

Predicting the replicability of social science lab experiments
- PMID: 31805105
- PMCID: PMC6894796
- DOI: 10.1371/journal.pone.0225826
Predicting the replicability of social science lab experiments
Abstract
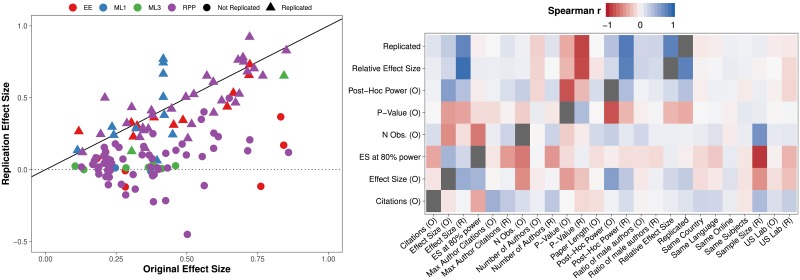
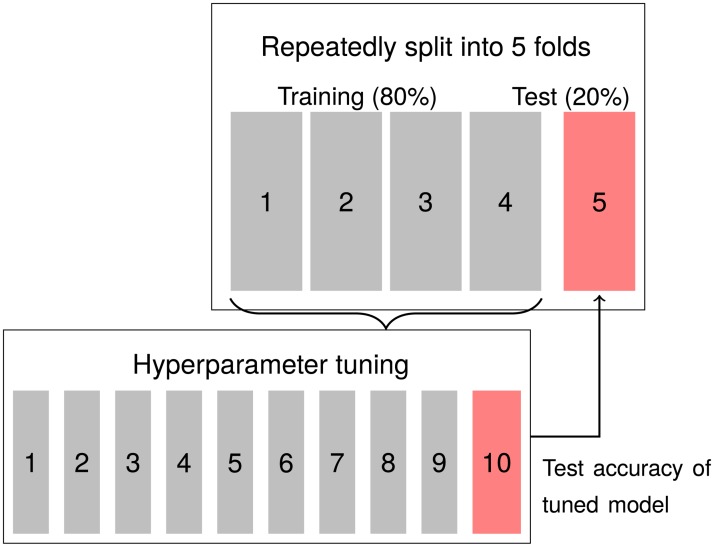
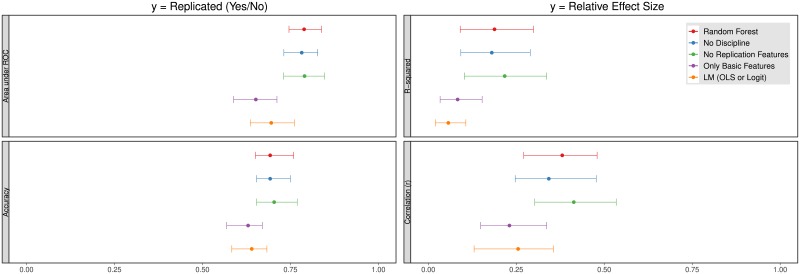
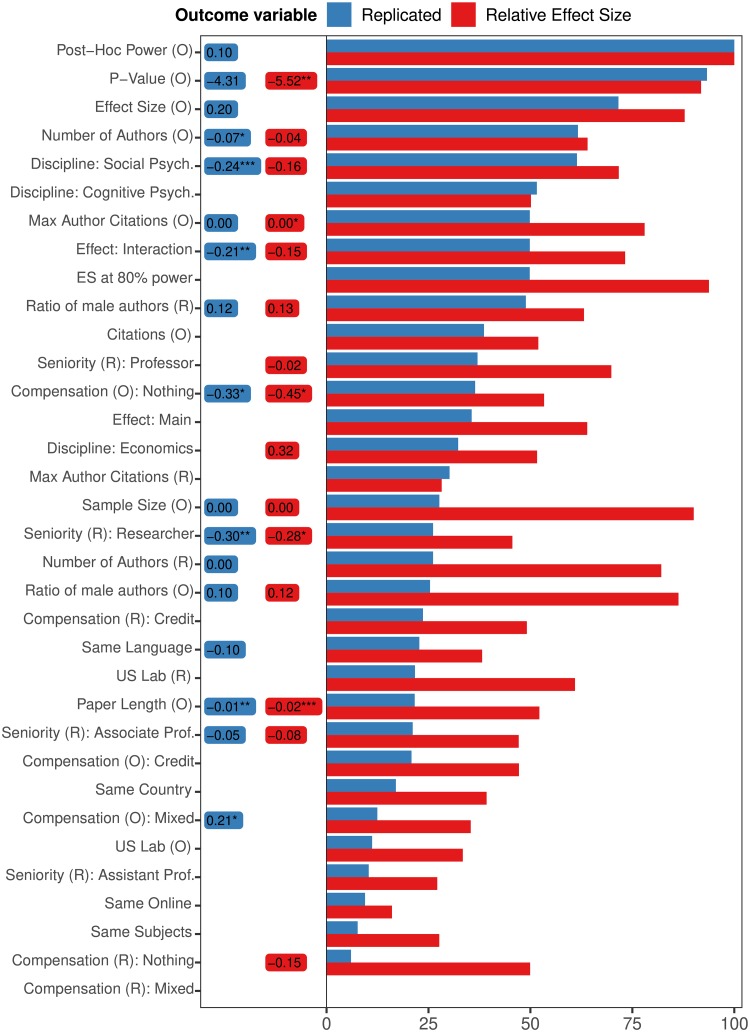
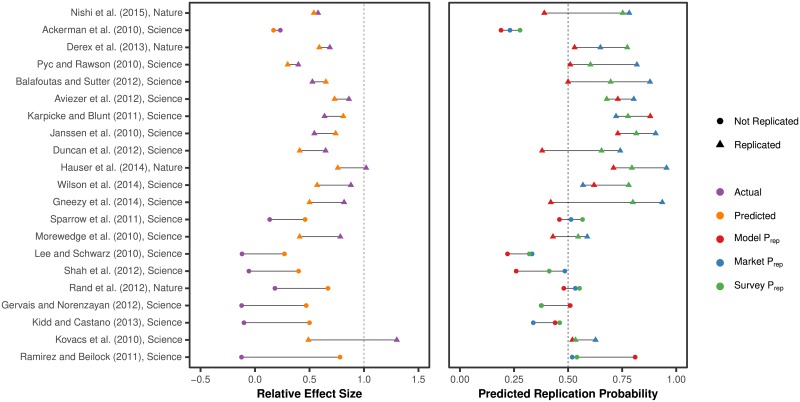
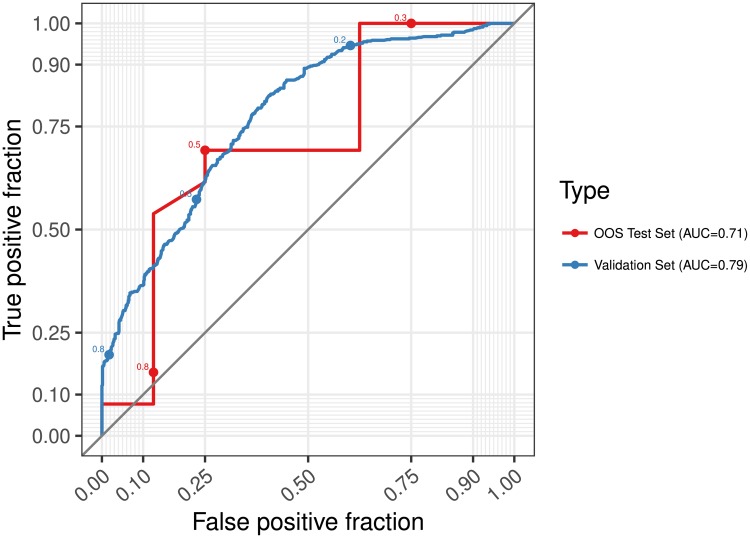
We measure how accurately replication of experimental results can be predicted by black-box statistical models. With data from four large-scale replication projects in experimental psychology and economics, and techniques from machine learning, we train predictive models and study which variables drive predictable replication. The models predicts binary replication with a cross-validated accuracy rate of 70% (AUC of 0.77) and estimates of relative effect sizes with a Spearman ρ of 0.38. The accuracy level is similar to market-aggregated beliefs of peer scientists [1, 2]. The predictive power is validated in a pre-registered out of sample test of the outcome of [3], where 71% (AUC of 0.73) of replications are predicted correctly and effect size correlations amount to ρ = 0.25. Basic features such as the sample and effect sizes in original papers, and whether reported effects are single-variable main effects or two-variable interactions, are predictive of successful replication. The models presented in this paper are simple tools to produce cheap, prognostic replicability metrics. These models could be useful in institutionalizing the process of evaluation of new findings and guiding resources to those direct replications that are likely to be most informative.
Conflict of interest statement
The authors have declared that no competing interests exist.
Figures
References
Publication types
MeSH terms
LinkOut - more resources
Full Text Sources
Other Literature Sources
Miscellaneous
