

Hierarchical Encoding of Attended Auditory Objects in Multi-talker Speech Perception
- PMID: 31648900
- PMCID: PMC8082956
- DOI: 10.1016/j.neuron.2019.09.007
Hierarchical Encoding of Attended Auditory Objects in Multi-talker Speech Perception
Abstract
Humans can easily focus on one speaker in a multi-talker acoustic environment, but how different areas of the human auditory cortex (AC) represent the acoustic components of mixed speech is unknown. We obtained invasive recordings from the primary and nonprimary AC in neurosurgical patients as they listened to multi-talker speech. We found that neural sites in the primary AC responded to individual speakers in the mixture and were relatively unchanged by attention. In contrast, neural sites in the nonprimary AC were less discerning of individual speakers but selectively represented the attended speaker. Moreover, the encoding of the attended speaker in the nonprimary AC was invariant to the degree of acoustic overlap with the unattended speaker. Finally, this emergent representation of attended speech in the nonprimary AC was linearly predictable from the primary AC responses. Our results reveal the neural computations underlying the hierarchical formation of auditory objects in human AC during multi-talker speech perception.
Keywords: Heschl’s gyrus; auditory object; cocktail party; encoding; hierarchical; human auditory cortex; multi-talker; speech perception; superior temporal gyrus.
Copyright © 2019 Elsevier Inc. All rights reserved.
Conflict of interest statement
DECLARATION OF INTERESTS
The authors declare no competing interests.
Figures
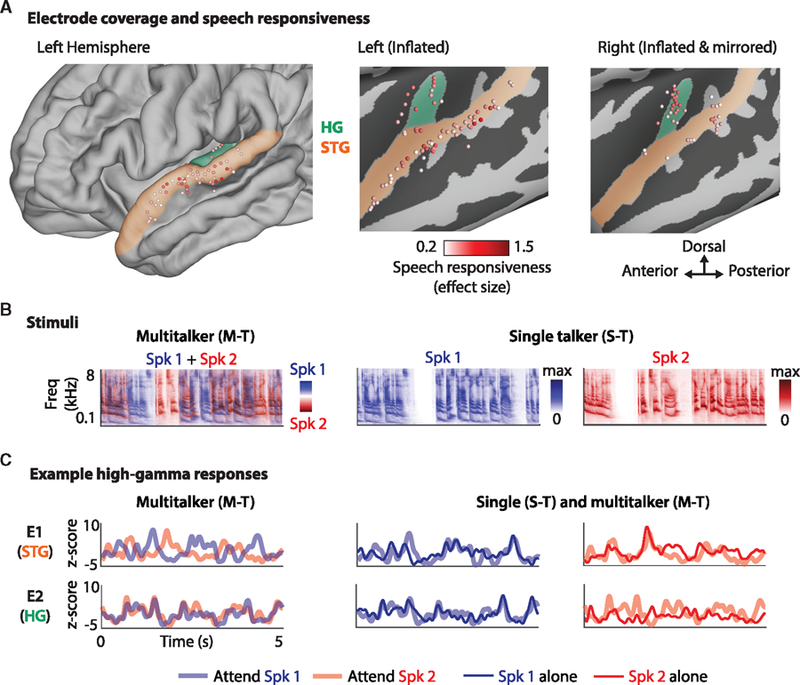
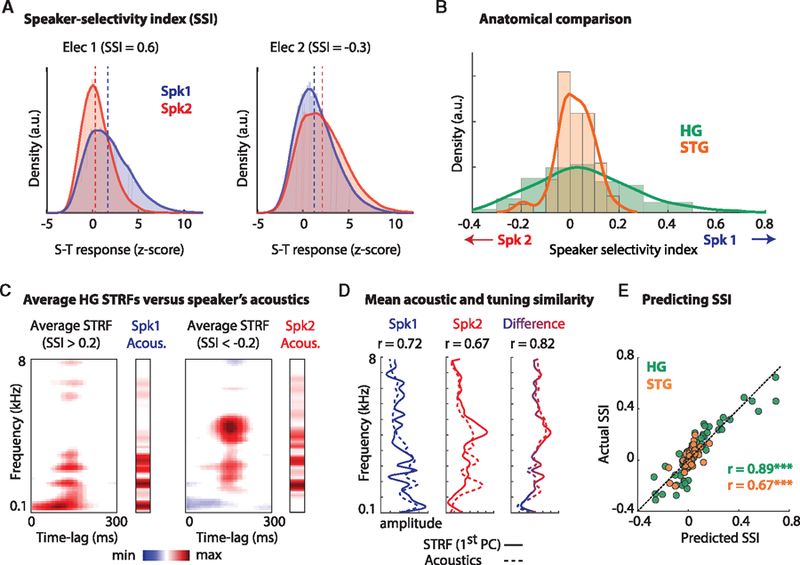
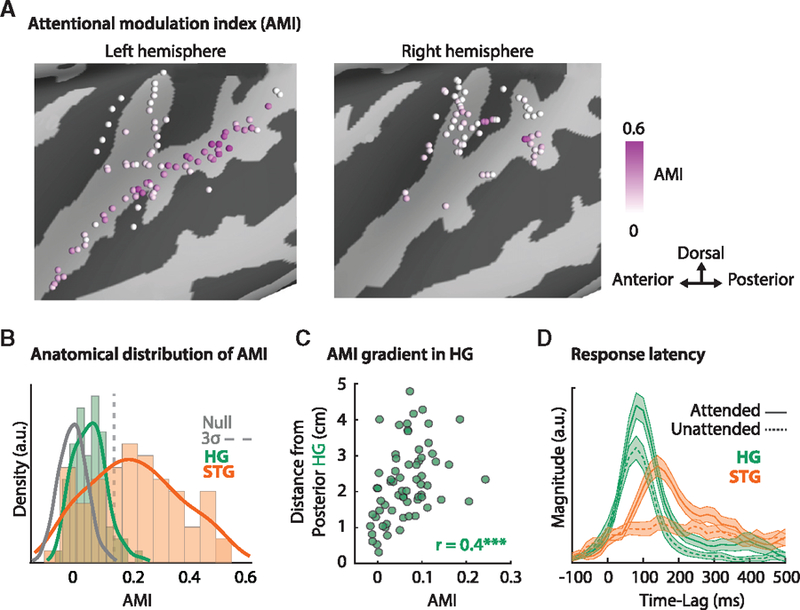
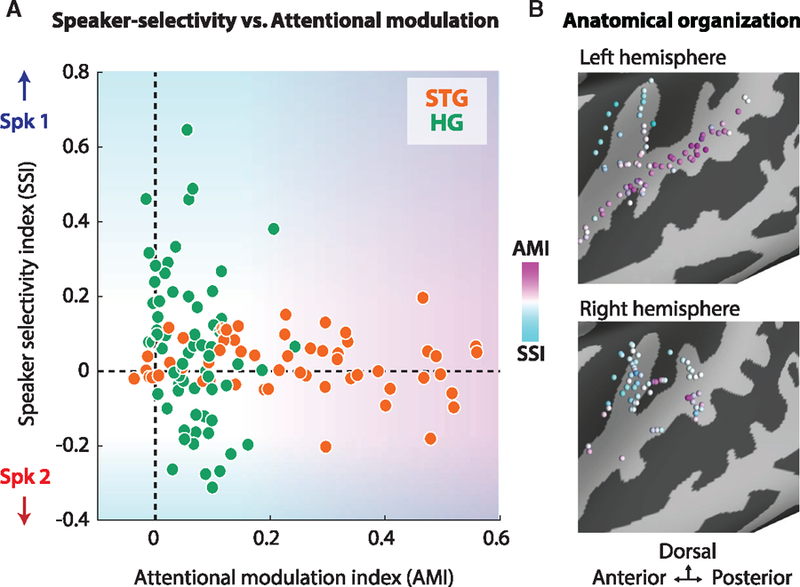
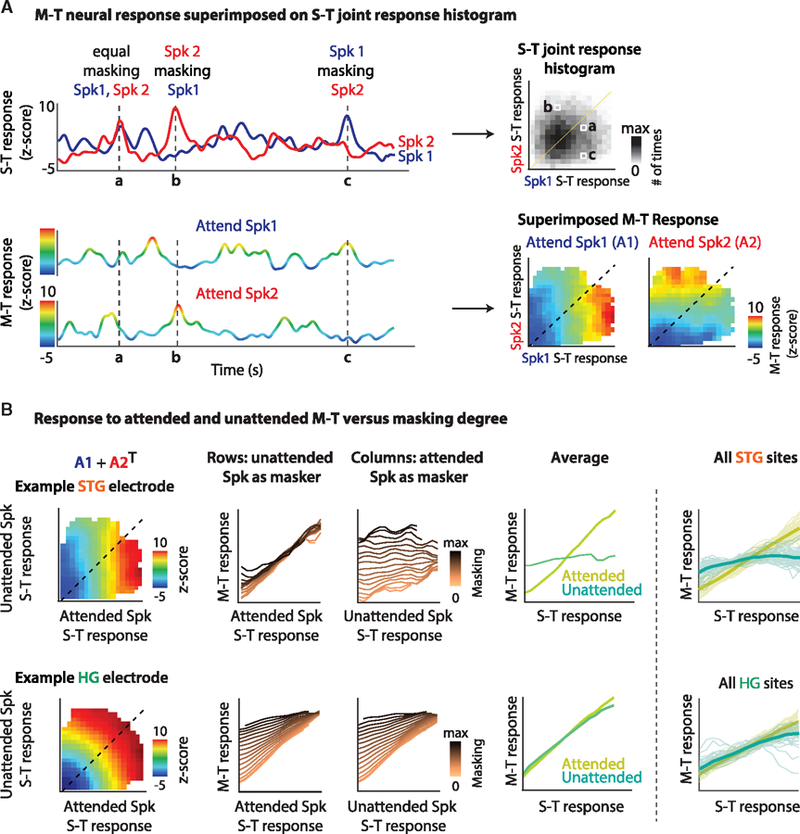
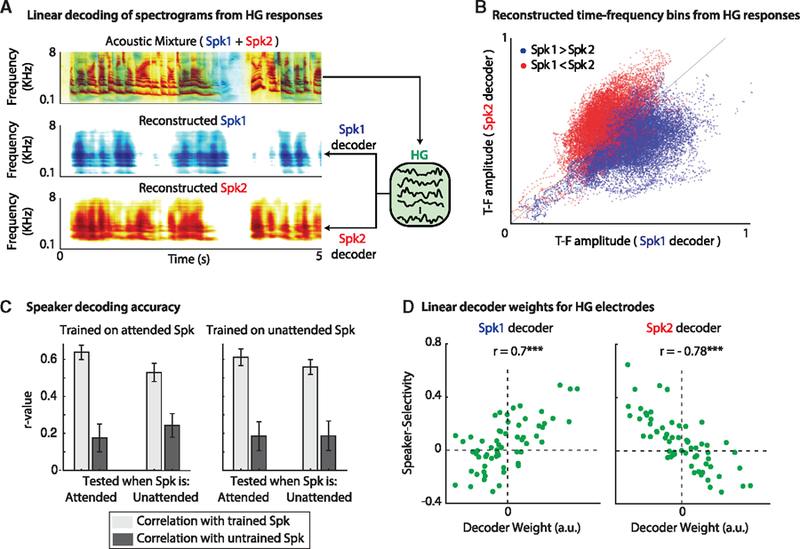
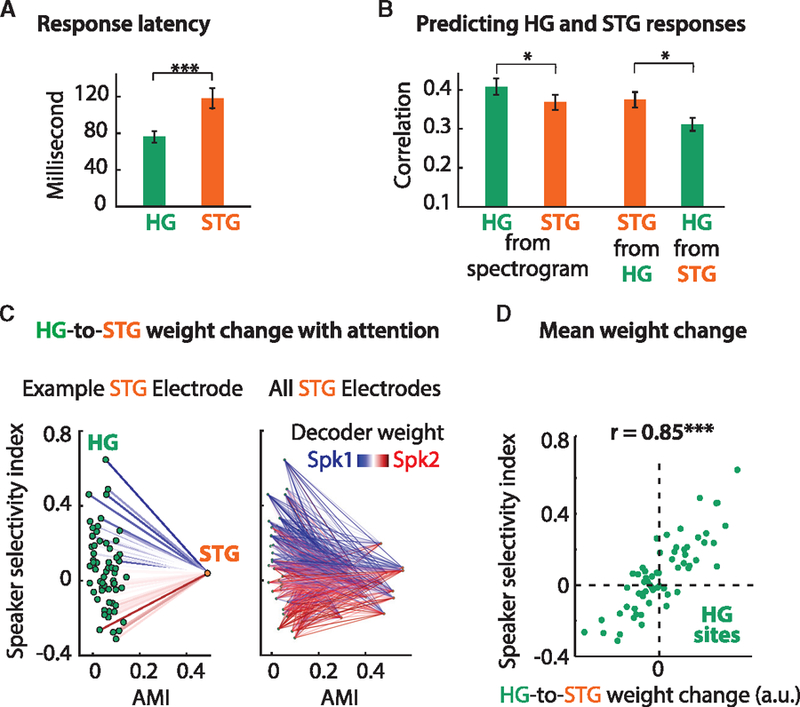
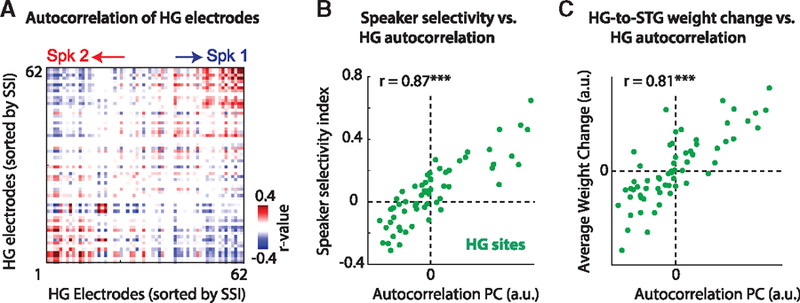
Comment in
-
The Dialog of Primary and Non-primary Auditory Cortex at the 'Cocktail Party'.Neuron. 2019 Dec 18;104(6):1029-1031. doi: 10.1016/j.neuron.2019.11.031. Neuron. 2019. PMID: 31951534
Similar articles
-
Selective cortical representation of attended speaker in multi-talker speech perception.Nature. 2012 May 10;485(7397):233-6. doi: 10.1038/nature11020. Nature. 2012. PMID: 22522927 Free PMC article. Clinical Trial.
-
Noise-robust cortical tracking of attended speech in real-world acoustic scenes.Neuroimage. 2017 Aug 1;156:435-444. doi: 10.1016/j.neuroimage.2017.04.026. Epub 2017 Apr 13. Neuroimage. 2017. PMID: 28412441
-
Cortical Representations of Speech in a Multitalker Auditory Scene.J Neurosci. 2017 Sep 20;37(38):9189-9196. doi: 10.1523/JNEUROSCI.0938-17.2017. Epub 2017 Aug 18. J Neurosci. 2017. PMID: 28821680 Free PMC article.
-
The encoding of auditory objects in auditory cortex: insights from magnetoencephalography.Int J Psychophysiol. 2015 Feb;95(2):184-90. doi: 10.1016/j.ijpsycho.2014.05.005. Epub 2014 May 16. Int J Psychophysiol. 2015. PMID: 24841996 Free PMC article. Review.
-
Neural Encoding of Attended Continuous Speech under Different Types of Interference.J Cogn Neurosci. 2018 Nov;30(11):1606-1619. doi: 10.1162/jocn_a_01303. Epub 2018 Jul 13. J Cogn Neurosci. 2018. PMID: 30004849 Review.
Cited by
-
Neural speech restoration at the cocktail party: Auditory cortex recovers masked speech of both attended and ignored speakers.PLoS Biol. 2020 Oct 22;18(10):e3000883. doi: 10.1371/journal.pbio.3000883. eCollection 2020 Oct. PLoS Biol. 2020. PMID: 33091003 Free PMC article.
-
Lemniscal Corticothalamic Feedback in Auditory Scene Analysis.Front Neurosci. 2021 Aug 19;15:723893. doi: 10.3389/fnins.2021.723893. eCollection 2021. Front Neurosci. 2021. PMID: 34489635 Free PMC article. Review.
-
Binding the Acoustic Features of an Auditory Source through Temporal Coherence.Cereb Cortex Commun. 2021 Oct 6;2(4):tgab060. doi: 10.1093/texcom/tgab060. eCollection 2021. Cereb Cortex Commun. 2021. PMID: 34746791 Free PMC article.
-
Envelope reconstruction of speech and music highlights stronger tracking of speech at low frequencies.PLoS Comput Biol. 2021 Sep 17;17(9):e1009358. doi: 10.1371/journal.pcbi.1009358. eCollection 2021 Sep. PLoS Comput Biol. 2021. PMID: 34534211 Free PMC article.
-
Attention to audiovisual speech shapes neural processing through feedback-feedforward loops between different nodes of the speech network.PLoS Biol. 2024 Mar 11;22(3):e3002534. doi: 10.1371/journal.pbio.3002534. eCollection 2024 Mar. PLoS Biol. 2024. PMID: 38466713 Free PMC article.
References
-
- Bidelman GM, Moreno S, and Alain C (2013). Tracing the emergence of categorical speech perception in the human auditory system. Neuroimage 79, 201–212. - PubMed
Publication types
MeSH terms
Grants and funding
LinkOut - more resources
Full Text Sources
Other Literature Sources
