

Radiomics with artificial intelligence: a practical guide for beginners
- PMID: 31650960
- PMCID: PMC6837295
- DOI: 10.5152/dir.2019.19321
Radiomics with artificial intelligence: a practical guide for beginners
Abstract
Radiomics is a relatively new word for the field of radiology, meaning the extraction of a high number of quantitative features from medical images. Artificial intelligence (AI) is broadly a set of advanced computational algorithms that basically learn the patterns in the data provided to make predictions on unseen data sets. Radiomics can be coupled with AI because of its better capability of handling a massive amount of data compared with the traditional statistical methods. Together, the primary purpose of these fields is to extract and analyze as much and meaningful hidden quantitative data as possible to be used in decision support. Nowadays, both radiomics and AI have been getting attention for their remarkable success in various radiological tasks, which has been met with anxiety by most of the radiologists due to the fear of replacement by intelligent machines. Considering ever-developing advances in computational power and availability of large data sets, the marriage of humans and machines in future clinical practice seems inevitable. Therefore, regardless of their feelings, the radiologists should be familiar with these concepts. Our goal in this paper was three-fold: first, to familiarize radiologists with the radiomics and AI; second, to encourage the radiologists to get involved in these ever-developing fields; and, third, to provide a set of recommendations for good practice in design and assessment of future works.
Conflict of interest statement
The authors declared no conflicts of interest.
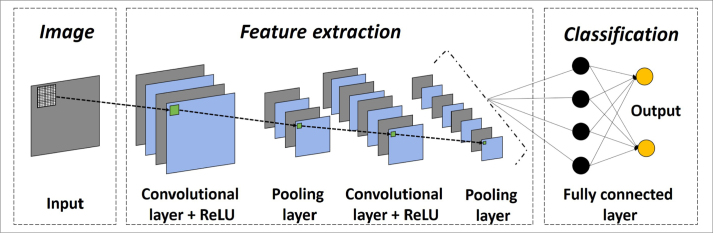
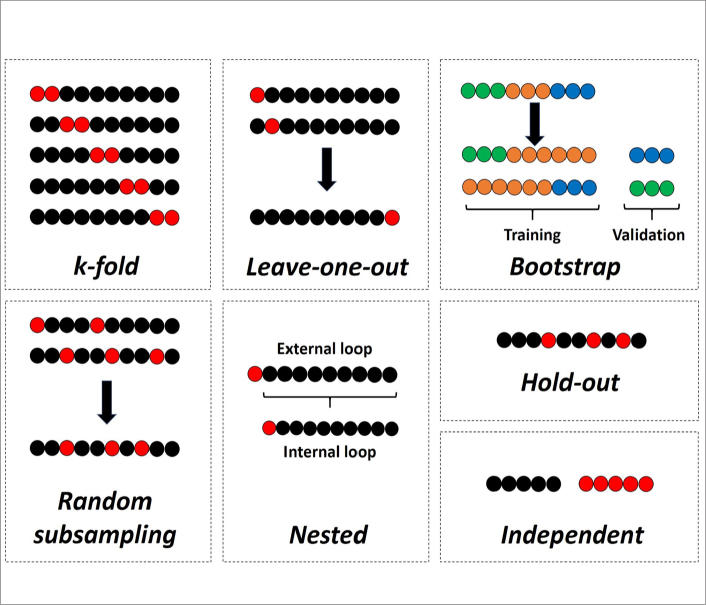
Figures

References
Publication types
MeSH terms
LinkOut - more resources
Full Text Sources
Miscellaneous
