

Learning optimal decisions with confidence
- PMID: 31732671
- PMCID: PMC6900530
- DOI: 10.1073/pnas.1906787116
Learning optimal decisions with confidence
Abstract
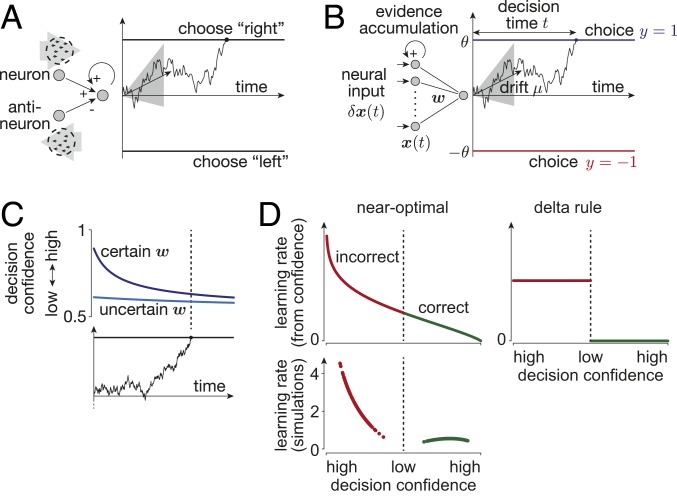
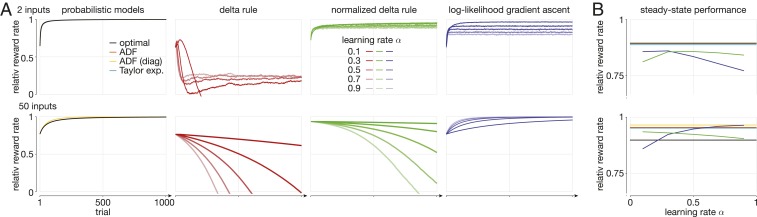
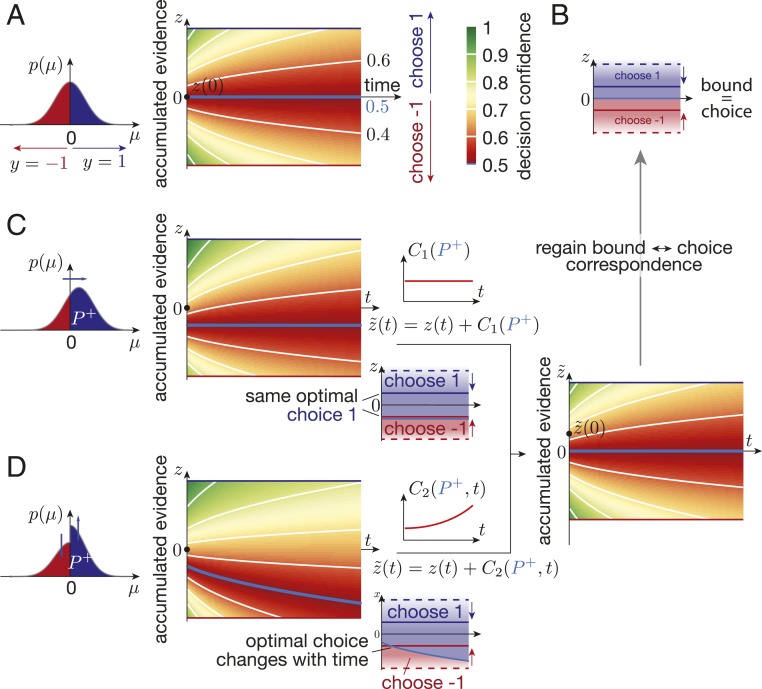
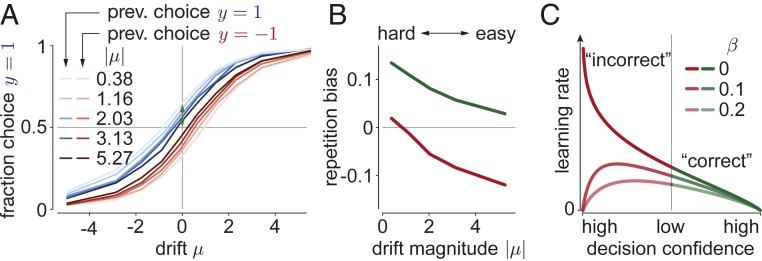
Diffusion decision models (DDMs) are immensely successful models for decision making under uncertainty and time pressure. In the context of perceptual decision making, these models typically start with two input units, organized in a neuron-antineuron pair. In contrast, in the brain, sensory inputs are encoded through the activity of large neuronal populations. Moreover, while DDMs are wired by hand, the nervous system must learn the weights of the network through trial and error. There is currently no normative theory of learning in DDMs and therefore no theory of how decision makers could learn to make optimal decisions in this context. Here, we derive such a rule for learning a near-optimal linear combination of DDM inputs based on trial-by-trial feedback. The rule is Bayesian in the sense that it learns not only the mean of the weights but also the uncertainty around this mean in the form of a covariance matrix. In this rule, the rate of learning is proportional (respectively, inversely proportional) to confidence for incorrect (respectively, correct) decisions. Furthermore, we show that, in volatile environments, the rule predicts a bias toward repeating the same choice after correct decisions, with a bias strength that is modulated by the previous choice's difficulty. Finally, we extend our learning rule to cases for which one of the choices is more likely a priori, which provides insights into how such biases modulate the mechanisms leading to optimal decisions in diffusion models.
Keywords: confidence; decision making; diffusion models; optimality.
Conflict of interest statement
The authors declare no competing interest.
Figures
References
-
- Doya K., Ishii S., Pouget A., Rao R. P. N., Bayesian Brain: Probabilistic Approaches to Neural Coding (MIT Press, 2006).
-
- Ratcliff R., A theory of memory retrieval. Psychol. Rev. 85, 59–108 (1978).
-
- Bogacz R., Brown E., Moehlis J., Holmes P., Cohen J. D., The physics of optimal decision making: A formal analysis of models of performance in two-alternative forced-choice tasks. Psychol. Rev. 113, 700–765 (2006). - PubMed
Publication types
MeSH terms
Grants and funding
LinkOut - more resources
Full Text Sources
