

High-throughput phenotyping with electronic medical record data using a common semi-supervised approach (PheCAP)
- PMID: 31748751
- PMCID: PMC7323894
- DOI: 10.1038/s41596-019-0227-6
High-throughput phenotyping with electronic medical record data using a common semi-supervised approach (PheCAP)
Abstract
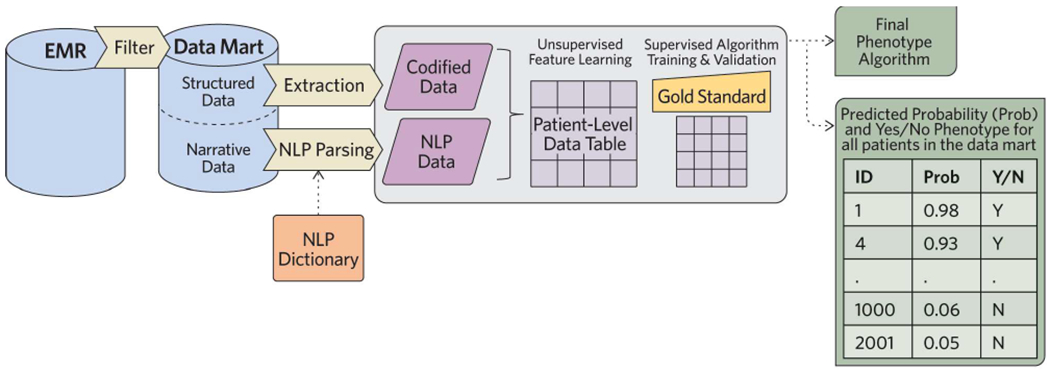
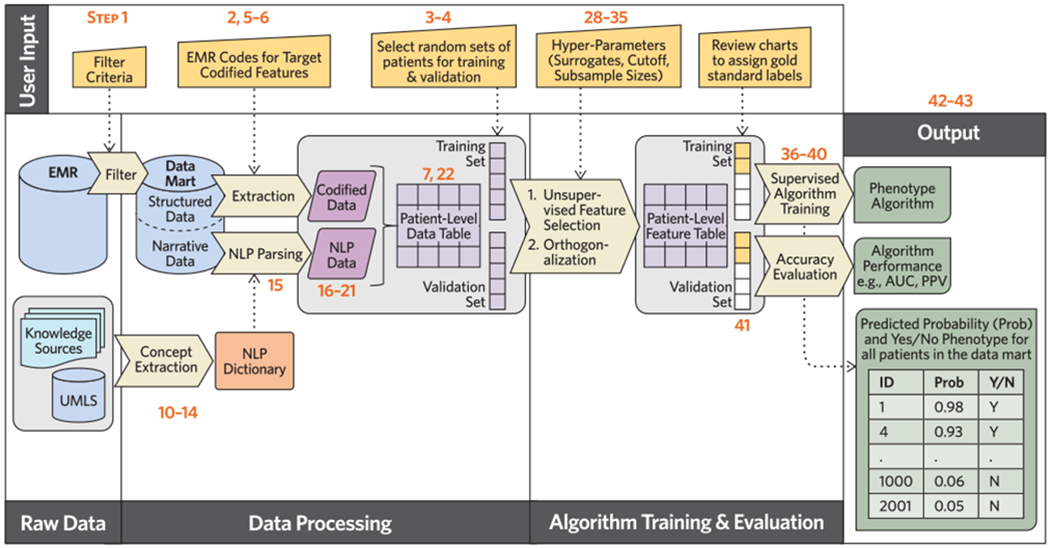
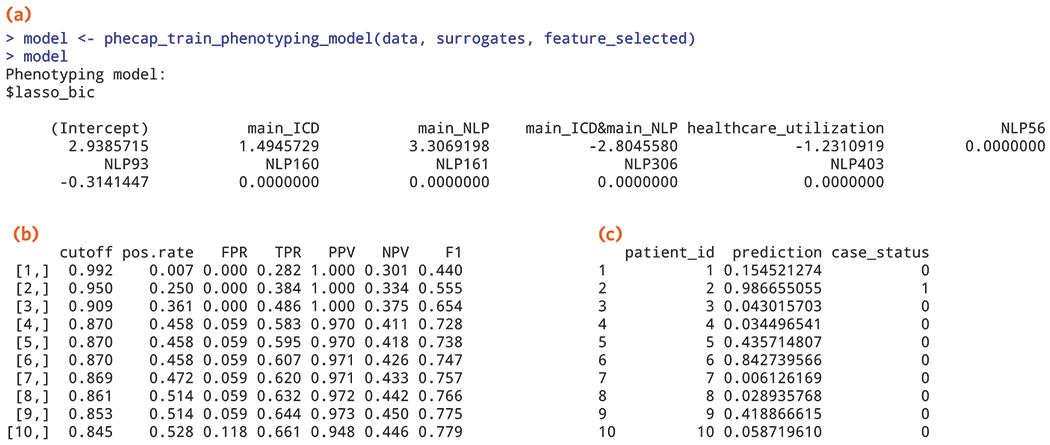
Phenotypes are the foundation for clinical and genetic studies of disease risk and outcomes. The growth of biobanks linked to electronic medical record (EMR) data has both facilitated and increased the demand for efficient, accurate, and robust approaches for phenotyping millions of patients. Challenges to phenotyping with EMR data include variation in the accuracy of codes, as well as the high level of manual input required to identify features for the algorithm and to obtain gold standard labels. To address these challenges, we developed PheCAP, a high-throughput semi-supervised phenotyping pipeline. PheCAP begins with data from the EMR, including structured data and information extracted from the narrative notes using natural language processing (NLP). The standardized steps integrate automated procedures, which reduce the level of manual input, and machine learning approaches for algorithm training. PheCAP itself can be executed in 1-2 d if all data are available; however, the timing is largely dependent on the chart review stage, which typically requires at least 2 weeks. The final products of PheCAP include a phenotype algorithm, the probability of the phenotype for all patients, and a phenotype classification (yes or no).
Conflict of interest statement
COMPETING INTERESTS
RMP is employed at Celgene, however his contributions to the protocol were performed while at Brigham and Women’s Hospital. The remaining authors declare that they have no competing financial and non-financial interests.
Figures




References
Publication types
MeSH terms
Grants and funding
LinkOut - more resources
Full Text Sources
Other Literature Sources
