

Applications of Deep-Learning in Exploiting Large-Scale and Heterogeneous Compound Data in Industrial Pharmaceutical Research
- PMID: 31749705
- PMCID: PMC6848277
- DOI: 10.3389/fphar.2019.01303
Applications of Deep-Learning in Exploiting Large-Scale and Heterogeneous Compound Data in Industrial Pharmaceutical Research
Abstract
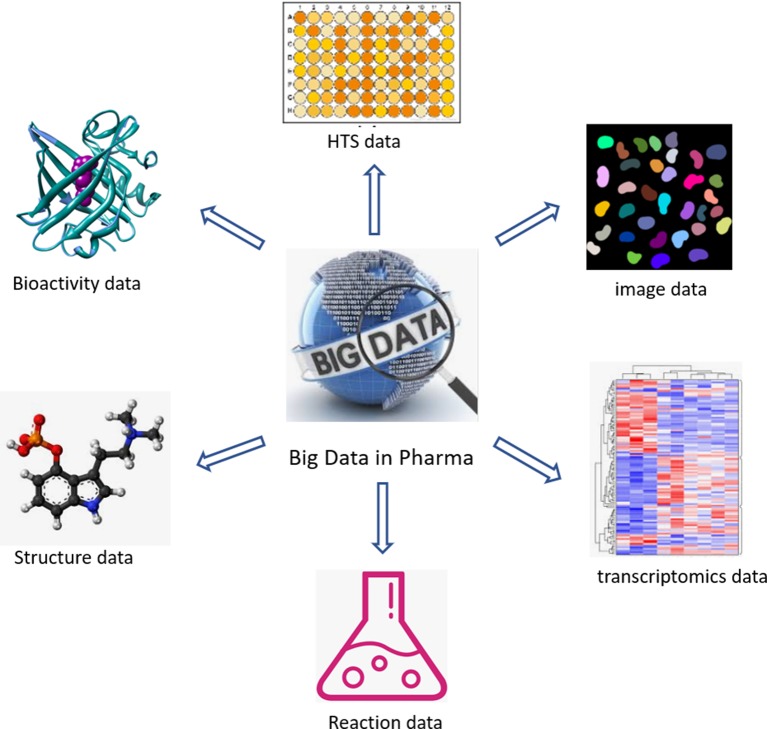
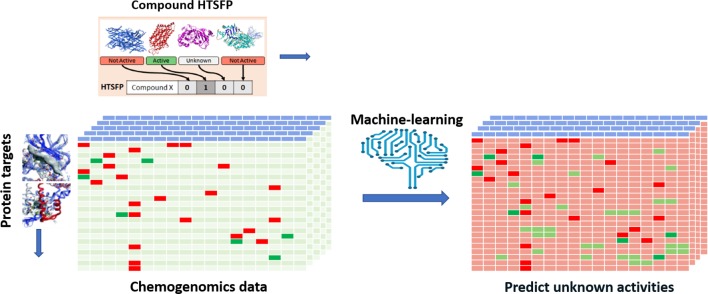
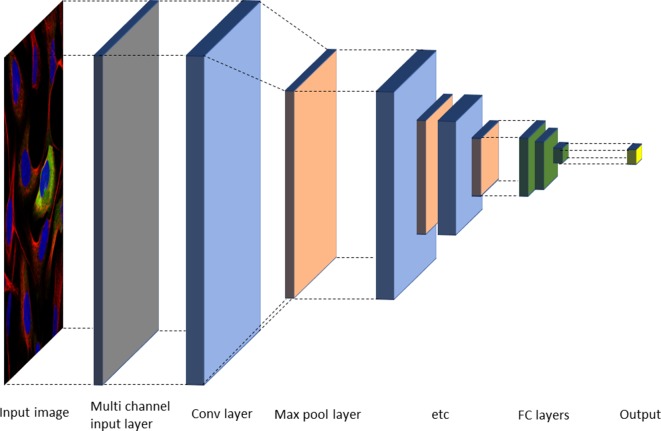
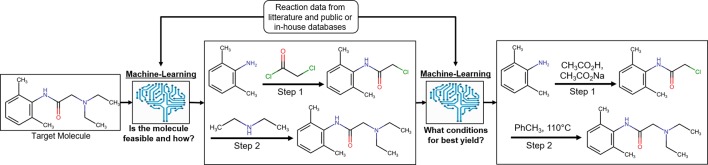
In recent years, the development of high-throughput screening (HTS) technologies and their establishment in an industrialized environment have given scientists the possibility to test millions of molecules and profile them against a multitude of biological targets in a short period of time, generating data in a much faster pace and with a higher quality than before. Besides the structure activity data from traditional bioassays, more complex assays such as transcriptomics profiling or imaging have also been established as routine profiling experiments thanks to the advancement of Next Generation Sequencing or automated microscopy technologies. In industrial pharmaceutical research, these technologies are typically established in conjunction with automated platforms in order to enable efficient handling of screening collections of thousands to millions of compounds. To exploit the ever-growing amount of data that are generated by these approaches, computational techniques are constantly evolving. In this regard, artificial intelligence technologies such as deep learning and machine learning methods play a key role in cheminformatics and bio-image analytics fields to address activity prediction, scaffold hopping, de novo molecule design, reaction/retrosynthesis predictions, or high content screening analysis. Herein we summarize the current state of analyzing large-scale compound data in industrial pharmaceutical research and describe the impact it has had on the drug discovery process over the last two decades, with a specific focus on deep-learning technologies.
Keywords: Artificial intelligence; Chemogenomics; Large-scale data; deep learning; pharmaceutical industry.
Copyright © 2019 David, Arús-Pous, Karlsson, Engkvist, Bjerrum, Kogej, Kriegl, Beck and Chen.
Figures
References
-
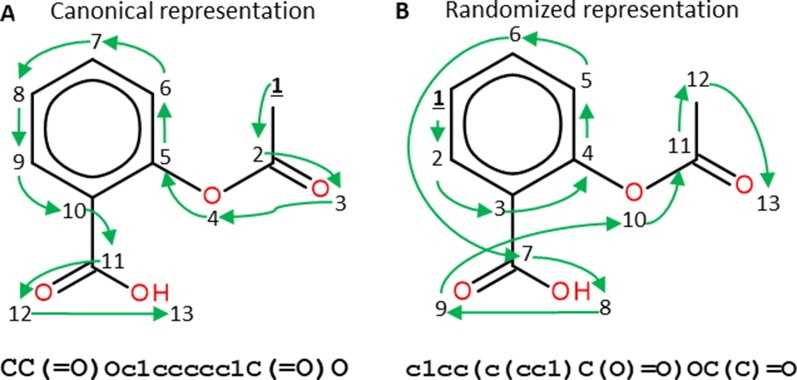
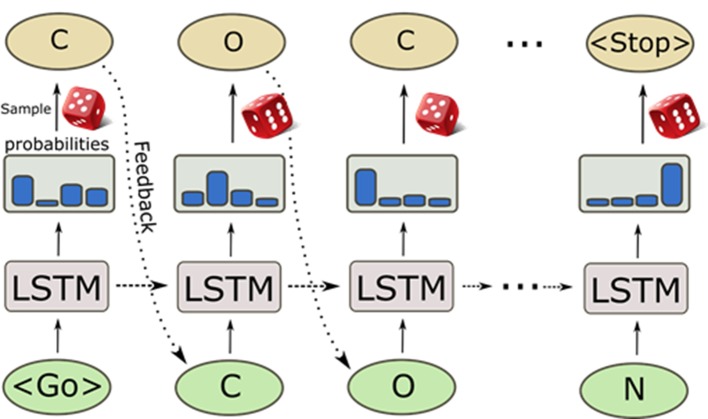
- Arús-Pous J., Johansson S., Ptykhodko O., Bjerrum E. J., Tyrchan C., Reymond J.-L. (2019. b). Randomized SMILES strings improve the quality of molecular generative models. ChemRxiv Prepr. Available at: https://chemrxiv.org/articles/Randomized_SMILES_Strings_Improve_the_Qual... [Accessed July 5, 2019]. 10.26434/chemrxiv.8639942.v2 - DOI - PMC - PubMed
Publication types
LinkOut - more resources
Full Text Sources