC article. Review.
Cited by
-
Sample-efficient multi-agent reinforcement learning with masked reconstruction.PLoS One. 2023 Sep 14;18(9):e0291545. doi: 10.1371/journal.pone.0291545. eCollection 2023. PLoS One. 2023. PMID: 37708154 Free PMC article.
-
Image Classification Method Based on Multi-Agent Reinforcement Learning for Defects Detection for Casting.Sensors (Basel). 2022 Jul 8;22(14):5143. doi: 10.3390/s22145143. Sensors (Basel). 2022. PMID: 35890824 Free PMC article.
References
-
- Cao Y., Yu W., Ren W., & Chen G. (2013). An Overview of Recent Progress in the Study of Distributed Multi-Agent Coordination. IEEE Transactions on Industrial Informatics, 9(1), 427–438. 10.1109/TII.2012.2219061 - DOI
-
- Ying W., & Dayong S. (2005). Multi-agent framework for third party logistics in E-commerce. Expert Systems with Applications, 29(2), 431–436. 10.1016/j.eswa.2005.04.039 - DOI
-
- Matarić M. J. (1997). Reinforcement Learning in the Multi-Robot Domain. Autonomous Robots, 4(1), 73–83. 10.1023/A:1008819414322 - DOI
-
- Jaderberg M., Czarnecki W. M., Dunning I., Marris L., Lever G., Castaneda A. G., et al. (2018). Human-level performance in first-person multiplayer games with population-based deep reinforcement learning. Retrieved from https://arxiv.org/abs/1807.01281v1 - PubMed
Publication types
MeSH terms
LinkOut - more resources
Full Text Sources
