

Deep MR Brain Image Super-Resolution Using Spatio-Structural Priors
- PMID: 31562091
- PMCID: PMC7335214
- DOI: 10.1109/TIP.2019.2942510
Deep MR Brain Image Super-Resolution Using Spatio-Structural Priors
Abstract
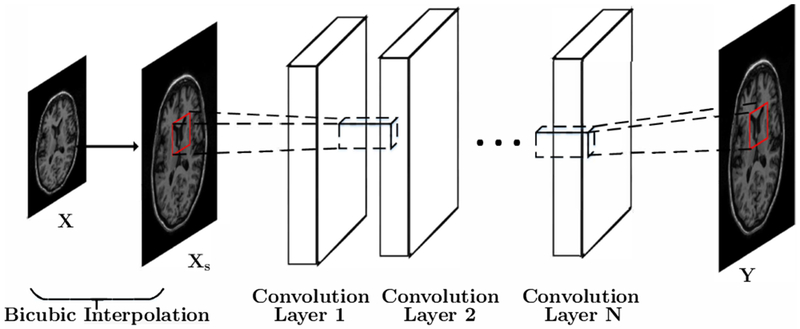
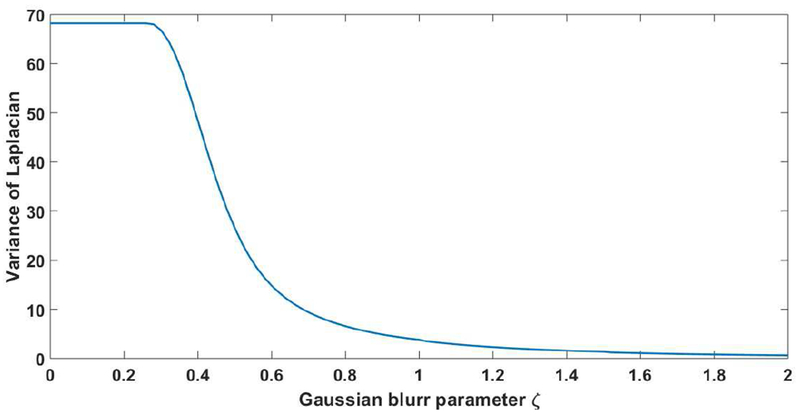
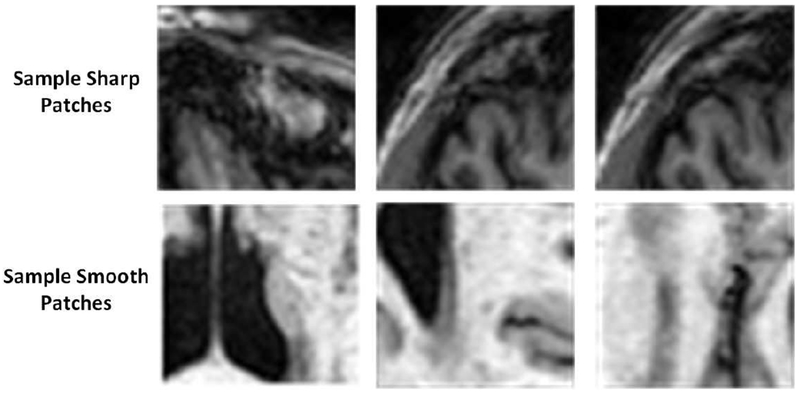
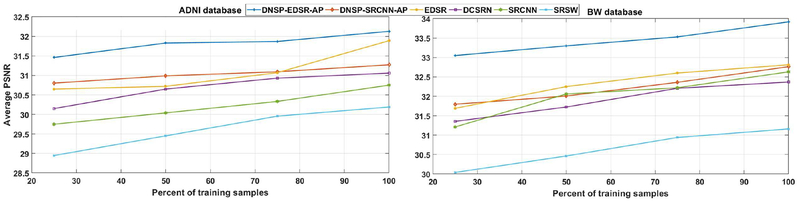
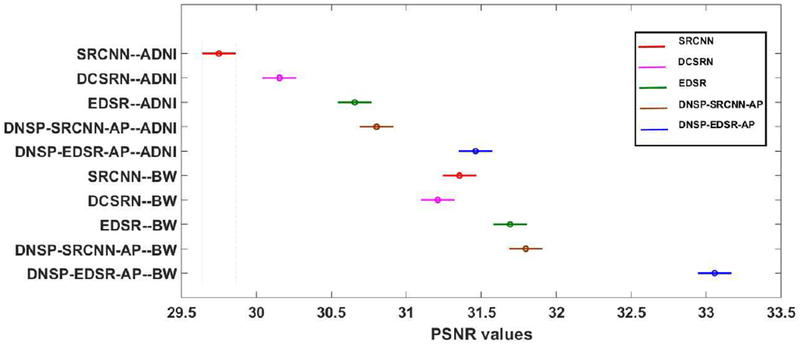
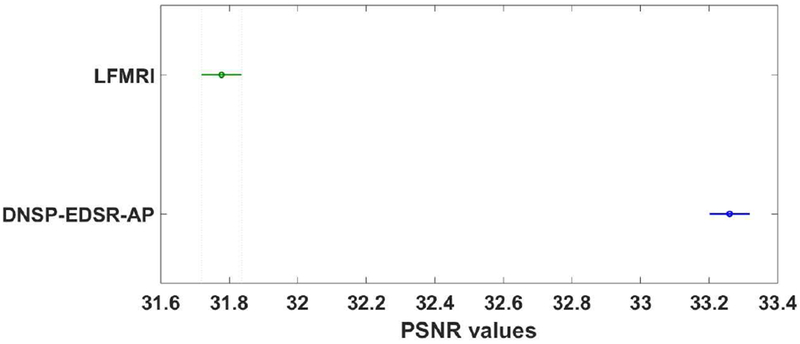
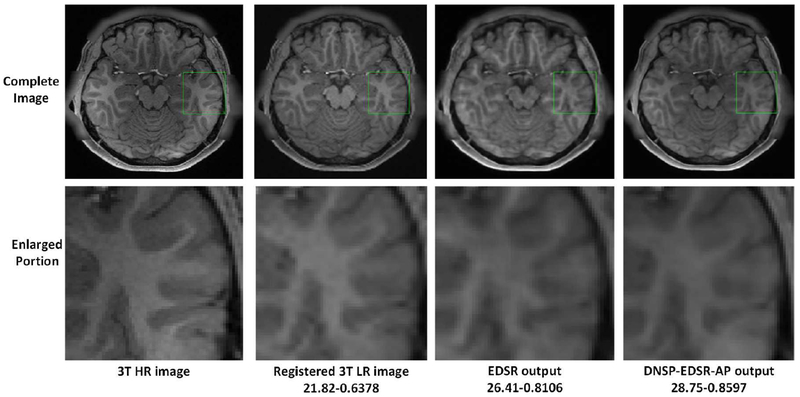
High resolution Magnetic Resonance (MR) images are desired for accurate diagnostics. In practice, image resolution is restricted by factors like hardware and processing constraints. Recently, deep learning methods have been shown to produce compelling state-of-the-art results for image enhancement/super-resolution. Paying particular attention to desired hi-resolution MR image structure, we propose a new regularized network that exploits image priors, namely a low-rank structure and a sharpness prior to enhance deep MR image super-resolution (SR). Our contributions are then incorporating these priors in an analytically tractable fashion as well as towards a novel prior guided network architecture that accomplishes the super-resolution task. This is particularly challenging for the low rank prior since the rank is not a differentiable function of the image matrix (and hence the network parameters), an issue we address by pursuing differentiable approximations of the rank. Sharpness is emphasized by the variance of the Laplacian which we show can be implemented by a fixed feedback layer at the output of the network. As a key extension, we modify the fixed feedback (Laplacian) layer by learning a new set of training data driven filters that are optimized for enhanced sharpness. Experiments performed on publicly available MR brain image databases and comparisons against existing state-of-the-art methods show that the proposed prior guided network offers significant practical gains in terms of improved SNR/image quality measures. Because our priors are on output images, the proposed method is versatile and can be combined with a wide variety of existing network architectures to further enhance their performance.
Figures














References
-
- Lehmann TM, Gonner C, and Spitzer K, “Survey: Interpolation methods in medical image processing,” IEEE Trans. on Medical Imaging, vol. 18, no. 11, pp. 1049–1075, 1999. - PubMed
-
- Tsai R, “Multiframe image restoration and registration,” Adv. Comput. Vis. Image Process, vol. 1, no. 2, pp. 317–339, 1984.
-
- Farsiu S, Robinson MD, Elad M, and Milanfar P, “Fast and robust multiframe super resolution,” IEEE Trans. on Image Processing, vol. 13, no. 10, pp. 1327–1344, 2004. - PubMed
-
- Trinh D-H, Luong M, Dibos F, Rocchisani J-M, Pham C-D, and Nguyen TQ, “Novel example-based method for super-resolution and denoising of medical images,” IEEE Trans. on Image Processing, vol. 23, pp. 1882–1895, 2014. - PubMed
-
- Freeman WT, Jones TR, and Pasztor EC, “Example-based super-resolution,” Computer Graphics and Applications, vol. 22, no. 2, pp. 56–65, 2002.
Grants and funding
LinkOut - more resources
Full Text Sources
Research Materials
