

The GenomeAsia 100K Project enables genetic discoveries across Asia
- PMID: 31802016
- PMCID: PMC7054211
- DOI: 10.1038/s41586-019-1793-z
The GenomeAsia 100K Project enables genetic discoveries across Asia
Abstract
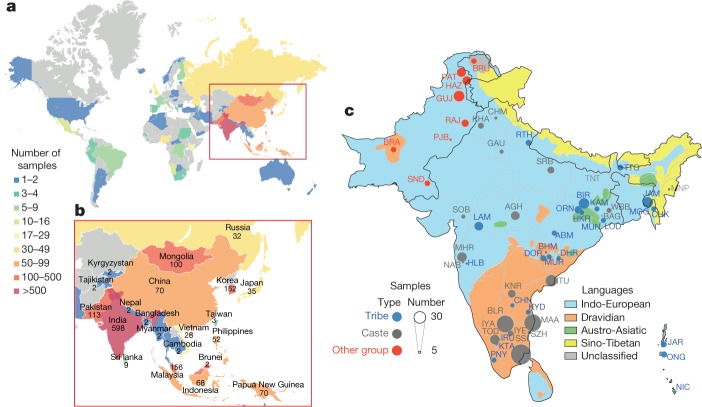
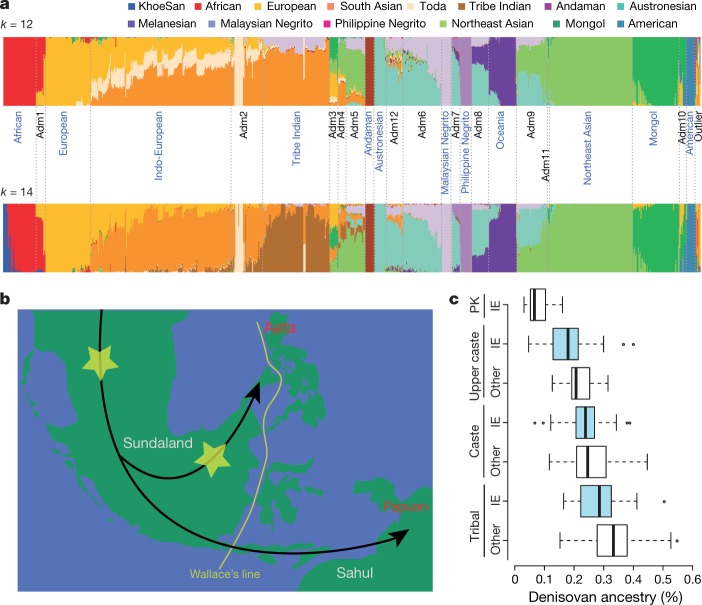
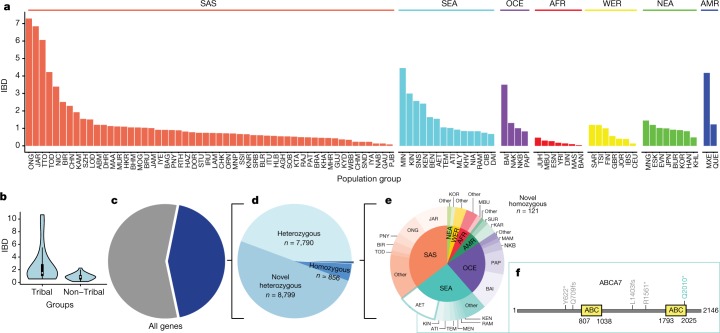
The underrepresentation of non-Europeans in human genetic studies so far has limited the diversity of individuals in genomic datasets and led to reduced medical relevance for a large proportion of the world's population. Population-specific reference genome datasets as well as genome-wide association studies in diverse populations are needed to address this issue. Here we describe the pilot phase of the GenomeAsia 100K Project. This includes a whole-genome sequencing reference dataset from 1,739 individuals of 219 population groups and 64 countries across Asia. We catalogue genetic variation, population structure, disease associations and founder effects. We also explore the use of this dataset in imputation, to facilitate genetic studies in populations across Asia and worldwide.
Conflict of interest statement
A.S.P., E.W.S., S. Seshagiri, T.B., J.T.G., J.T., J. Stinson, Q.B., M.S.S., S.D. and K.S. were employees of Genentech at the time this work was carried out. S. Santhosh, A.V., M. Pratapneni, V. Ramprasad, S.P., R.M., R.G., S.N., S.M., T.S., V.G., J.T.G., M.D. and S.P. are employees of and/or have equity in MedGenome. C.K., J.-S.S. and J.-Y.S. are employees of Macrogen.
Figures



References
-
- The Genome of the Netherlands Consortium Whole-genome sequence variation, population structure and demographic history of the Dutch population. Nat. Genet. 2014;46:818–825. - PubMed
Publication types
MeSH terms
LinkOut - more resources
Full Text Sources
Molecular Biology Databases
