

Cardio-respiratory signal extraction from video camera data for continuous non-contact vital sign monitoring using deep learning
- PMID: 31661680
- PMCID: PMC7655150
- DOI: 10.1088/1361-6579/ab525c
Cardio-respiratory signal extraction from video camera data for continuous non-contact vital sign monitoring using deep learning
Abstract
Non-contact vital sign monitoring enables the estimation of vital signs, such as heart rate, respiratory rate and oxygen saturation (SpO2), by measuring subtle color changes on the skin surface using a video camera. For patients in a hospital ward, the main challenges in the development of continuous and robust non-contact monitoring techniques are the identification of time periods and the segmentation of skin regions of interest (ROIs) from which vital signs can be estimated. We propose a deep learning framework to tackle these challenges.
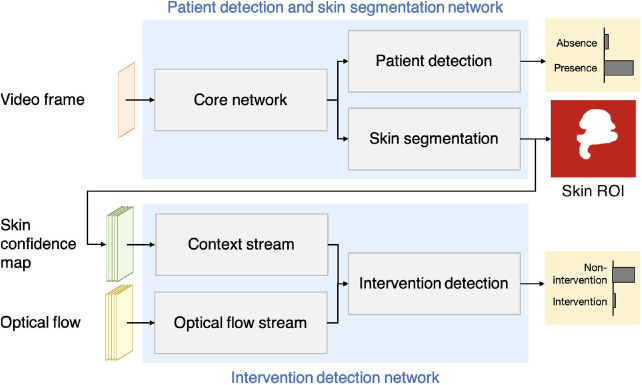
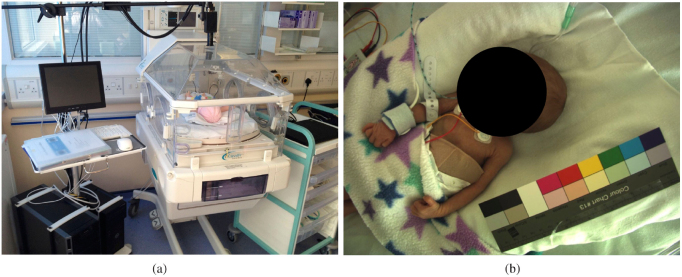
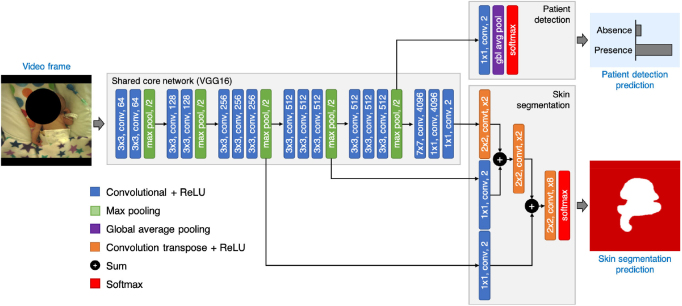
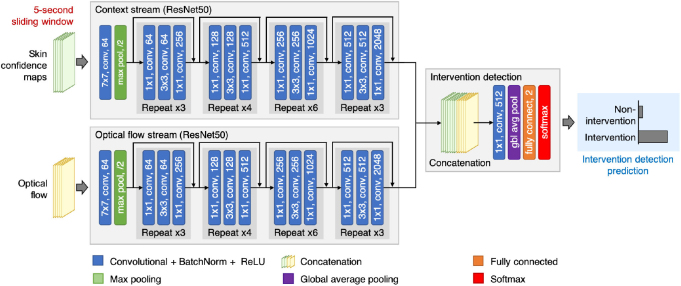
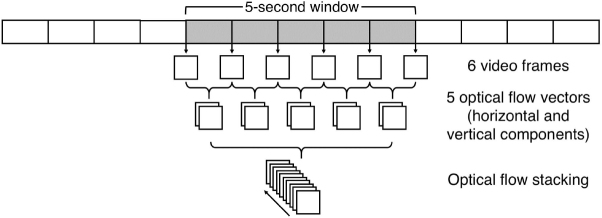
Approach: This paper presents two convolutional neural network (CNN) models. The first network was designed for detecting the presence of a patient and segmenting the patient's skin area. The second network combined the output from the first network with optical flow for identifying time periods of clinical intervention so that these periods can be excluded from the estimation of vital signs. Both networks were trained using video recordings from a clinical study involving 15 pre-term infants conducted in the high dependency area of the neonatal intensive care unit (NICU) of the John Radcliffe Hospital in Oxford, UK.
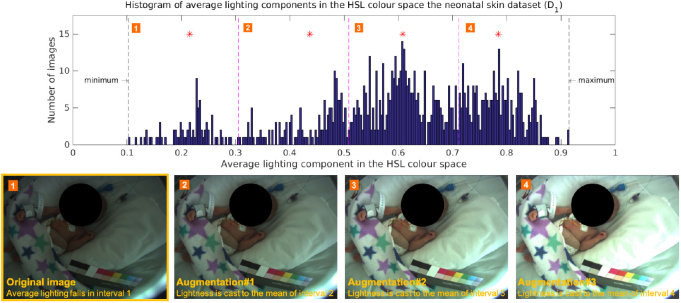
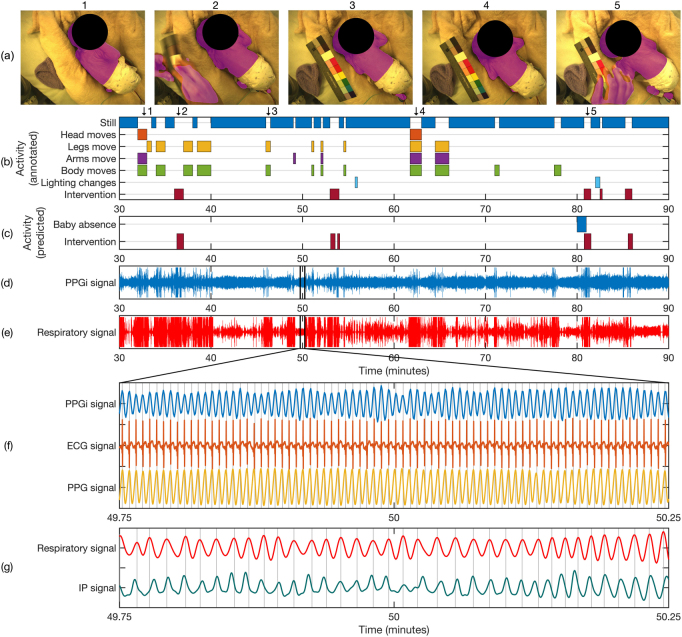
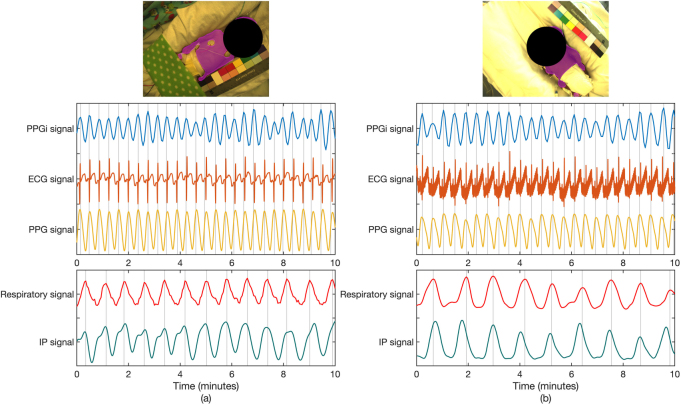
Main results: Our proposed methods achieved an accuracy of 98.8% for patient detection, a mean intersection-over-union (IOU) score of 88.6% for skin segmentation and an accuracy of 94.5% for clinical intervention detection using two-fold cross validation. Our deep learning models produced accurate results and were robust to different skin tones, changes in light conditions, pose variations and different clinical interventions by medical staff and family visitors.
Significance: Our approach allows cardio-respiratory signals to be continuously derived from the patient's skin during which the patient is present and no clinical intervention is undertaken.
Figures


Similar articles
-
Continuous non-contact vital sign monitoring in neonatal intensive care unit.Healthc Technol Lett. 2014 Sep 23;1(3):87-91. doi: 10.1049/htl.2014.0077. eCollection 2014 Sep. Healthc Technol Lett. 2014. PMID: 26609384 Free PMC article.
-
Fast body part segmentation and tracking of neonatal video data using deep learning.Med Biol Eng Comput. 2020 Dec;58(12):3049-3061. doi: 10.1007/s11517-020-02251-4. Epub 2020 Oct 23. Med Biol Eng Comput. 2020. PMID: 33094430 Free PMC article.
-
Remote sensing of vital signs by medical radar time-series signal using cardiac peak extraction and adaptive peak detection algorithm: Performance validation on healthy adults and application to neonatal monitoring at an NICU.Comput Methods Programs Biomed. 2022 Nov;226:107163. doi: 10.1016/j.cmpb.2022.107163. Epub 2022 Sep 27. Comput Methods Programs Biomed. 2022. PMID: 36191355
-
Availability and performance of image-based, non-contact methods of monitoring heart rate, blood pressure, respiratory rate, and oxygen saturation: a systematic review.Physiol Meas. 2019 Jul 3;40(6):06TR01. doi: 10.1088/1361-6579/ab1f1d. Physiol Meas. 2019. PMID: 31051494
-
Human Vital Signs Detection Methods and Potential Using Radars: A Review.Sensors (Basel). 2020 Mar 6;20(5):1454. doi: 10.3390/s20051454. Sensors (Basel). 2020. PMID: 32155838 Free PMC article. Review.
Cited by
-
Novel approaches to capturing and using continuous cardiorespiratory physiological data in hospitalized children.Pediatr Res. 2023 Jan;93(2):396-404. doi: 10.1038/s41390-022-02359-3. Epub 2022 Nov 3. Pediatr Res. 2023. PMID: 36329224 Review.
-
The effect of telemedicine employing telemonitoring instruments on readmissions of patients with heart failure and/or COPD: a systematic review.Front Digit Health. 2024 Sep 25;6:1441334. doi: 10.3389/fdgth.2024.1441334. eCollection 2024. Front Digit Health. 2024. PMID: 39386390 Free PMC article.
-
Depth-Based Intervention Detection in the Neonatal Intensive Care Unit Using Vision Transformers.Sensors (Basel). 2024 Dec 4;24(23):7753. doi: 10.3390/s24237753. Sensors (Basel). 2024. PMID: 39686290 Free PMC article.
-
Deep Learning Methods for Remote Heart Rate Measurement: A Review and Future Research Agenda.Sensors (Basel). 2021 Sep 20;21(18):6296. doi: 10.3390/s21186296. Sensors (Basel). 2021. PMID: 34577503 Free PMC article. Review.
-
Emerging innovations in neonatal monitoring: a comprehensive review of progress and potential for non-contact technologies.Front Pediatr. 2024 Oct 14;12:1442753. doi: 10.3389/fped.2024.1442753. eCollection 2024. Front Pediatr. 2024. PMID: 39494377 Free PMC article. Review.
References
-
- Bianco S, Schettini R. Two new von Kries based chromatic adaptation transforms found by numerical optimization. Color Res. Appl. 2010;35:184–92. doi: 10.1002/col.20573. - DOI
-
- Bishop C M. Pattern Recognition and Machine Learning. 6th edn. New York: Springer; 2006.
-
- Breiman L. Random Forests. Mach. Learn. 2001;45:5–32. doi: 10.1023/A:1010933404324. - DOI
-
- Brox T, Bruhn A, Papenberg N, Weickert J. High accuracy optical flow estimation based on a theory for warping. Proc. European Conf. on Computer Vision; 2004. pp. pp 25–36. - DOI
Publication types
MeSH terms
Grants and funding
LinkOut - more resources
Full Text Sources
Other Literature Sources
Medical