

Enabling Web-scale data integration in biomedicine through Linked Open Data
- PMID: 31531395
- PMCID: PMC6736878
- DOI: 10.1038/s41746-019-0162-5
Enabling Web-scale data integration in biomedicine through Linked Open Data
Abstract
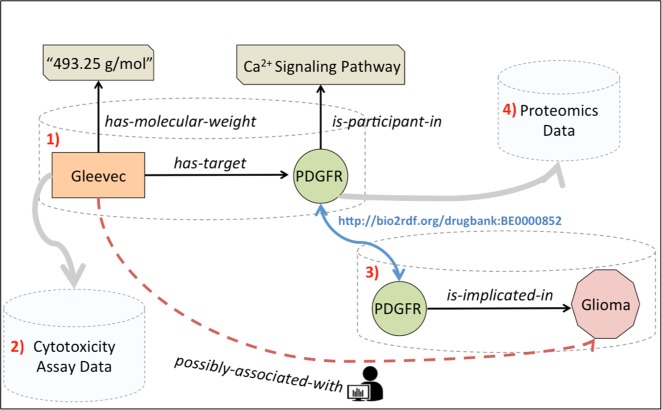
The biomedical data landscape is fragmented with several isolated, heterogeneous data and knowledge sources, which use varying formats, syntaxes, schemas, and entity notations, existing on the Web. Biomedical researchers face severe logistical and technical challenges to query, integrate, analyze, and visualize data from multiple diverse sources in the context of available biomedical knowledge. Semantic Web technologies and Linked Data principles may aid toward Web-scale semantic processing and data integration in biomedicine. The biomedical research community has been one of the earliest adopters of these technologies and principles to publish data and knowledge on the Web as linked graphs and ontologies, hence creating the Life Sciences Linked Open Data (LSLOD) cloud. In this paper, we provide our perspective on some opportunities proffered by the use of LSLOD to integrate biomedical data and knowledge in three domains: (1) pharmacology, (2) cancer research, and (3) infectious diseases. We will discuss some of the major challenges that hinder the wide-spread use and consumption of LSLOD by the biomedical research community. Finally, we provide a few technical solutions and insights that can address these challenges. Eventually, LSLOD can enable the development of scalable, intelligent infrastructures that support artificial intelligence methods for augmenting human intelligence to achieve better clinical outcomes for patients, to enhance the quality of biomedical research, and to improve our understanding of living systems.
Keywords: Computational platforms and environments; Data integration; Databases.
Conflict of interest statement
Competing interestsThe authors declare no competing interests.
Figures


References
-
- Wetterstrand, K. A. DNA sequencing costs: Data from the NHGRI genome sequencing program (GSP). www.genome.gov/sequencingcostsdata. Accessed 30 May 2018.
-
- Islam SR, Kwak D, Kabir MH, Hossain M, Kwak K-S. The internet of things for health care: a comprehensive survey. IEEE Access. 2015;3:678–708. doi: 10.1109/ACCESS.2015.2437951. - DOI
Publication types
Grants and funding
LinkOut - more resources
Full Text Sources
