

Breast Cancer Diagnosis in Digital Breast Tomosynthesis: Effects of Training Sample Size on Multi-Stage Transfer Learning Using Deep Neural Nets
- PMID: 31622238
- PMCID: PMC6812655
- DOI: 10.1109/TMI.2018.2870343
Breast Cancer Diagnosis in Digital Breast Tomosynthesis: Effects of Training Sample Size on Multi-Stage Transfer Learning Using Deep Neural Nets
Abstract
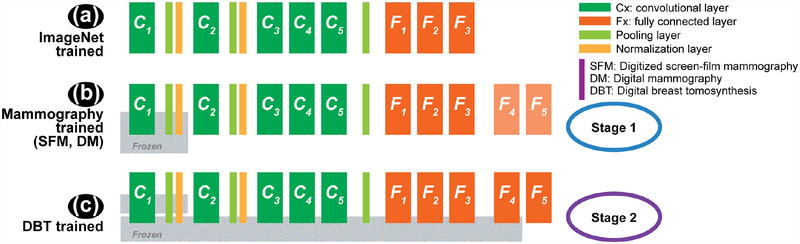
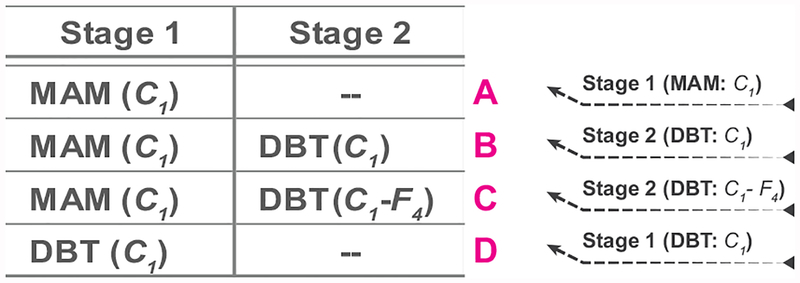
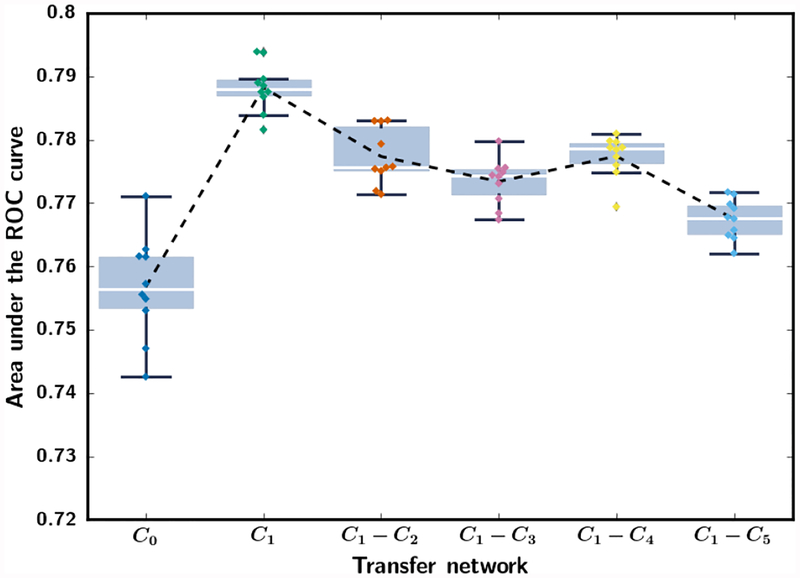
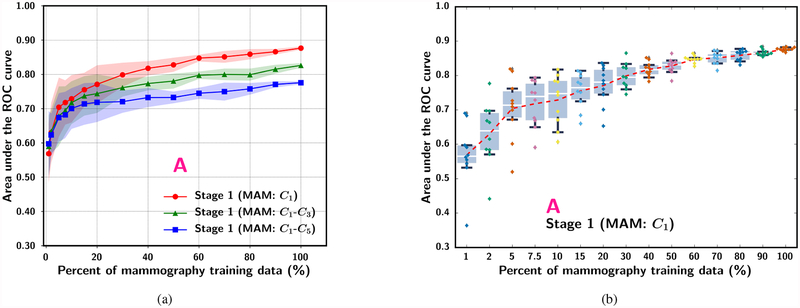
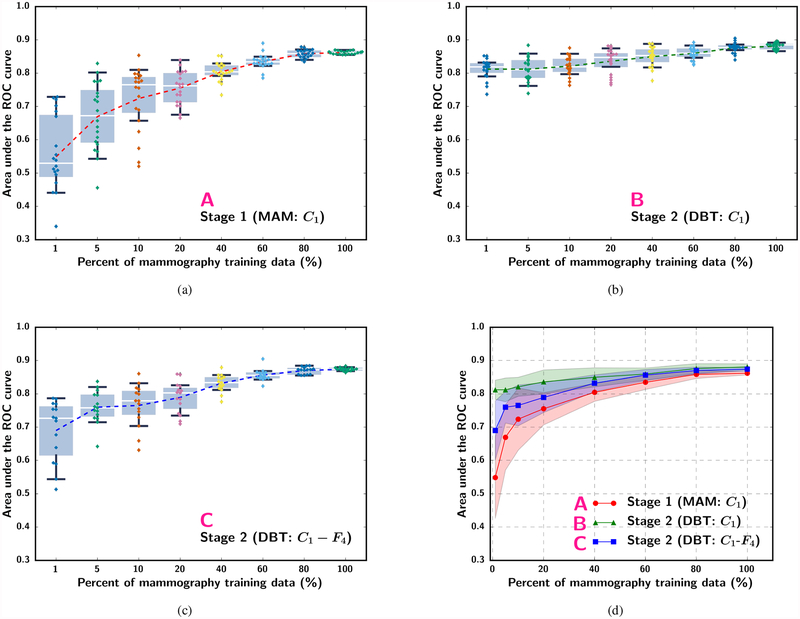
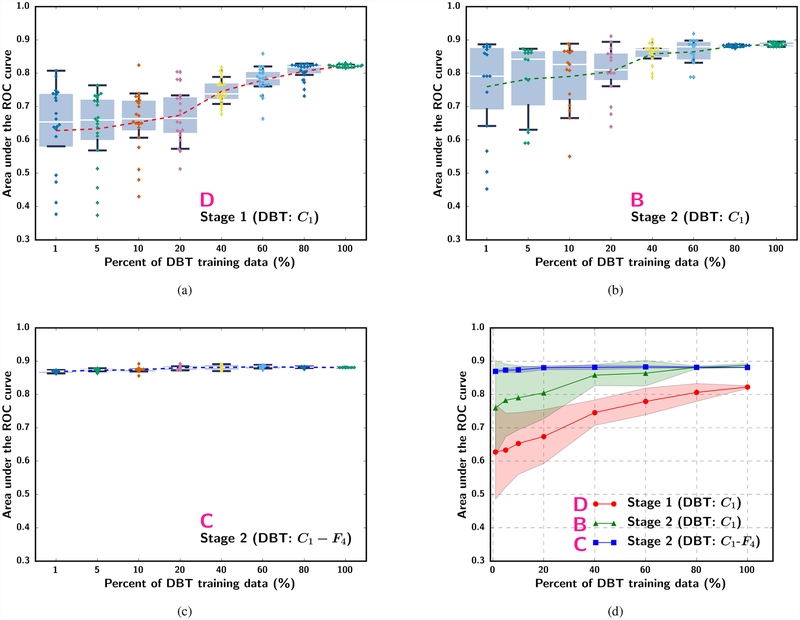
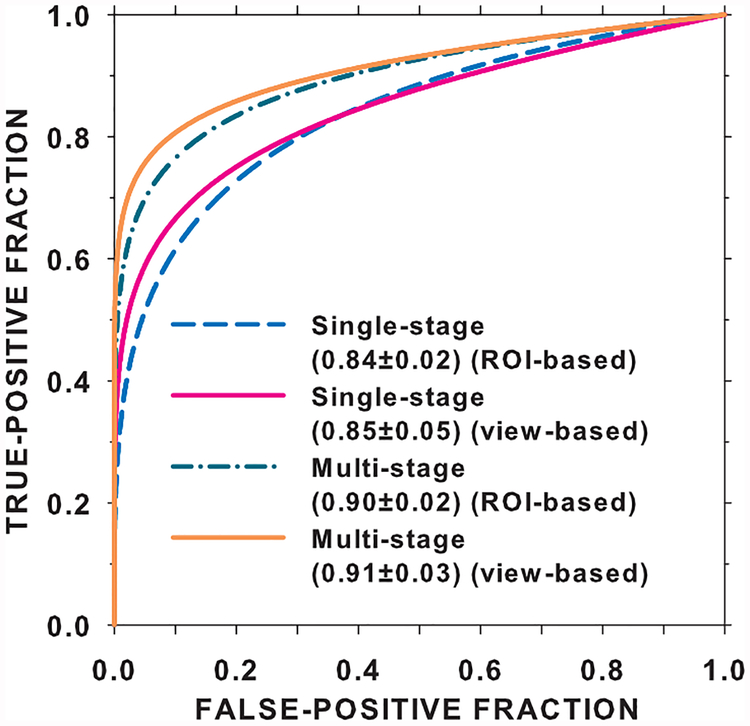
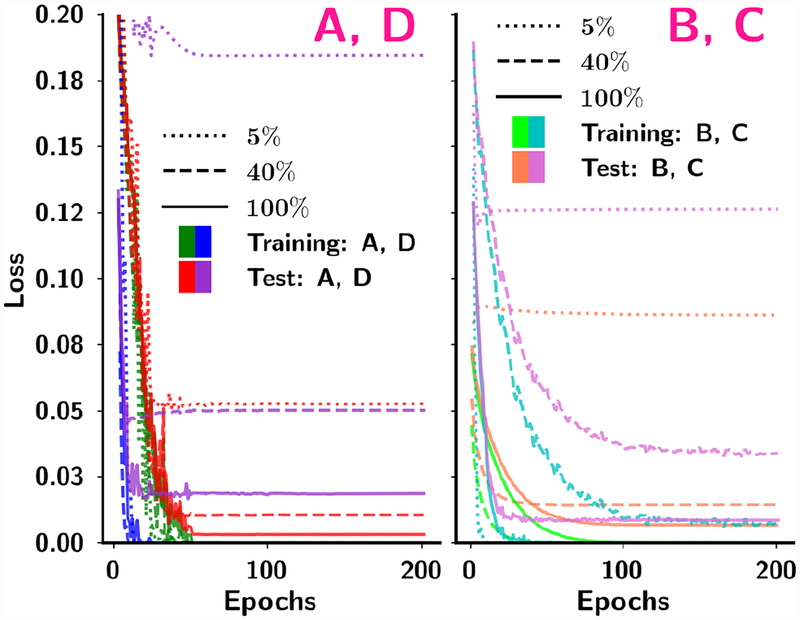
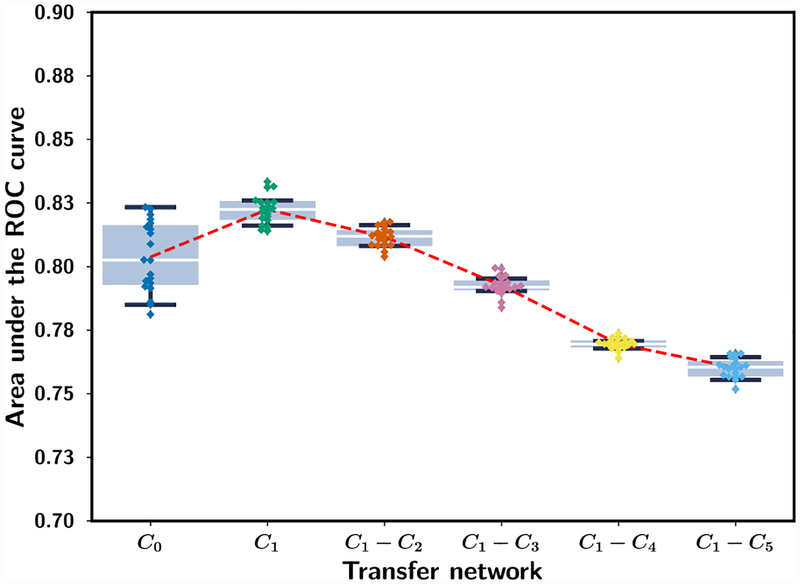
In this paper, we developed a deep convolutional neural network (CNN) for the classification of malignant and benign masses in digital breast tomosynthesis (DBT) using a multi-stage transfer learning approach that utilized data from similar auxiliary domains for intermediate-stage fine-tuning. Breast imaging data from DBT, digitized screen-film mammography, and digital mammography totaling 4039 unique regions of interest (1797 malignant and 2242 benign) were collected. Using cross validation, we selected the best transfer network from six transfer networks by varying the level up to which the convolutional layers were frozen. In a single-stage transfer learning approach, knowledge from CNN trained on the ImageNet data was fine-tuned directly with the DBT data. In a multi-stage transfer learning approach, knowledge learned from ImageNet was first fine-tuned with the mammography data and then fine-tuned with the DBT data. Two transfer networks were compared for the second-stage transfer learning by freezing most of the CNN structures versus freezing only the first convolutional layer. We studied the dependence of the classification performance on training sample size for various transfer learning and fine-tuning schemes by varying the training data from 1% to 100% of the available sets. The area under the receiver operating characteristic curve (AUC) was used as a performance measure. The view-based AUC on the test set for single-stage transfer learning was 0.85 ± 0.05 and improved significantly (p <; 0.05$ ) to 0.91 ± 0.03 for multi-stage learning. This paper demonstrated that, when the training sample size from the target domain is limited, an additional stage of transfer learning using data from a similar auxiliary domain is advantageous.
Figures
References
-
- Litjens G, Kooi T, Bejnordi BE, Setio AAA, Ciompi F,Ghafoorian M, van der Laak JA, van Ginneken B, and Snchez CI, “A survey on deep learning in medical image analysis,” Medical Image Analysis, vol. 42, pp. 60–88, 2017. - PubMed
-
- Yosinski J, Clune J, Bengio Y, and Lipson H, “How transferable are features in deep neural networks?” in Advances in neural information processing systems, 2014, pp. 3320–3328.
-
- National Center for Health Statistics, “Health, United States, 2015: With special feature on racial and ethnic health disparities.” Hyattsville, MD., Report no. 2016–1232, 2016. - PubMed
-
- US FOOD & DRUG ADMINISTRATION, “MQSA National Statistics,” accessed 03-August-2017 [Online]. Available: www.fda.gov/Radiation-EmittingProducts/MammographyQualityStandardsActand...
Publication types
MeSH terms
Grants and funding
LinkOut - more resources
Full Text Sources
Other Literature Sources
Medical
