

Automated optimized parameters for T-distributed stochastic neighbor embedding improve visualization and analysis of large datasets
- PMID: 31780669
- PMCID: PMC6882880
- DOI: 10.1038/s41467-019-13055-y
Automated optimized parameters for T-distributed stochastic neighbor embedding improve visualization and analysis of large datasets
Abstract
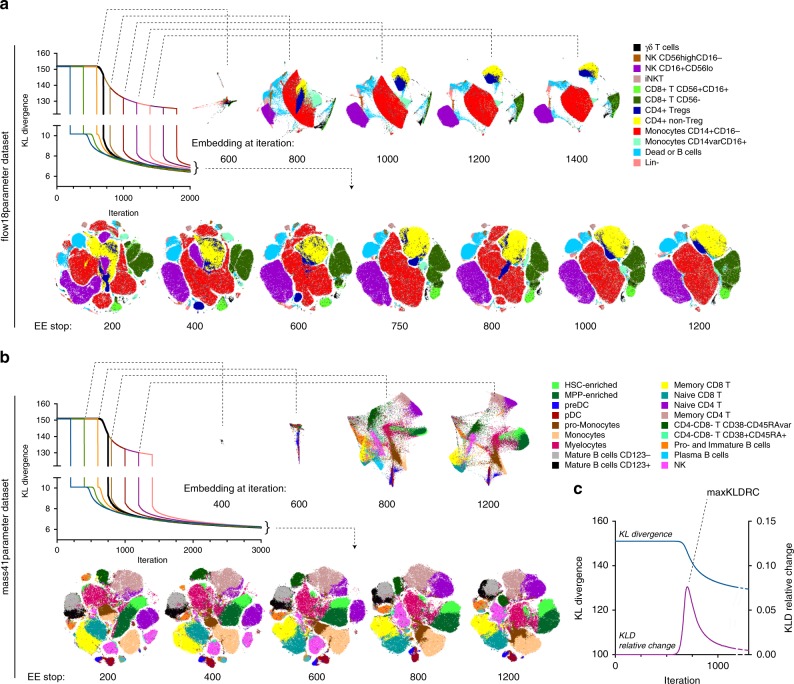
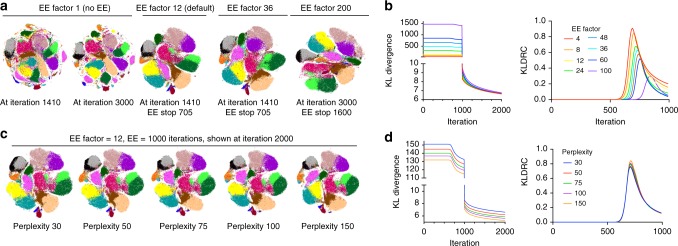
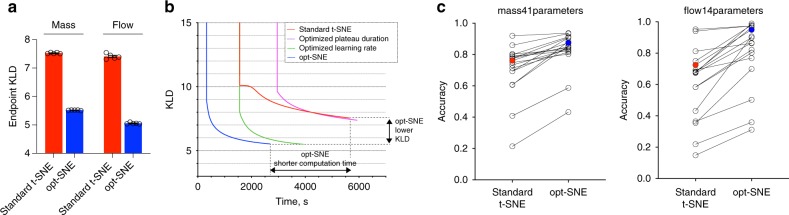
Accurate and comprehensive extraction of information from high-dimensional single cell datasets necessitates faithful visualizations to assess biological populations. A state-of-the-art algorithm for non-linear dimension reduction, t-SNE, requires multiple heuristics and fails to produce clear representations of datasets when millions of cells are projected. We develop opt-SNE, an automated toolkit for t-SNE parameter selection that utilizes Kullback-Leibler divergence evaluation in real time to tailor the early exaggeration and overall number of gradient descent iterations in a dataset-specific manner. The precise calibration of early exaggeration together with opt-SNE adjustment of gradient descent learning rate dramatically improves computation time and enables high-quality visualization of large cytometry and transcriptomics datasets, overcoming limitations of analysis tools with hard-coded parameters that often produce poorly resolved or misleading maps of fluorescent and mass cytometry data. In summary, opt-SNE enables superior data resolution in t-SNE space and thereby more accurate data interpretation.
Conflict of interest statement
C.O.C. is a founder of Omiq, Inc. R.H. and J.S. are employees of Beckton Dickinson (BD); FlowJo is a subsidiary of BD. The remaining authors declare no competing interests.
Figures



References
-
- van der Maaten L, Hinton G. Visualizing data using t-SNE. J. Mach. Learn. Res. 2008;9:85.
-
- van der Maaten L. Accelerating t-SNE using tree-based algorithms. J. Mach. Learn. Res. 2014;15:3221–3245.
MeSH terms
Grants and funding
LinkOut - more resources
Full Text Sources
Other Literature Sources
