

STATegra, a comprehensive multi-omics dataset of B-cell differentiation in mouse
- PMID: 31672995
- PMCID: PMC6823427
- DOI: 10.1038/s41597-019-0202-7
STATegra, a comprehensive multi-omics dataset of B-cell differentiation in mouse
Abstract
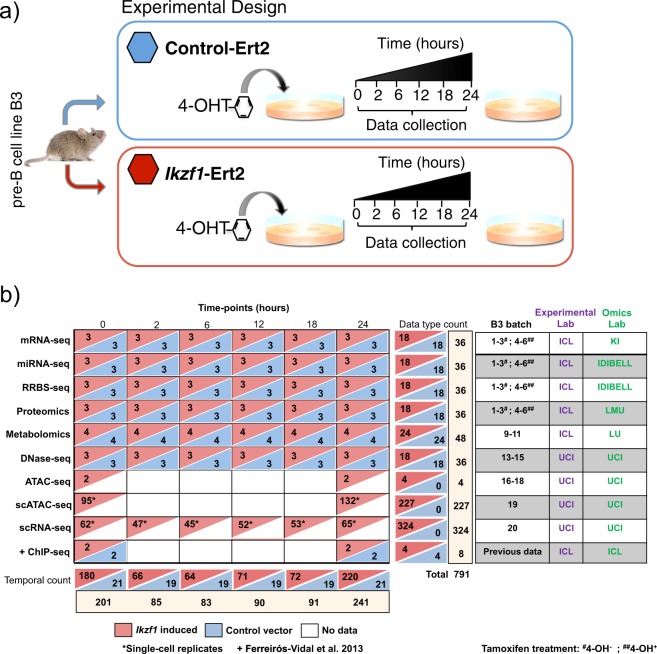
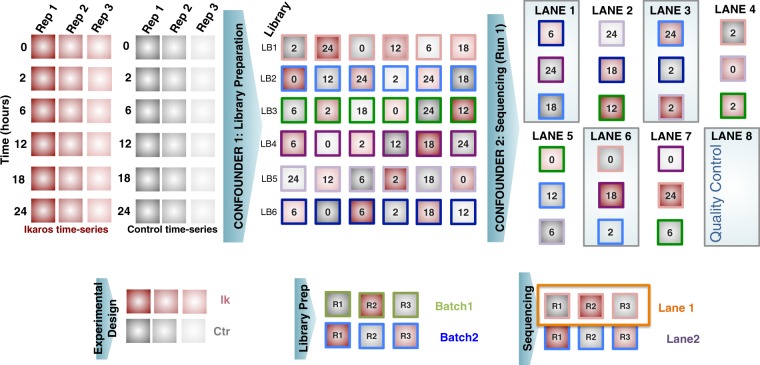
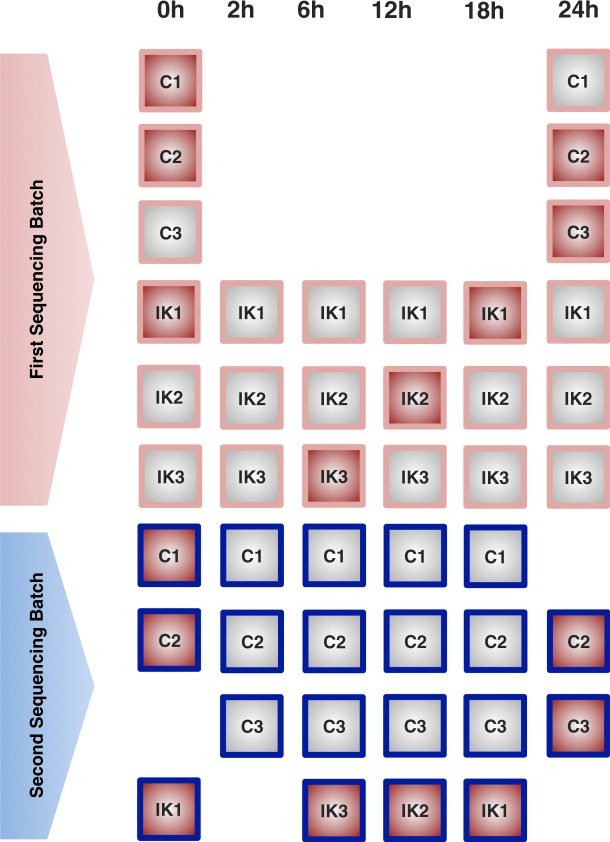
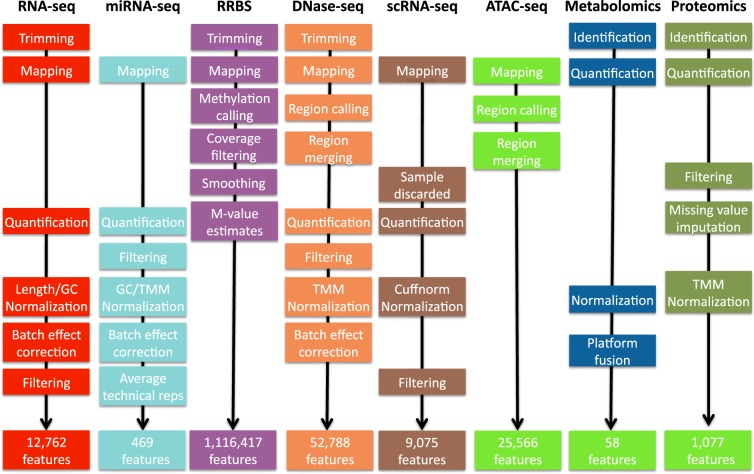
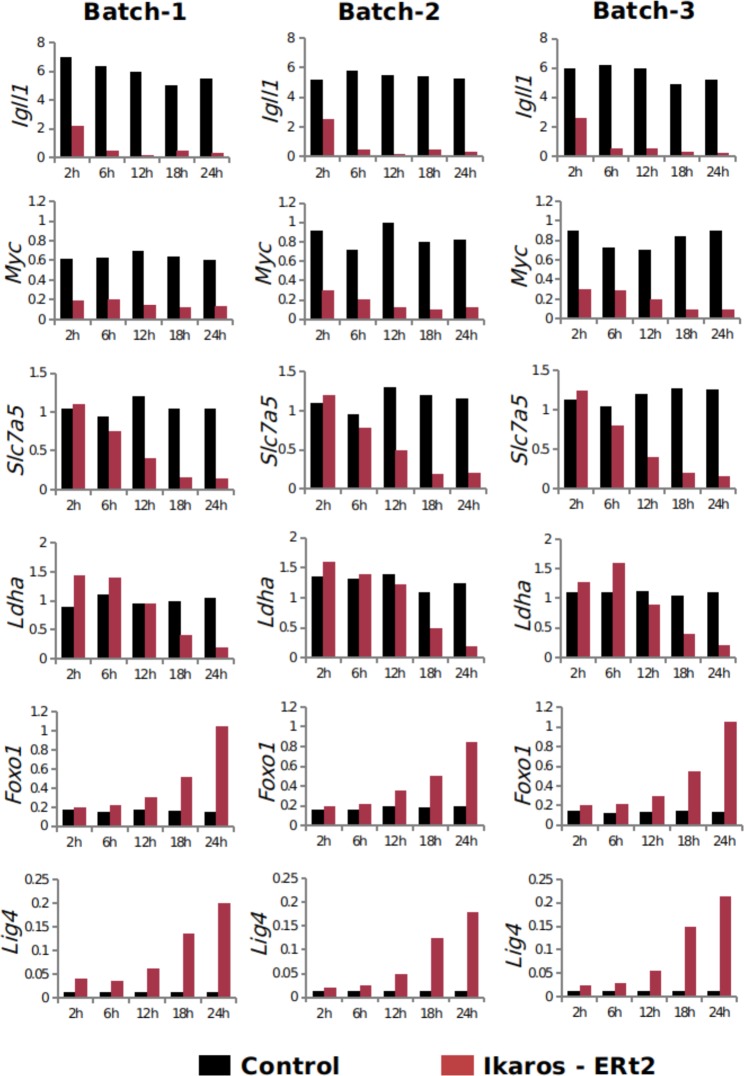
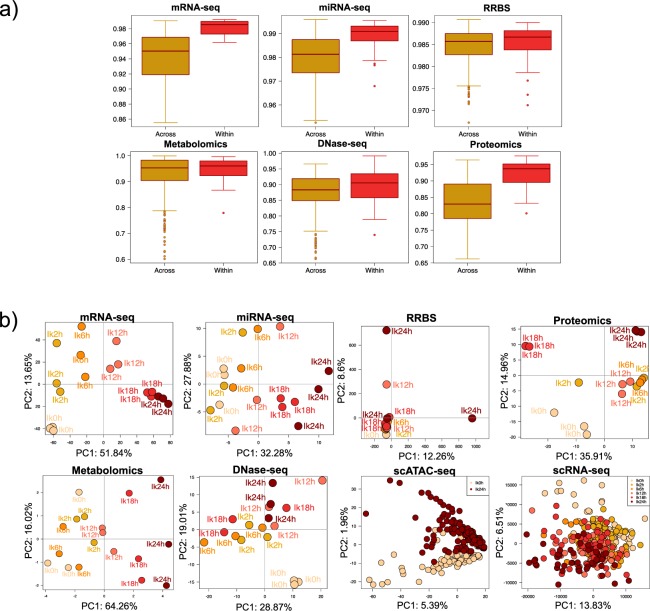
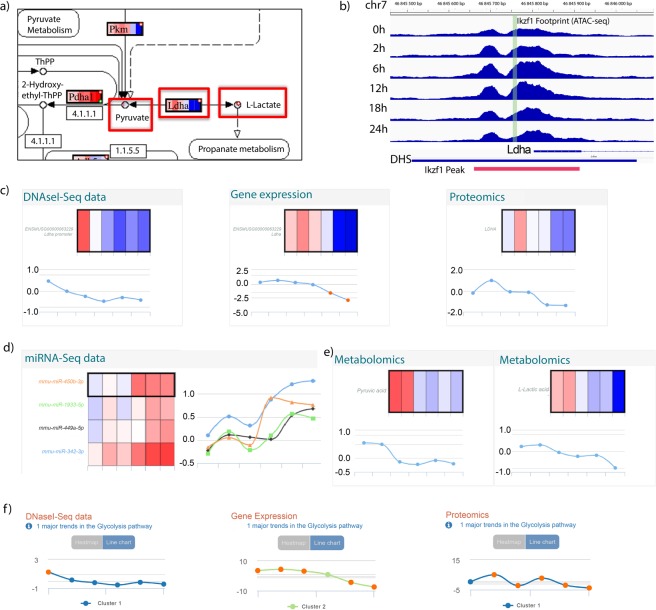
Multi-omics approaches use a diversity of high-throughput technologies to profile the different molecular layers of living cells. Ideally, the integration of this information should result in comprehensive systems models of cellular physiology and regulation. However, most multi-omics projects still include a limited number of molecular assays and there have been very few multi-omic studies that evaluate dynamic processes such as cellular growth, development and adaptation. Hence, we lack formal analysis methods and comprehensive multi-omics datasets that can be leveraged to develop true multi-layered models for dynamic cellular systems. Here we present the STATegra multi-omics dataset that combines measurements from up to 10 different omics technologies applied to the same biological system, namely the well-studied mouse pre-B-cell differentiation. STATegra includes high-throughput measurements of chromatin structure, gene expression, proteomics and metabolomics, and it is complemented with single-cell data. To our knowledge, the STATegra collection is the most diverse multi-omics dataset describing a dynamic biological system.
Conflict of interest statement
The authors declare no competing interests.
Figures
References
Publication types
MeSH terms
Grants and funding
LinkOut - more resources
Full Text Sources
Molecular Biology Databases
